 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandit-Based Prompt Design Strategy Selection Improves Prompt Optimizers
Mar 03, 2025Prompt optimization aims to search for effective prompts that enhance the performance of large language models (LLMs). Although existing prompt optimization methods have discovered effective prompts, they often differ from sophisticated prompts carefully designed by human experts. Prompt design strategies, representing best practices for improving prompt performance, can be key to improving prompt optimization. Recently, a method termed the Autonomous Prompt Engineering Toolbox (APET) has incorporated various prompt design strategies into the prompt optimization process. In APET, the LLM is needed to implicitly select and apply the appropriate strategies because prompt design strategies can have negative effects. This implicit selection may be suboptimal due to the limited optimization capabilities of LLMs. This paper introduces Optimizing Prompts with sTrategy Selection (OPTS), which implements explicit selection mechanisms for prompt design. We propose three mechanisms, including a Thompson sampling-based approach, and integrate them into EvoPrompt, a well-known prompt optimizer. Experiments optimizing prompts for two LLMs, Llama-3-8B-Instruct and GPT-4o mini, were conducted using BIG-Bench Hard. Our results show that the selection of prompt design strategies improves the performance of EvoPrompt, and the Thompson sampling-based mechanism achieves the best overall results. Our experimental code is provided at https://github.com/shiralab/OPTS .
Neural Architecture Search for Improving Latency-Accuracy Trade-off in Split Computing
Aug 30, 2022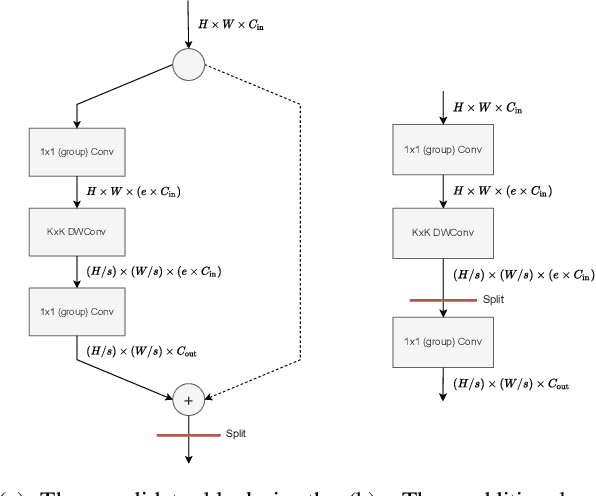
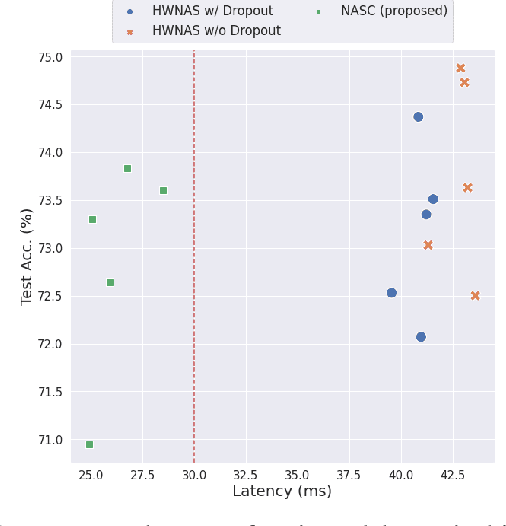
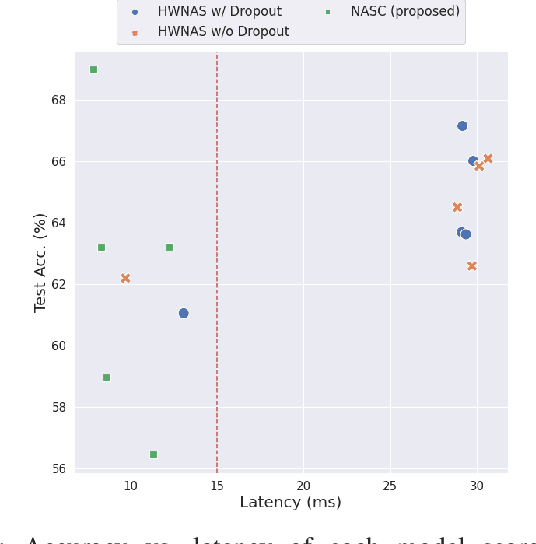
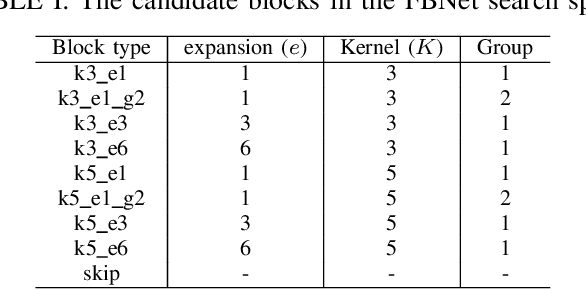
This paper proposes a neural architecture search (NAS) method for split computing. Split computing is an emerging machine-learning inference technique that addresses the privacy and latency challenges of deploying deep learning in IoT systems. In split computing, neural network models are separated and cooperatively processed using edge servers and IoT devices via networks. Thus, the architecture of the neural network model significantly impacts the communication payload size, model accuracy, and computational load. In this paper, we address the challenge of