 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanation Multiplicity in SHAP: Characterization and Assessment
Jan 19, 2026Post-hoc explanations are widely used to justify, contest, and audit automated decisions in high-stakes domains. SHAP, in particular, is often treated as a reliable account of which features drove an individual prediction. Yet SHAP explanations can vary substantially across repeated runs even when the input, task, and trained model are held fixed. We term this phenomenon explanation multiplicity: multiple internally valid but substantively different explanations for the same decision. We present a methodology to characterize multiplicity in feature-attribution explanations and to disentangle sources due to model training/selection from stochasticity intrinsic to the explanation pipeline. We further show that apparent stability depends on the metric: magnitude-based distances can remain near zero while rank-based measures reveal substantial churn in the identity and ordering of top features. To contextualize observed disagreement, we derive randomized baseline values under plausible null models. Across datasets, model classes, and confidence regimes, we find explanation multiplicity is pervasive and persists even for high-confidence predictions, highlighting the need for metrics and baselines that match the intended use of explanations.
SCORPION: Addressing Scanner-Induced Variability in Histopathology
Jul 28, 2025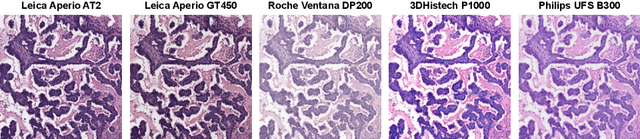
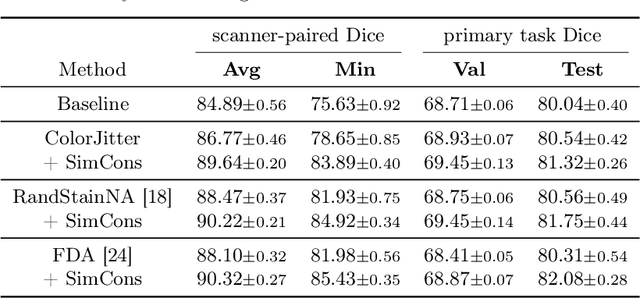


Ensuring reliable model performance across diverse domains is a critical challenge in computational pathology. A particular source of variability in Whole-Slide Images is introduced by differences in digital scanners, thus calling for better scanner generalization. This is critical for the real-world adoption of computational pathology, where the scanning devices may differ per institution or hospital, and the model should not be dependent on scanner-induced details, which can ultimately affect the patient's diagnosis and treatment planning. However, past efforts have primarily focused on standard domain generalization settings, evaluating on unseen scanners during training, without directly evaluating consistency across scanners for the same tissue. To overcome this limitation, we introduce SCORPION, a new dataset explicitly designed to evaluate model reliability under scanner variability. SCORPION includes 480 tissue samples, each scanned with 5 scanners, yielding 2,400 spatially aligned patches. This scanner-paired design allows for the isolation of scanner-induced variability, enabling a rigorous evaluation of model consistency while controlling for differences in tissue composition. Furthermore, we propose SimCons, a flexible framework that combines augmentation-based domain generalization techniques with a consistency loss to explicitly address scanner generalization. We empirically show that SimCons improves model consistency on varying scanners without compromising task-specific performance. By releasing the SCORPION dataset and proposing SimCons, we provide the research community with a crucial resource for evaluating and improving model consistency across diverse scanners, setting a new standard for reliability testing.
Table2Image: Interpretable Tabular data Classification with Realistic Image Transformations
Dec 09, 2024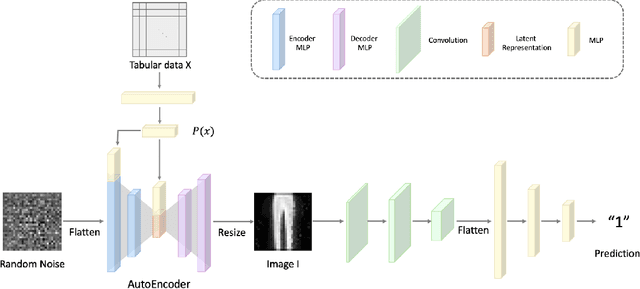
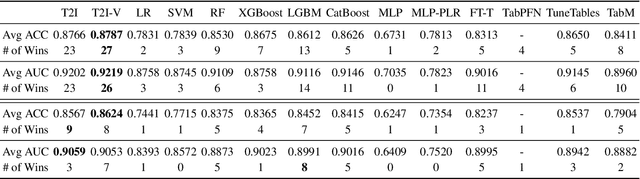
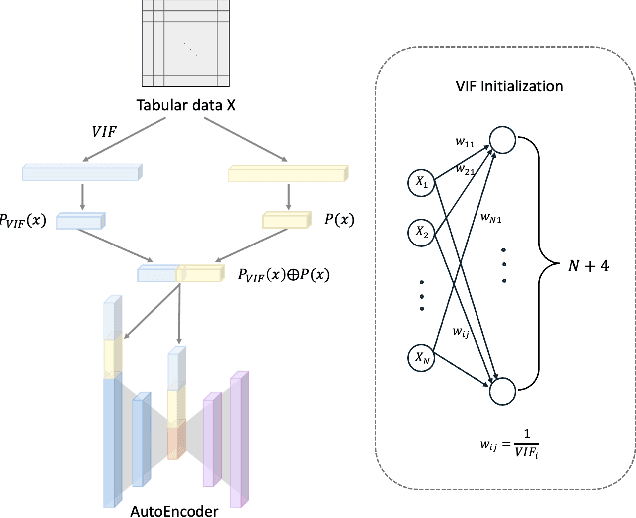
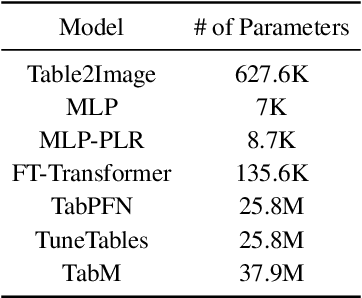
Recent advancements in deep learning for tabular data have demonstrated promising performance, yet interpretable models remain limited, with many relying on complex and large-scale architectures. This paper introduces Table2Image, an interpretable framework that transforms tabular data into realistic image representations for classification, achieving competitive performance with relatively lightweight models. Additionally, we propose variance inflation factor (VIF) initialization, which reflects the statistical properties of the data, and a novel interpretability framework that integrates insights from both the original tabular data and its image transformations. By leveraging Shapley additive explanations (SHAP) with methods to minimize distributional discrepancies, our approach combines tabular and image-based representations. Experiments on benchmark datasets showcase competitive classification accuracy, area under the curve (AUC), and improved interpretability, offering a scalable and reliable solution. Our code is available at https://github.com/duneag2/table2image.
