 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Invariant Fast Convergence in Games
Feb 12, 2026Scale-invariance in games has recently emerged as a widely valued desirable property. Yet, almost all fast convergence guarantees in learning in games require prior knowledge of the utility scale. To address this, we develop learning dynamics that achieve fast convergence while being both scale-free, requiring no prior information about utilities, and scale-invariant, remaining unchanged under positive rescaling of utilities. For two-player zero-sum games, we obtain scale-free and scale-invariant dynamics with external regret bounded by $\tilde{O}(A_{\mathrm{diff}})$, where $A_{\mathrm{diff}}$ is the payoff range, which implies an $\tilde{O}(A_{\mathrm{diff}} / T)$ convergence rate to Nash equilibrium after $T$ rounds. For multiplayer general-sum games with $n$ players and $m$ actions, we obtain scale-free and scale-invariant dynamics with swap regret bounded by $O(U_{\mathrm{max}} \log T)$, where $U_{\mathrm{max}}$ is the range of the utilities, ignoring the dependence on the number of players and actions. This yields an $O(U_{\mathrm{max}} \log T / T)$ convergence rate to correlated equilibrium. Our learning dynamics are based on optimistic follow-the-regularized-leader with an adaptive learning rate that incorporates the squared path length of the opponents' gradient vectors, together with a new stopping-time analysis that exploits negative terms in regret bounds without scale-dependent tuning. For general-sum games, scale-free learning is enabled also by a technique called doubling clipping, which clips observed gradients based on past observations.
Adversarial Learning in Games with Bandit Feedback: Logarithmic Pure-Strategy Maximin Regret
Feb 06, 2026Learning to play zero-sum games is a fundamental problem in game theory and machine learning. While significant progress has been made in minimizing external regret in the self-play settings or with full-information feedback, real-world applications often force learners to play against unknown, arbitrary opponents and restrict learners to bandit feedback where only the payoff of the realized action is observable. In such challenging settings, it is well-known that $Ω(\sqrt{T})$ external regret is unavoidable (where T is the number of rounds). To overcome this barrier, we investigate adversarial learning in zero-sum games under bandit feedback, aiming to minimize the deficit against the maximin pure strategy -- a metric we term Pure-Strategy Maximin Regret. We analyze this problem under two bandit feedback models: uninformed (only the realized reward is revealed) and informed (both the reward and the opponent's action are revealed). For uninformed bandit learning of normal-form games, we show that the Tsallis-INF algorithm achieves $O(c \log T)$ instance-dependent regret with a game-dependent parameter $c$. Crucially, we prove an information-theoretic lower bound showing that the dependence on c is necessary. To overcome this hardness, we turn to the informed setting and introduce Maximin-UCB, which obtains another regret bound of the form $O(c' \log T)$ for a different game-dependent parameter $c'$ that could potentially be much smaller than $c$. Finally, we generalize both results to bilinear games over an arbitrary, large action set, proposing Tsallis-FTRL-SPM and Maximin-LinUCB for the uninformed and informed setting respectively and establishing similar game-dependent logarithmic regret bounds.
Data- and Variance-dependent Regret Bounds for Online Tabular MDPs
Feb 02, 2026This work studies online episodic tabular Markov decision processes (MDPs) with known transitions and develops best-of-both-worlds algorithms that achieve refined data-dependent regret bounds in the adversarial regime and variance-dependent regret bounds in the stochastic regime. We quantify MDP complexity using a first-order quantity and several new data-dependent measures for the adversarial regime, including a second-order quantity and a path-length measure, as well as variance-based measures for the stochastic regime. To adapt to these measures, we develop algorithms based on global optimization and policy optimization, both built on optimistic follow-the-regularized-leader with log-barrier regularization. For global optimization, our algorithms achieve first-order, second-order, and path-length regret bounds in the adversarial regime, and in the stochastic regime, they achieve a variance-aware gap-independent bound and a variance-aware gap-dependent bound that is polylogarithmic in the number of episodes. For policy optimization, our algorithms achieve the same data- and variance-dependent adaptivity, up to a factor of the episode horizon, by exploiting a new optimistic $Q$-function estimator. Finally, we establish regret lower bounds in terms of data-dependent complexity measures for the adversarial regime and a variance measure for the stochastic regime, implying that the regret upper bounds achieved by the global-optimization approach are nearly optimal.
