 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimple Projection-Free Algorithm for Contextual Recommendation with Logarithmic Regret and Robustness
Mar 21, 2026Contextual recommendation is a variant of contextual linear bandits in which the learner observes an (optimal) action rather than a reward scalar. Recently, Sakaue et al. (2025) developed an efficient Online Newton Step (ONS) approach with an $O(d\log T)$ regret bound, where $d$ is the dimension of the action space and $T$ is the time horizon. In this paper, we present a simple algorithm that is more efficient than the ONS-based method while achieving the same regret guarantee. Our core idea is to exploit the improperness inherent in contextual recommendation, leading to an update rule akin to the second-order perceptron from online classification. This removes the Mahalanobis projection step required by ONS, which is often a major computational bottleneck. More importantly, the same algorithm remains robust to possibly suboptimal action feedback, whereas the prior ONS-based method required running multiple ONS learners with different learning rates for this extension. We describe how our method works in general Hilbert spaces (e.g., via kernelization), where eliminating Mahalanobis projections becomes even more beneficial.
From Average Sensitivity to Small-Loss Regret Bounds under Random-Order Model
Feb 10, 2026We study online learning in the random-order model, where the multiset of loss functions is chosen adversarially but revealed in a uniformly random order. Building on the batch-to-online conversion by Dong and Yoshida (2023), we show that if an offline algorithm admits a $(1+\varepsilon)$-approximation guarantee and the effect of $\varepsilon$ on its average sensitivity is characterized by a function $\varphi(\varepsilon)$, then an adaptive choice of $\varepsilon$ yields a small-loss regret bound of $\tilde O(\varphi^{\star}(\mathrm{OPT}_T))$, where $\varphi^{\star}$ is the concave conjugate of $\varphi$, $\mathrm{OPT}_T$ is the offline optimum over $T$ rounds, and $\tilde O$ hides polylogarithmic factors in $T$. Our method requires no regularity assumptions on loss functions, such as smoothness, and can be viewed as a generalization of the AdaGrad-style tuning applied to the approximation parameter $\varepsilon$. Our result recovers and strengthens the $(1+\varepsilon)$-approximate regret bounds of Dong and Yoshida (2023) and yields small-loss regret bounds for online $k$-means clustering, low-rank approximation, and regression. We further apply our framework to online submodular function minimization using $(1\pm\varepsilon)$-cut sparsifiers of submodular hypergraphs, obtaining a small-loss regret bound of $\tilde O(n^{3/4}(1 + \mathrm{OPT}_T^{3/4}))$, where $n$ is the ground-set size. Our approach sheds light on the power of sparsification and related techniques in establishing small-loss regret bounds in the random-order model.
Finite and Corruption-Robust Regret Bounds in Online Inverse Linear Optimization under M-Convex Action Sets
Feb 02, 2026We study online inverse linear optimization, also known as contextual recommendation, where a learner sequentially infers an agent's hidden objective vector from observed optimal actions over feasible sets that change over time. The learner aims to recommend actions that perform well under the agent's true objective, and the performance is measured by the regret, defined as the cumulative gap between the agent's optimal values and those achieved by the learner's recommended actions. Prior work has established a regret bound of $O(d\log T)$, as well as a finite but exponentially large bound of $\exp(O(d\log d))$, where $d$ is the dimension of the optimization problem and $T$ is the time horizon, while a regret lower bound of $Ω(d)$ is known (Gollapudi et al. 2021; Sakaue et al. 2025). Whether a finite regret bound polynomial in $d$ is achievable or not has remained an open question. We partially resolve this by showing that when the feasible sets are M-convex -- a broad class that includes matroids -- a finite regret bound of $O(d\log d)$ is possible. We achieve this by combining a structural characterization of optimal solutions on M-convex sets with a geometric volume argument. Moreover, we extend our approach to adversarially corrupted feedback in up to $C$ rounds. We obtain a regret bound of $O((C+1)d\log d)$ without prior knowledge of $C$, by monitoring directed graphs induced by the observed feedback to detect corruptions adaptively.
