 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnDeFog: Online Decision Transformer under Frame Dropping
Jun 18, 2026In challenging real-world reinforcement learning applications, communication delays or sensor failures often cause frame dropping, in which the agent cannot receive the dropped states and associated rewards. To address the performance degradation caused by frame dropping, the Decision Transformer under Random Frame Dropping (DeFog) was developed by incorporating additional mechanisms into the decision transformer to tackle frame dropping. Although DeFog can mitigate performance degradation in frame-dropping environments, since DeFog is an offline learning method, it struggles to effectively generalize to novel states not adequately represented in the training dataset. In this study, we propose OnDeFog, which integrates the mechanisms in DeFog with the online decision transformer (ODT), an online reinforcement learning method that learns policies through direct environmental interaction. Comprehensive experimental evaluation demonstrates that our proposed OnDeFog achieves superior performance compared to ODT in environments characterized by high dropping frame rate and outperforms DeFog on datasets containing a large amount of low-reward data.
Weight Adaptation for Improving Parallel Performance of Adaptive Stochastic Natural Gradient
Jun 18, 2026Probabilistic model-based evolutionary algorithms are promising for black-box optimization. Specifically, the adaptive stochastic natural gradient (ASNG) adaptively updates its learning rate, a typical hyperparameter in probabilistic model-based evolutionary algorithms, thereby realizing efficient and robust optimization. Although weight parameters are common hyperparameters, with the increasing demand for parallel evaluation of time-consuming tasks, it remains unclear how to set suitable weights for larger population sizes. In this paper, we propose Weight Adaptation ASNG (WA-ASNG), which incorporates a weight adaptation mechanism into ASNG. We calculated the estimated signal of the update direction from the accumulations of the natural gradient. Then, to maximize the signal, WA-ASNG adaptively updates its weight parameters by a gradient ascent over the optimization. While the learning rate adaptation plays a role in satisfying a sufficient condition for monotonic improvement of the expected objective value, the mechanism of weight adaptation is intended to maximize this improvement. The experimental results demonstrate that WA-ASNG outperforms PBIL and ASNG across various settings with population sizes ranging from 25 to 100 for binary optimization problems. Furthermore, WA-ASNG can perform efficiently in the presence of strong noise. Our code is available at https://github.com/shiralab/WA-ASNG .
Convergence Analysis of Evolution Strategies for Mixed-Integer Optimization
May 20, 2026Mixed-integer extensions of evolution strategies (ES) that discretize selected coordinates of sampled continuous vectors often impose a lower bound on the standard deviation of integer variables to prevent premature convergence. While these methods show promising empirical results, this handling can slow the convergence of continuous variables, and its impact has lacked a clear theoretical account. In this paper, we provide a convergence analysis of evolution strategies for mixed-integer optimization, inspired by the drift analysis of the (1+1)-ES in the continuous domain. Specifically, we consider two (1+1)-ES variants for mixed-integer domains: (1+1)-LB-ES, which introduces a lower bound on the standard deviation for integer variables, and (1+1)-LUB-ES, which combines both lower and upper bounds to enhance the convergence of the continuous variables. Focusing on the optimization phase after the integer variables have been optimized, we rigorously analyze their convergence behavior on a benchmark function designed for mixed-integer domains. Our results show that (1+1)-LB-ES can suffer from premature convergence when the number of integer variables is large, while (1+1)-LUB-ES achieves linear convergence under suitable parameter settings. These findings provide theoretical insights into the impact of integer handling on convergence performance and guidance for the design of mixed-integer ES.
Tunable MAGMAX: Preference-Aware Model Merging for Continual Learning
May 20, 2026Continual learning (CL) aims to train models sequentially on multiple tasks while mitigating catastrophic forgetting of previously learned knowledge. Recent advances in large pre-trained models (LPMs) and model merging techniques, such as MAGMAX, have demonstrated effective CL performance by combining task-specific parameters. However, existing methods primarily focus on average performance across all tasks and do not adequately address how to construct models accommodating different deployment environments or varying user preferences. This paper proposes a model merging framework, termed Tunable MAGMAX, which enables preference-aware control of task-specific performance in CL. Our method introduces a preference vector that controls the number of elements selected from each task vector during model merging, allowing us to adjust the merged model performance according to their deployment needs. We further propose a method for automatically constructing appropriate preference vectors by leveraging small amounts of target environment data and datasets from model training tasks, thereby eliminating the need for manual specification. The experimental result on CL benchmark tasks demonstrates that Tunable MAGMAX effectively controls task-wise performance and successfully adapts merged models to various target environments. The proposed Tunable MAGMAX achieves superior or comparable performance to baseline methods, making it a practical solution for deploying CL models to various environments where the preferences of each task performance differ.
