 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Free Dynamic Regret for Unconstrained Linear Bandits
Mar 26, 2026We study dynamic regret minimization in unconstrained adversarial linear bandit problems. In this setting, a learner must minimize the cumulative loss relative to an arbitrary sequence of comparators $\boldsymbol{u}_1,\ldots,\boldsymbol{u}_T$ in $\mathbb{R}^d$, but receives only point-evaluation feedback on each round. We provide a simple approach to combining the guarantees of several bandit algorithms, allowing us to optimally adapt to the number of switches $S_T = \sum_t\mathbb{I}\{\boldsymbol{u}_t \neq \boldsymbol{u}_{t-1}\}$ of an arbitrary comparator sequence. In particular, we provide the first algorithm for linear bandits achieving the optimal regret guarantee of order $\mathcal{O}\big(\sqrt{d(1+S_T) T}\big)$ up to poly-logarithmic terms without prior knowledge of $S_T$, thus resolving a long-standing open problem.
Bandits with Abstention under Expert Advice
Feb 22, 2024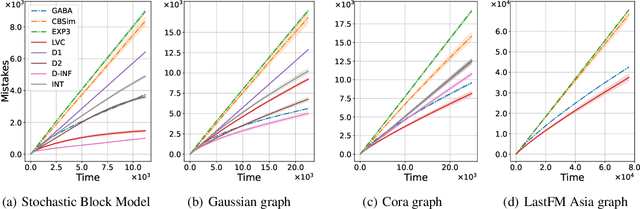
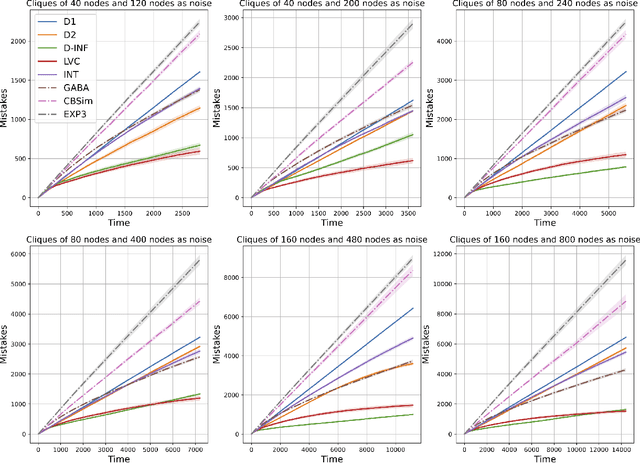
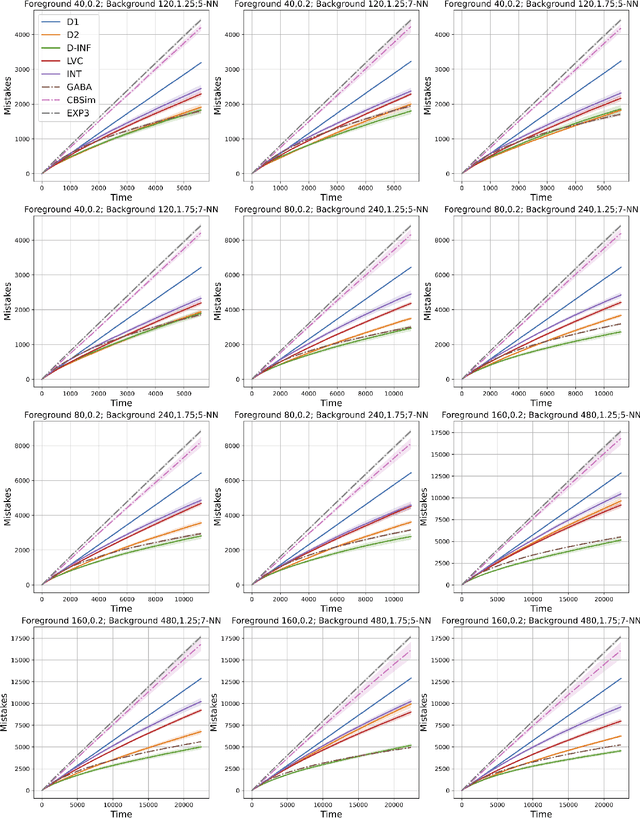
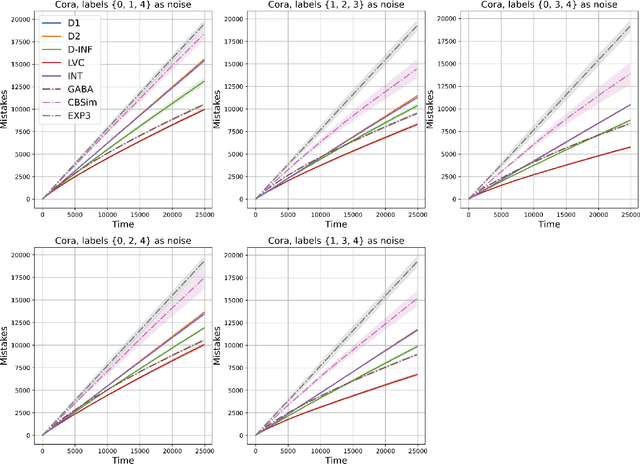
We study the classic problem of prediction with expert advice under bandit feedback. Our model assumes that one action, corresponding to the learner's abstention from play, has no reward or loss on every trial. We propose the CBA algorithm, which exploits this assumption to obtain reward bounds that can significantly improve those of the classical Exp4 algorithm. We can view our problem as the aggregation of confidence-rated predictors when the learner has the option of abstention from play. Importantly, we are the first to achieve bounds on the expected cumulative reward for general confidence-rated predictors. In the special case of specialists we achieve a novel reward bound, significantly improving previous bounds of SpecialistExp (treating abstention as another action). As an example application, we discuss learning unions of balls in a finite metric space. In this contextual setting, we devise an efficient implementation of CBA, reducing the runtime from quadratic to almost linear in the number of contexts. Preliminary experiments show that CBA improves over existing bandit algorithms.