Reinforcement Learning from Adversarial Preferences in Tabular MDPs
Jul 15, 2025
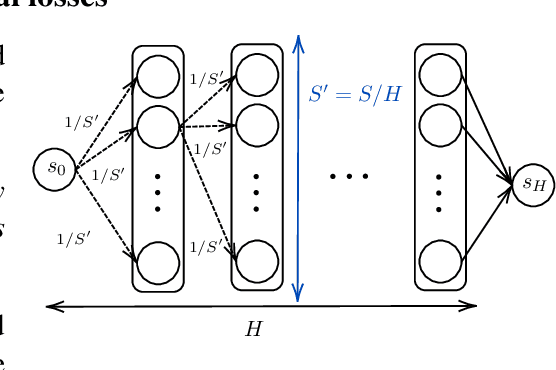
We introduce a new framework of episodic tabular Markov decision processes (MDPs) with adversarial preferences, which we refer to as preference-based MDPs (PbMDPs). Unlike standard episodic MDPs with adversarial losses, where the numerical value of the loss is directly observed, in PbMDPs the learner instead observes preferences between two candidate arms, which represent the choices being compared. In this work, we focus specifically on the setting where the reward functions are determined by Borda scores. We begin by establishing a regret lower bound for PbMDPs with Borda scores. As a preliminary step, we present a simple instance to prove a lower bound of $\Omega(\sqrt{HSAT})$ for episodic MDPs with adversarial losses, where $H$ is the number of steps per episode, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. Leveraging this construction, we then derive a regret lower bound of $\Omega( (H^2 S K)^{1/3} T^{2/3} )$ for PbMDPs with Borda scores, where $K$ is the number of arms. Next, we develop algorithms that achieve a regret bound of order $T^{2/3}$. We first propose a global optimization approach based on online linear optimization over the set of all occupancy measures, achieving a regret bound of $\tilde{O}((H^2 S^2 K)^{1/3} T^{2/3} )$ under known transitions. However, this approach suffers from suboptimal dependence on the potentially large number of states $S$ and computational inefficiency. To address this, we propose a policy optimization algorithm whose regret is roughly bounded by $\tilde{O}( (H^6 S K^5)^{1/3} T^{2/3} )$ under known transitions, and further extend the result to the unknown-transition setting.
Bandit and Delayed Feedback in Online Structured Prediction
Feb 26, 2025Online structured prediction is a task of sequentially predicting outputs with complex structures based on inputs and past observations, encompassing online classification. Recent studies showed that in the full information setup, we can achieve finite bounds on the surrogate regret, i.e., the extra target loss relative to the best possible surrogate loss. In practice, however, full information feedback is often unrealistic as it requires immediate access to the whole structure of complex outputs. Motivated by this, we propose algorithms that work with less demanding feedback, bandit and delayed feedback. For the bandit setting, using a standard inverse-weighted gradient estimator, we achieve a surrogate regret bound of $O(\sqrt{KT})$ for the time horizon $T$ and the size of the output set $K$. However, $K$ can be extremely large when outputs are highly complex, making this result less desirable. To address this, we propose an algorithm that achieves a surrogate regret bound of $O(T^{2/3})$, which is independent of $K$. This is enabled with a carefully designed pseudo-inverse matrix estimator. Furthermore, for the delayed full information feedback setup, we obtain a surrogate regret bound of $O(D^{2/3} T^{1/3})$ for the delay time $D$. We also provide algorithms for the delayed bandit feedback setup. Finally, we numerically evaluate the performance of the proposed algorithms in online classification with bandit feedback.