Machine Learning-Based Self-Localization Using Internal Sensors for Automating Bulldozers
Jun 08, 2025
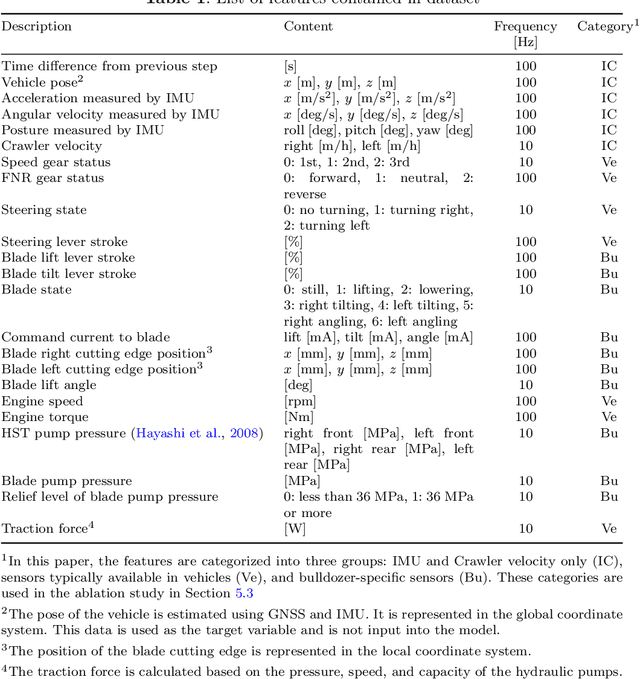


Self-localization is an important technology for automating bulldozers. Conventional bulldozer self-localization systems rely on RTK-GNSS (Real Time Kinematic-Global Navigation Satellite Systems). However, RTK-GNSS signals are sometimes lost in certain mining conditions. Therefore, self-localization methods that do not depend on RTK-GNSS are required. In this paper, we propose a machine learning-based self-localization method for bulldozers. The proposed method consists of two steps: estimating local velocities using a machine learning model from internal sensors, and incorporating these estimates into an Extended Kalman Filter (EKF) for global localization. We also created a novel dataset for bulldozer odometry and conducted experiments across various driving scenarios, including slalom, excavation, and driving on slopes. The result demonstrated that the proposed self-localization method suppressed the accumulation of position errors compared to kinematics-based methods, especially when slip occurred. Furthermore, this study showed that bulldozer-specific sensors, such as blade position sensors and hydraulic pressure sensors, contributed to improving self-localization accuracy.
CatCMA with Margin: Stochastic Optimization for Continuous, Integer, and Categorical Variables
Apr 10, 2025This study focuses on mixed-variable black-box optimization (MV-BBO), addressing continuous, integer, and categorical variables. Many real-world MV-BBO problems involve dependencies among these different types of variables, requiring efficient methods to optimize them simultaneously. Recently, stochastic optimization methods leveraging the mechanism of the covariance matrix adaptation evolution strategy have shown promising results in mixed-integer or mixed-category optimization. However, such methods cannot handle the three types of variables simultaneously. In this study, we propose CatCMA with Margin (CatCMAwM), a stochastic optimization method for MV-BBO that jointly optimizes continuous, integer, and categorical variables. CatCMAwM is developed by incorporating a novel integer handling into CatCMA, a mixed-category black-box optimization method employing a joint distribution of multivariate Gaussian and categorical distributions. The proposed integer handling is carefully designed by reviewing existing integer handlings and following the design principles of CatCMA. Even when applied to mixed-integer problems, it stabilizes the marginal probability and improves the convergence performance of continuous variables. Numerical experiments show that CatCMAwM effectively handles the three types of variables, outperforming state-of-the-art Bayesian optimization methods and baselines that simply incorporate existing integer handlings into CatCMA.