optimizing neural network architecture for split computing. To this end, we proposed NASC, which jointly explores optimal model architecture and a split point to achieve higher accuracy while meeting latency requirements (i.e., smaller total latency of computation and communication than a certain threshold). NASC employs a one-shot NAS that does not require repeating model training for a computationally efficient architecture search. Our performance evaluation using hardware (HW)-NAS-Bench of benchmark data demonstrates that the proposed NASC can improve the ``communication latency and model accuracy" trade-off, i.e., reduce the latency by approximately 40-60% from the baseline, with slight accuracy degradation.
NAS-HPO-Bench-II: A Benchmark Dataset on Joint Optimization of Convolutional Neural Network Architecture and Training Hyperparameters
Oct 19, 2021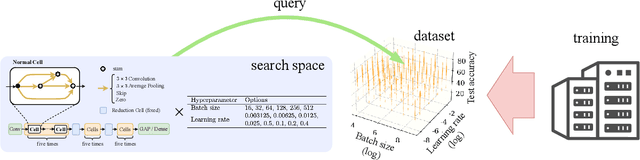
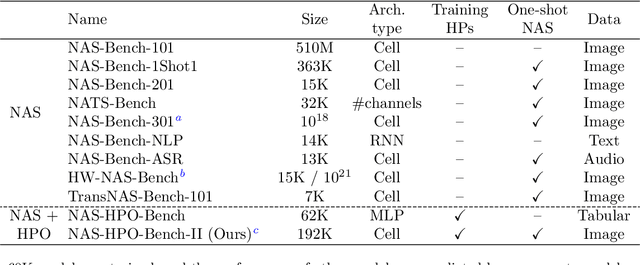

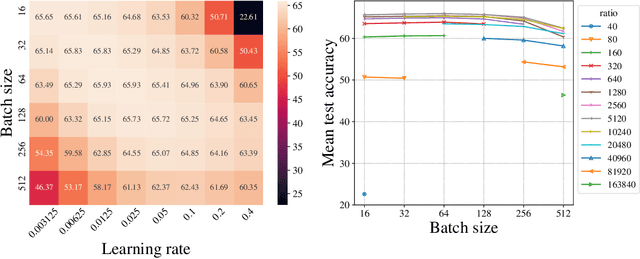
The benchmark datasets for neural architecture search (NAS) have been developed to alleviate the computationally expensive evaluation process and ensure a fair comparison. Recent NAS benchmarks only focus on architecture optimization, although the training hyperparameters affect the obtained model performances. Building the benchmark dataset for joint optimization of architecture and training hyperparameters is essential to further NAS research. The existing NAS-HPO-Bench is a benchmark for joint optimization, but it does not consider the network connectivity design as done in modern NAS algorithms. This paper introduces the first benchmark dataset for joint optimization of network connections and training hyperparameters, which we call NAS-HPO-Bench-II. We collect the performance data of 4K cell-based convolutional neural network architectures trained on the CIFAR-10 dataset with different learning rate and batch size settings, resulting in the data of 192K configurations. The dataset includes the exact data for 12 epoch training. We further build the surrogate model predicting the accuracies after 200 epoch training to provide the performance data of longer training epoch. By analyzing NAS-HPO-Bench-II, we confirm the dependency between architecture and training hyperparameters and the necessity of joint optimization. Finally, we demonstrate the benchmarking of the baseline optimization algorithms using NAS-HPO-Bench-II.