Instance-Dependent Regret Bounds for Learning Two-Player Zero-Sum Games with Bandit Feedback
Feb 24, 2025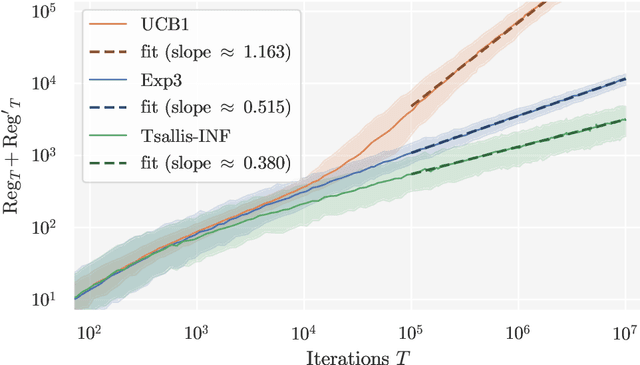
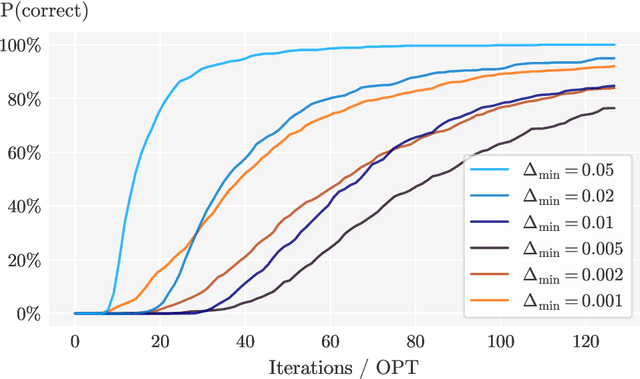
No-regret self-play learning dynamics have become one of the premier ways to solve large-scale games in practice. Accelerating their convergence via improving the regret of the players over the naive $O(\sqrt{T})$ bound after $T$ rounds has been extensively studied in recent years, but almost all studies assume access to exact gradient feedback. We address the question of whether acceleration is possible under bandit feedback only and provide an affirmative answer for two-player zero-sum normal-form games. Specifically, we show that if both players apply the Tsallis-INF algorithm of Zimmert and Seldin (2018, arXiv:1807.07623), then their regret is at most $O(c_1 \log T + \sqrt{c_2 T})$, where $c_1$ and $c_2$ are game-dependent constants that characterize the difficulty of learning -- $c_1$ resembles the complexity of learning a stochastic multi-armed bandit instance and depends inversely on some gap measures, while $c_2$ can be much smaller than the number of actions when the Nash equilibria have a small support or are close to the boundary. In particular, for the case when a pure strategy Nash equilibrium exists, $c_2$ becomes zero, leading to an optimal instance-dependent regret bound as we show. We additionally prove that in this case, our algorithm also enjoys last-iterate convergence and can identify the pure strategy Nash equilibrium with near-optimal sample complexity.
Online Inverse Linear Optimization: Improved Regret Bound, Robustness to Suboptimality, and Toward Tight Regret Analysis
Jan 27, 2025
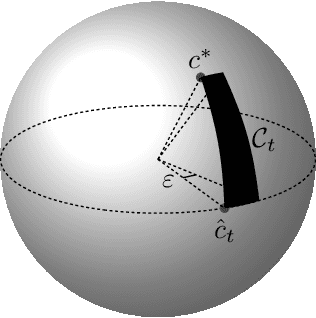
We study an online learning problem where, over $T$ rounds, a learner observes both time-varying sets of feasible actions and an agent's optimal actions, selected by solving linear optimization over the feasible actions. The learner sequentially makes predictions of the agent's underlying linear objective function, and their quality is measured by the regret, the cumulative gap between optimal objective values and those achieved by following the learner's predictions. A seminal work by B\"armann et al. (ICML 2017) showed that online learning methods can be applied to this problem to achieve regret bounds of $O(\sqrt{T})$. Recently, Besbes et al. (COLT 2021, Oper. Res. 2023) significantly improved the result by achieving an $O(n^4\ln T)$ regret bound, where $n$ is the dimension of the ambient space of objective vectors. Their method, based on the ellipsoid method, runs in polynomial time but is inefficient for large $n$ and $T$. In this paper, we obtain an $O(n\ln T)$ regret bound, improving upon the previous bound of $O(n^4\ln T)$ by a factor of $n^3$. Our method is simple and efficient: we apply the online Newton step (ONS) to appropriate exp-concave loss functions. Moreover, for the case where the agent's actions are possibly suboptimal, we establish an $O(n\ln T+\sqrt{\Delta_Tn\ln T})$ regret bound, where $\Delta_T$ is the cumulative suboptimality of the agent's actions. This bound is achieved by using MetaGrad, which runs ONS with $\Theta(\ln T)$ different learning rates in parallel. We also provide a simple instance that implies an $\Omega(n)$ lower bound, showing that our $O(n\ln T)$ bound is tight up to an $O(\ln T)$ factor. This gives rise to a natural question: can the $O(\ln T)$ factor in the upper bound be removed? For the special case of $n=2$, we show that an $O(1)$ regret bound is possible, while we delineate challenges in extending this result to higher dimensions.