Non-Stationary Online Structured Prediction with Surrogate Losses
Oct 08, 2025Online structured prediction, including online classification as a special case, is the task of sequentially predicting labels from input features. Therein the surrogate regret -- the cumulative excess of the target loss (e.g., 0-1 loss) over the surrogate loss (e.g., logistic loss) of the fixed best estimator -- has gained attention, particularly because it often admits a finite bound independent of the time horizon $T$. However, such guarantees break down in non-stationary environments, where every fixed estimator may incur the surrogate loss growing linearly with $T$. We address this by proving a bound of the form $F_T + C(1 + P_T)$ on the cumulative target loss, where $F_T$ is the cumulative surrogate loss of any comparator sequence, $P_T$ is its path length, and $C > 0$ is some constant. This bound depends on $T$ only through $F_T$ and $P_T$, often yielding much stronger guarantees in non-stationary environments. Our core idea is to synthesize the dynamic regret bound of the online gradient descent (OGD) with the technique of exploiting the surrogate gap. Our analysis also sheds light on a new Polyak-style learning rate for OGD, which systematically offers target-loss guarantees and exhibits promising empirical performance. We further extend our approach to a broader class of problems via the convolutional Fenchel--Young loss. Finally, we prove a lower bound showing that the dependence on $F_T$ and $P_T$ is tight.
Bandit and Delayed Feedback in Online Structured Prediction
Feb 26, 2025Online structured prediction is a task of sequentially predicting outputs with complex structures based on inputs and past observations, encompassing online classification. Recent studies showed that in the full information setup, we can achieve finite bounds on the surrogate regret, i.e., the extra target loss relative to the best possible surrogate loss. In practice, however, full information feedback is often unrealistic as it requires immediate access to the whole structure of complex outputs. Motivated by this, we propose algorithms that work with less demanding feedback, bandit and delayed feedback. For the bandit setting, using a standard inverse-weighted gradient estimator, we achieve a surrogate regret bound of $O(\sqrt{KT})$ for the time horizon $T$ and the size of the output set $K$. However, $K$ can be extremely large when outputs are highly complex, making this result less desirable. To address this, we propose an algorithm that achieves a surrogate regret bound of $O(T^{2/3})$, which is independent of $K$. This is enabled with a carefully designed pseudo-inverse matrix estimator. Furthermore, for the delayed full information feedback setup, we obtain a surrogate regret bound of $O(D^{2/3} T^{1/3})$ for the delay time $D$. We also provide algorithms for the delayed bandit feedback setup. Finally, we numerically evaluate the performance of the proposed algorithms in online classification with bandit feedback.
Any-stepsize Gradient Descent for Separable Data under Fenchel--Young Losses
Feb 07, 2025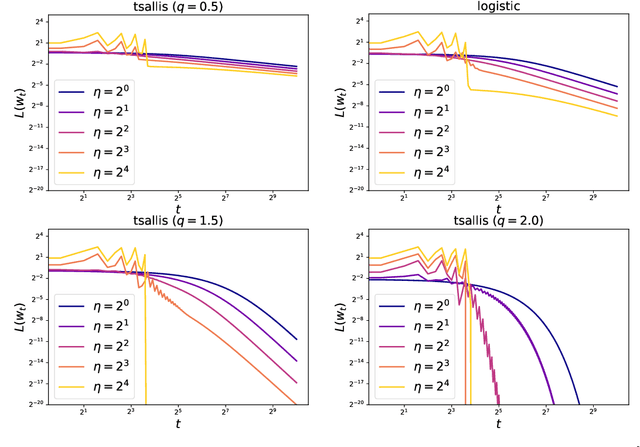

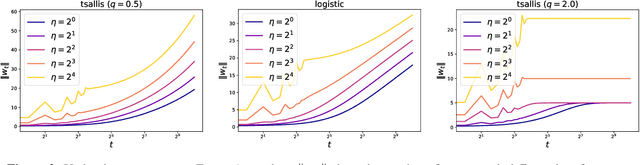
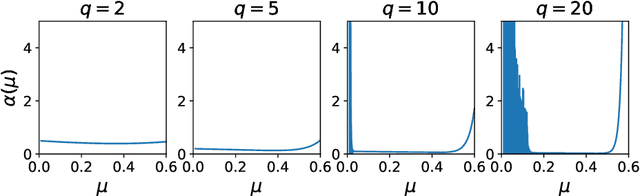
