 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarially Trained Object Detector for Unsupervised Domain Adaptation
Sep 13, 2021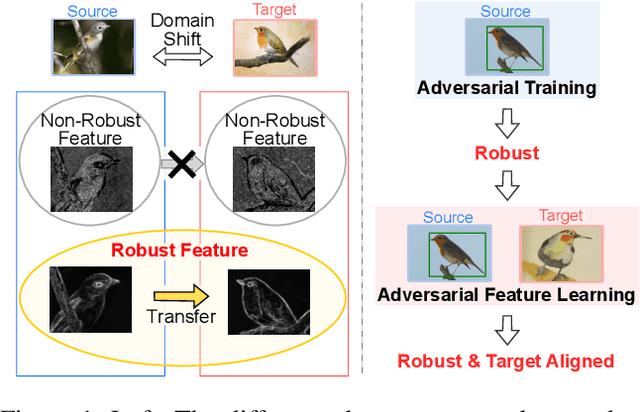
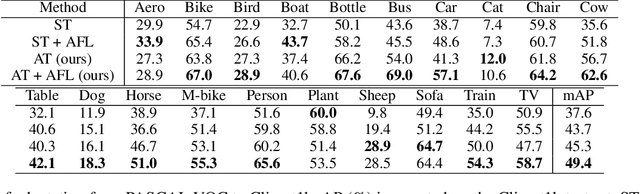
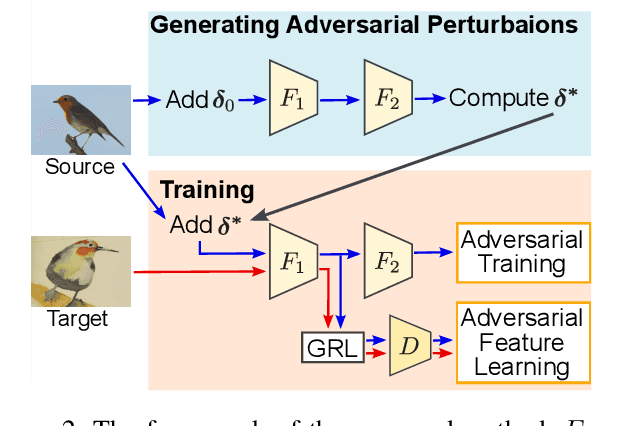
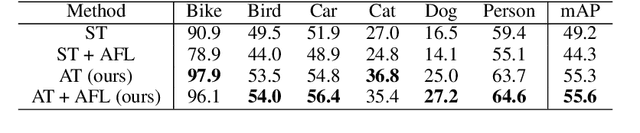
Unsupervised domain adaptation, which involves transferring knowledge from a label-rich source domain to an unlabeled target domain, can be used to substantially reduce annotation costs in the field of object detection. In this study, we demonstrate that adversarial training in the source domain can be employed as a new approach for unsupervised domain adaptation. Specifically, we establish that adversarially trained detectors achieve improved detection performance in target domains that are significantly shifted from source domains. This phenomenon is attributed to the fact that adversarially trained detectors can be used to extract robust features that are in alignment with human perception and worth transferring across domains while discarding domain-specific non-robust features. In addition, we propose a method that combines adversarial training and feature alignment to ensure the improved alignment of robust features with the target domain. We conduct experiments on four benchmark datasets and confirm the effectiveness of our proposed approach on large domain shifts from real to artistic images. Compared to the baseline models, the adversarially trained detectors improve the mean average precision by up to 7.7\%, and further by up to 11.8\% when feature alignments are incorporated.
Cell Detection from Imperfect Annotation by Pseudo Label Selection Using P-classification
Jul 21, 2021
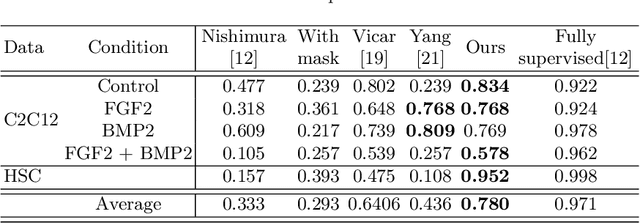
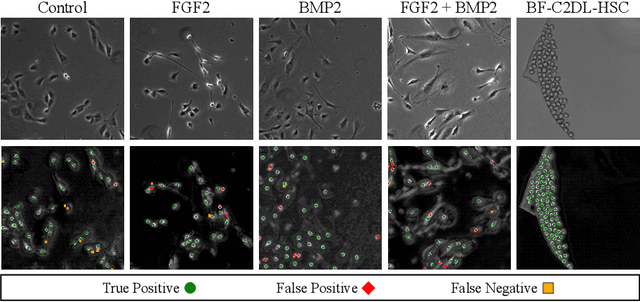
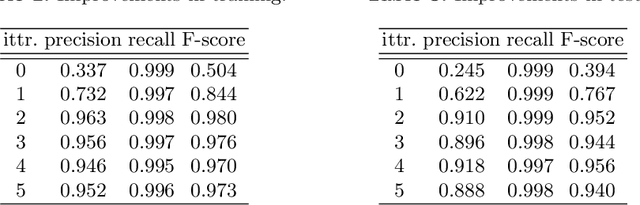
Cell detection is an essential task in cell image analysis. Recent deep learning-based detection methods have achieved very promising results. In general, these methods require exhaustively annotating the cells in an entire image. If some of the cells are not annotated (imperfect annotation), the detection performance significantly degrades due to noisy labels. This often occurs in real collaborations with biologists and even in public data-sets. Our proposed method takes a pseudo labeling approach for cell detection from imperfect annotated data. A detection convolutional neural network (CNN) trained using such missing labeled data often produces over-detection. We treat partially labeled cells as positive samples and the detected positions except for the labeled cell as unlabeled samples. Then we select reliable pseudo labels from unlabeled data using recent machine learning techniques; positive-and-unlabeled (PU) learning and P-classification. Experiments using microscopy images for five different conditions demonstrate the effectiveness of the proposed method.