Revisiting Online Learning Approach to Inverse Linear Optimization: A Fenchel$-$Young Loss Perspective and Gap-Dependent Regret Analysis
Jan 24, 2025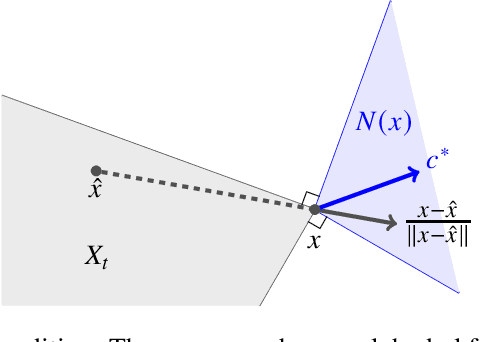
This paper revisits the online learning approach to inverse linear optimization studied by B\"armann et al. (2017), where the goal is to infer an unknown linear objective function of an agent from sequential observations of the agent's input-output pairs. First, we provide a simple understanding of the online learning approach through its connection to online convex optimization of \emph{Fenchel--Young losses}. As a byproduct, we present an offline guarantee on the \emph{suboptimality loss}, which measures how well predicted objectives explain the agent's choices, without assuming the optimality of the agent's choices. Second, assuming that there is a gap between optimal and suboptimal objective values in the agent's decision problems, we obtain an upper bound independent of the time horizon $T$ on the sum of suboptimality and \emph{estimate losses}, where the latter measures the quality of solutions recommended by predicted objectives. Interestingly, our gap-dependent analysis achieves a faster rate than the standard $O(\sqrt{T})$ regret bound by exploiting structures specific to inverse linear optimization, even though neither the loss functions nor their domains enjoy desirable properties, such as strong convexity.
Corrupted Learning Dynamics in Games
Dec 10, 2024

Learning in games is the problem where multiple players interact in a shared environment, each aiming to minimize their own regret, and it is known that an approximate equilibrium can be obtained when all players employ no-regret algorithms. Notably, by adopting optimistic follow-the-regularized-leader (OFTRL), the regret of each player after $T$ rounds is constant in two-player zero-sum games, implying that an equilibrium can be computed at a faster rate of $O(1/T)$. However, this acceleration is limited to the honest regime, where all players fully adhere to the given algorithms. To address this limitation, this paper presents corrupted learning dynamics that adaptively find an equilibrium at a rate dependent on the degree of deviation by each player from the given algorithm's output. First, in two-player zero-sum games, we provide learning dynamics where the external regret of the x-player (and similarly for the y-player) in the corrupted regime is roughly bounded by $O(\log (m_\mathrm{x} m_\mathrm{y}) + \sqrt{C_\mathrm{y}} + C_\mathrm{x})$, which implies a convergence rate of $\tilde{O}((\sqrt{C_\mathrm{y}} + C_\mathrm{x})/T)$ to a Nash equilibrium. Here, $m_\mathrm{x}$ and $m_\mathrm{y}$ are the number of actions of the x- and y-players, respectively, and $C_\mathrm{x}$ and $C_\mathrm{y}$ are the cumulative deviations of the x- and y-players from their given algorithms. Furthermore, we extend our approach to multi-player general-sum games, showing that the swap regret of player $i$ in the corrupted regime is bounded by $O(\log T + \sqrt{\sum_j C_j \log T} + C_i)$, where $C_i$ is the cumulative deviations of player $i$ from the given algorithm. This implies a convergence rate of $O((\log T + \sqrt{\sum_j C_j \log T} + C_i)/T)$ to a correlated equilibrium. Our learning dynamics are agnostic to the corruption levels and are based on OFTRL with new adaptive learning rates.
A Simple and Adaptive Learning Rate for FTRL in Online Learning with Minimax Regret of $Θ$ and its Application to Best-of-Both-Worlds
May 30, 2024
Follow-the-Regularized-Leader (FTRL) is a powerful framework for various online learning problems. By designing its regularizer and learning rate to be adaptive to past observations, FTRL is known to work adaptively to various properties of an underlying environment. However, most existing adaptive learning rates are for online learning problems with a minimax regret of $\Theta(\sqrt{T})$ for the number of rounds $T$, and there are only a few studies on adaptive learning rates for problems with a minimax regret of $\Theta(T^{2/3})$, which include several important problems dealing with indirect feedback. To address this limitation, we establish a new adaptive learning rate framework for problems with a minimax regret of $\Theta(T^{2/3})$. Our learning rate is designed by matching the stability, penalty, and bias terms that naturally appear in regret upper bounds for problems with a minimax regret of $\Theta(T^{2/3})$. As applications of this framework, we consider two major problems dealing with indirect feedback: partial monitoring and graph bandits. We show that FTRL with our learning rate and the Tsallis entropy regularizer improves existing Best-of-Both-Worlds (BOBW) regret upper bounds, which achieve simultaneous optimality in the stochastic and adversarial regimes. The resulting learning rate is surprisingly simple compared to the existing learning rates for BOBW algorithms for problems with a minimax regret of $\Theta(T^{2/3})$.