The gradient descent (GD) has been one of the most common optimizer in machine learning. In particular, the loss landscape of a neural network is typically sharpened during the initial phase of training, making the training dynamics hover on the edge of stability. This is beyond our standard understanding of GD convergence in the stable regime where arbitrarily chosen stepsize is sufficiently smaller than the edge of stability. Recently, Wu et al. (COLT2024) have showed that GD converges with arbitrary stepsize under linearly separable logistic regression. Although their analysis hinges on the self-bounding property of the logistic loss, which seems to be a cornerstone to establish a modified descent lemma, our pilot study shows that other loss functions without the self-bounding property can make GD converge with arbitrary stepsize. To further understand what property of a loss function matters in GD, we aim to show arbitrary-stepsize GD convergence for a general loss function based on the framework of \emph{Fenchel--Young losses}. We essentially leverage the classical perceptron argument to derive the convergence rate for achieving $\epsilon$-optimal loss, which is possible for a majority of Fenchel--Young losses. Among typical loss functions, the Tsallis entropy achieves the GD convergence rate $T=\Omega(\epsilon^{-1/2})$, and the R{\'e}nyi entropy achieves the far better rate $T=\Omega(\epsilon^{-1/3})$. We argue that these better rate is possible because of \emph{separation margin} of loss functions, instead of the self-bounding property.
Online Inverse Linear Optimization: Improved Regret Bound, Robustness to Suboptimality, and Toward Tight Regret Analysis
Jan 27, 2025
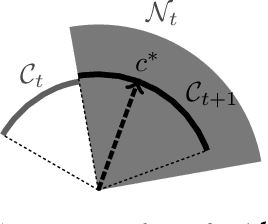
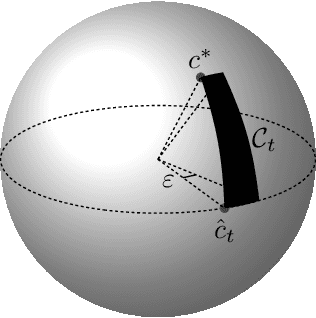
We study an online learning problem where, over $T$ rounds, a learner observes both time-varying sets of feasible actions and an agent's optimal actions, selected by solving linear optimization over the feasible actions. The learner sequentially makes predictions of the agent's underlying linear objective function, and their quality is measured by the regret, the cumulative gap between optimal objective values and those achieved by following the learner's predictions. A seminal work by B\"armann et al. (ICML 2017) showed that online learning methods can be applied to this problem to achieve regret bounds of $O(\sqrt{T})$. Recently, Besbes et al. (COLT 2021, Oper. Res. 2023) significantly improved the result by achieving an $O(n^4\ln T)$ regret bound, where $n$ is the dimension of the ambient space of objective vectors. Their method, based on the ellipsoid method, runs in polynomial time but is inefficient for large $n$ and $T$. In this paper, we obtain an $O(n\ln T)$ regret bound, improving upon the previous bound of $O(n^4\ln T)$ by a factor of $n^3$. Our method is simple and efficient: we apply the online Newton step (ONS) to appropriate exp-concave loss functions. Moreover, for the case where the agent's actions are possibly suboptimal, we establish an $O(n\ln T+\sqrt{\Delta_Tn\ln T})$ regret bound, where $\Delta_T$ is the cumulative suboptimality of the agent's actions. This bound is achieved by using MetaGrad, which runs ONS with $\Theta(\ln T)$ different learning rates in parallel. We also provide a simple instance that implies an $\Omega(n)$ lower bound, showing that our $O(n\ln T)$ bound is tight up to an $O(\ln T)$ factor. This gives rise to a natural question: can the $O(\ln T)$ factor in the upper bound be removed? For the special case of $n=2$, we show that an $O(1)$ regret bound is possible, while we delineate challenges in extending this result to higher dimensions.
