 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Generalization Bound and Learning of Sparsity Patterns for Data-Driven Low-Rank Approximation
Paper and Code
Sep 27, 2022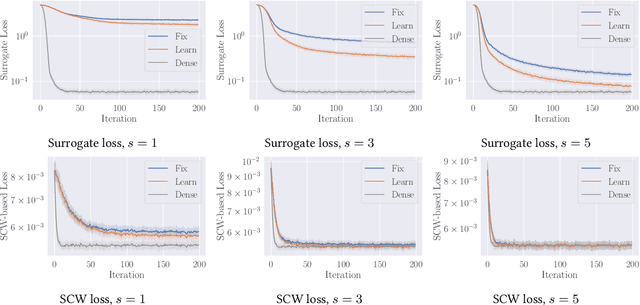
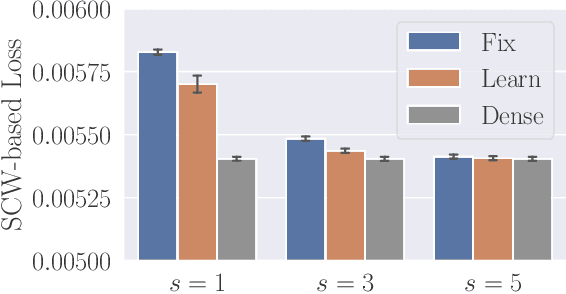
Learning sketching matrices for fast and accurate low-rank approximation (LRA) has gained increasing attention. Recently, Bartlett, Indyk, and Wagner (COLT 2022) presented a generalization bound for the learning-based LRA. Specifically, for rank-$k$ approximation using an $m \times n$ learned sketching matrix with $s$ non-zeros in each column, they proved an $\tilde{\mathrm{O}}(nsm)$ bound on the \emph{fat shattering dimension} ($\tilde{\mathrm{O}}$ hides logarithmic factors). We build on their work and make two contributions. 1. We present a better $\tilde{\mathrm{O}}(nsk)$ bound ($k \le m$). En route to obtaining the bound, we give a low-complexity \emph{Goldberg--Jerrum algorithm} for computing pseudo-inverse matrices, which would be of independent interest. 2. We alleviate an assumption of the previous study that the sparsity pattern of sketching matrices is fixed. We prove that learning positions of non-zeros increases the fat shattering dimension only by ${\mathrm{O}}(ns\log n)$. Also, experiments confirm the practical benefit of learning sparsity patterns.