Bandit-Based Prompt Design Strategy Selection Improves Prompt Optimizers
Mar 03, 2025Prompt optimization aims to search for effective prompts that enhance the performance of large language models (LLMs). Although existing prompt optimization methods have discovered effective prompts, they often differ from sophisticated prompts carefully designed by human experts. Prompt design strategies, representing best practices for improving prompt performance, can be key to improving prompt optimization. Recently, a method termed the Autonomous Prompt Engineering Toolbox (APET) has incorporated various prompt design strategies into the prompt optimization process. In APET, the LLM is needed to implicitly select and apply the appropriate strategies because prompt design strategies can have negative effects. This implicit selection may be suboptimal due to the limited optimization capabilities of LLMs. This paper introduces Optimizing Prompts with sTrategy Selection (OPTS), which implements explicit selection mechanisms for prompt design. We propose three mechanisms, including a Thompson sampling-based approach, and integrate them into EvoPrompt, a well-known prompt optimizer. Experiments optimizing prompts for two LLMs, Llama-3-8B-Instruct and GPT-4o mini, were conducted using BIG-Bench Hard. Our results show that the selection of prompt design strategies improves the performance of EvoPrompt, and the Thompson sampling-based mechanism achieves the best overall results. Our experimental code is provided at https://github.com/shiralab/OPTS .
Warm Starting of CMA-ES for Contextual Optimization Problems
Feb 18, 2025Several practical applications of evolutionary computation possess objective functions that receive the design variables and externally given parameters. Such problems are termed contextual optimization problems. These problems require finding the optimal solutions corresponding to the given context vectors. Existing contextual optimization methods train a policy model to predict the optimal solution from context vectors. However, the performance of such models is limited by their representation ability. By contrast, warm starting methods have been used to initialize evolutionary algorithms on a given problem using the optimization results on similar problems. Because warm starting methods do not consider the context vectors, their performances can be improved on contextual optimization problems. Herein, we propose a covariance matrix adaptation evolution strategy with contextual warm starting (CMA-ES-CWS) to efficiently optimize the contextual optimization problem with a given context vector. The CMA-ES-CWS utilizes the optimization results of past context vectors to train the multivariate Gaussian process regression. Subsequently, the CMA-ES-CWS performs warm starting for a given context vector by initializing the search distribution using posterior distribution of the Gaussian process regression. The results of the numerical simulation suggest that CMA-ES-CWS outperforms the existing contextual optimization and warm starting methods.
CMA-ES for Discrete and Mixed-Variable Optimization on Sets of Points
Aug 23, 2024Discrete and mixed-variable optimization problems have appeared in several real-world applications. Most of the research on mixed-variable optimization considers a mixture of integer and continuous variables, and several integer handlings have been developed to inherit the optimization performance of the continuous optimization methods to mixed-integer optimization. In some applications, acceptable solutions are given by selecting possible points in the disjoint subspaces. This paper focuses on the optimization on sets of points and proposes an optimization method by extending the covariance matrix adaptation evolution strategy (CMA-ES), termed the CMA-ES on sets of points (CMA-ES-SoP). The CMA-ES-SoP incorporates margin correction that maintains the generation probability of neighboring points to prevent premature convergence to a specific non-optimal point, which is an effective integer-handling technique for CMA-ES. In addition, because margin correction with a fixed margin value tends to increase the marginal probabilities for a portion of neighboring points more than necessary, the CMA-ES-SoP updates the target margin value adaptively to make the average of the marginal probabilities close to a predefined target probability. Numerical simulations demonstrated that the CMA-ES-SoP successfully optimized the optimization problems on sets of points, whereas the naive CMA-ES failed to optimize them due to premature convergence.
Tail Bounds on the Runtime of Categorical Compact Genetic Algorithm
Jul 10, 2024

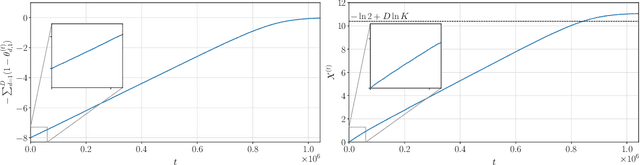

The majority of theoretical analyses of evolutionary algorithms in the discrete domain focus on binary optimization algorithms, even though black-box optimization on the categorical domain has a lot of practical applications. In this paper, we consider a probabilistic model-based algorithm using the family of categorical distributions as its underlying distribution and set the sample size as two. We term this specific algorithm the categorical compact genetic algorithm (ccGA). The ccGA can be considered as an extension of the compact genetic algorithm (cGA), which is an efficient binary optimization algorithm. We theoretically analyze the dependency of the number of possible categories $K$, the number of dimensions $D$, and the learning rate $\eta$ on the runtime. We investigate the tail bound of the runtime on two typical linear functions on the categorical domain: categorical OneMax (COM) and KVal. We derive that the runtimes on COM and KVal are $O(\sqrt{D} \ln (DK) / \eta)$ and $\Theta(D \ln K/ \eta)$ with high probability, respectively. Our analysis is a generalization for that of the cGA on the binary domain.