Revisiting Online Learning Approach to Inverse Linear Optimization: A Fenchel$-$Young Loss Perspective and Gap-Dependent Regret Analysis
Jan 24, 2025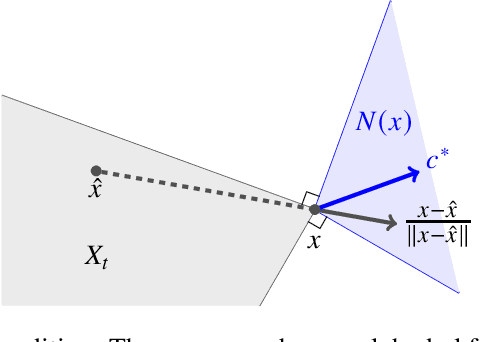
This paper revisits the online learning approach to inverse linear optimization studied by B\"armann et al. (2017), where the goal is to infer an unknown linear objective function of an agent from sequential observations of the agent's input-output pairs. First, we provide a simple understanding of the online learning approach through its connection to online convex optimization of \emph{Fenchel--Young losses}. As a byproduct, we present an offline guarantee on the \emph{suboptimality loss}, which measures how well predicted objectives explain the agent's choices, without assuming the optimality of the agent's choices. Second, assuming that there is a gap between optimal and suboptimal objective values in the agent's decision problems, we obtain an upper bound independent of the time horizon $T$ on the sum of suboptimality and \emph{estimate losses}, where the latter measures the quality of solutions recommended by predicted objectives. Interestingly, our gap-dependent analysis achieves a faster rate than the standard $O(\sqrt{T})$ regret bound by exploiting structures specific to inverse linear optimization, even though neither the loss functions nor their domains enjoy desirable properties, such as strong convexity.
No-Regret M${}^{ atural}$-Concave Function Maximization: Stochastic Bandit Algorithms and NP-Hardness of Adversarial Full-Information Setting
May 21, 2024
M${}^{\natural}$-concave functions, a.k.a. gross substitute valuation functions, play a fundamental role in many fields, including discrete mathematics and economics. In practice, perfect knowledge of M${}^{\natural}$-concave functions is often unavailable a priori, and we can optimize them only interactively based on some feedback. Motivated by such situations, we study online M${}^{\natural}$-concave function maximization problems, which are interactive versions of the problem studied by Murota and Shioura (1999). For the stochastic bandit setting, we present $O(T^{-1/2})$-simple regret and $O(T^{2/3})$-regret algorithms under $T$ times access to unbiased noisy value oracles of M${}^{\natural}$-concave functions. A key to proving these results is the robustness of the greedy algorithm to local errors in M${}^{\natural}$-concave function maximization, which is one of our main technical results. While we obtain those positive results for the stochastic setting, another main result of our work is an impossibility in the adversarial setting. We prove that, even with full-information feedback, no algorithms that run in polynomial time per round can achieve $O(T^{1-c})$ regret for any constant $c > 0$ unless $\mathsf{P} = \mathsf{NP}$. Our proof is based on a reduction from the matroid intersection problem for three matroids, which would be a novel idea in the context of online learning.
Online Structured Prediction with Fenchel--Young Losses and Improved Surrogate Regret for Online Multiclass Classification with Logistic Loss
Feb 13, 2024This paper studies online structured prediction with full-information feedback. For online multiclass classification, van der Hoeven (2020) has obtained surrogate regret bounds independent of the time horizon, or \emph{finite}, by introducing an elegant \emph{exploit-the-surrogate-gap} framework. However, this framework has been limited to multiclass classification primarily because it relies on a classification-specific procedure for converting estimated scores to outputs. We extend the exploit-the-surrogate-gap framework to online structured prediction with \emph{Fenchel--Young losses}, a large family of surrogate losses including the logistic loss for multiclass classification, obtaining finite surrogate regret bounds in various structured prediction problems. To this end, we propose and analyze \emph{randomized decoding}, which converts estimated scores to general structured outputs. Moreover, by applying our decoding to online multiclass classification with the logistic loss, we obtain a surrogate regret bound of $O(B^2)$, where $B$ is the $\ell_2$-diameter of the domain. This bound is tight up to logarithmic factors and improves the previous bound of $O(dB^2)$ due to van der Hoeven (2020) by a factor of $d$, the number of classes.