Experimental Study: Enhancing Voice Spoofing Detection Models with wav2vec 2.0
Feb 27, 2024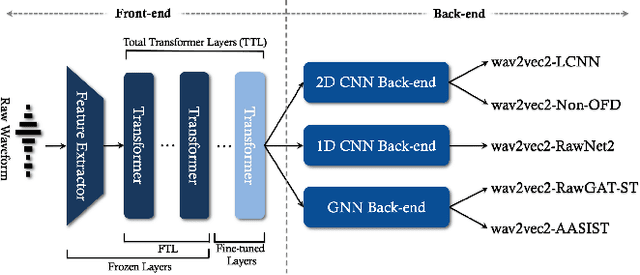
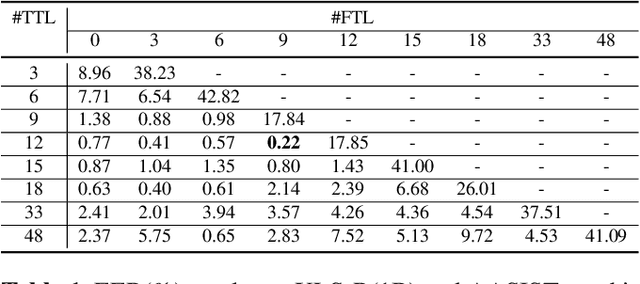
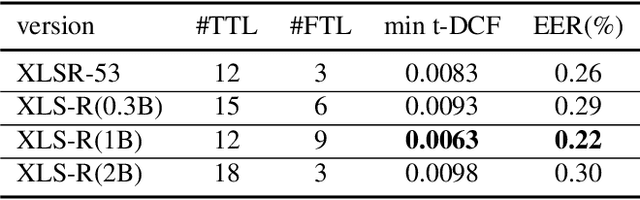
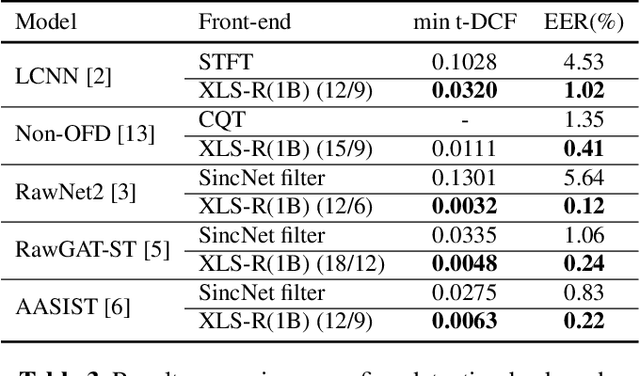
Conventional spoofing detection systems have heavily relied on the use of handcrafted features derived from speech data. However, a notable shift has recently emerged towards the direct utilization of raw speech waveforms, as demonstrated by methods like SincNet filters. This shift underscores the demand for more sophisticated audio sample features. Moreover, the success of deep learning models, particularly those utilizing large pretrained wav2vec 2.0 as a featurization front-end, highlights the importance of refined feature encoders. In response, this research assessed the representational capability of wav2vec 2.0 as an audio feature extractor, modifying the size of its pretrained Transformer layers through two key adjustments: (1) selecting a subset of layers starting from the leftmost one and (2) fine-tuning a portion of the selected layers from the rightmost one. We complemented this analysis with five spoofing detection back-end models, with a primary focus on AASIST, enabling us to pinpoint the optimal configuration for the selection and fine-tuning process. In contrast to conventional handcrafted features, our investigation identified several spoofing detection systems that achieve state-of-the-art performance in the ASVspoof 2019 LA dataset. This comprehensive exploration offers valuable insights into feature selection strategies, advancing the field of spoofing detection.