Best-of-Both-Worlds Algorithms for Linear Contextual Bandits
Dec 24, 2023We study best-of-both-worlds algorithms for $K$-armed linear contextual bandits. Our algorithms deliver near-optimal regret bounds in both the adversarial and stochastic regimes, without prior knowledge about the environment. In the stochastic regime, we achieve the polylogarithmic rate $\frac{(dK)^2\mathrm{poly}\log(dKT)}{\Delta_{\min}}$, where $\Delta_{\min}$ is the minimum suboptimality gap over the $d$-dimensional context space. In the adversarial regime, we obtain either the first-order $\widetilde{O}(dK\sqrt{L^*})$ bound, or the second-order $\widetilde{O}(dK\sqrt{\Lambda^*})$ bound, where $L^*$ is the cumulative loss of the best action and $\Lambda^*$ is a notion of the cumulative second moment for the losses incurred by the algorithm. Moreover, we develop an algorithm based on FTRL with Shannon entropy regularizer that does not require the knowledge of the inverse of the covariance matrix, and achieves a polylogarithmic regret in the stochastic regime while obtaining $\widetilde{O}\big(dK\sqrt{T}\big)$ regret bounds in the adversarial regime.
Sum-max Submodular Bandits
Nov 10, 2023
Many online decision-making problems correspond to maximizing a sequence of submodular functions. In this work, we introduce sum-max functions, a subclass of monotone submodular functions capturing several interesting problems, including best-of-$K$-bandits, combinatorial bandits, and the bandit versions on facility location, $M$-medians, and hitting sets. We show that all functions in this class satisfy a key property that we call pseudo-concavity. This allows us to prove $\big(1 - \frac{1}{e}\big)$-regret bounds for bandit feedback in the nonstochastic setting of the order of $\sqrt{MKT}$ (ignoring log factors), where $T$ is the time horizon and $M$ is a cardinality constraint. This bound, attained by a simple and efficient algorithm, significantly improves on the $\widetilde{O}\big(T^{2/3}\big)$ regret bound for online monotone submodular maximization with bandit feedback.