 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEAT2AASIST model with layer fusion for ESDD 2026 Challenge
Dec 17, 2025Recent advances in audio generation have increased the risk of realistic environmental sound manipulation, motivating the ESDD 2026 Challenge as the first large-scale benchmark for Environmental Sound Deepfake Detection (ESDD). We propose BEAT2AASIST which extends BEATs-AASIST by splitting BEATs-derived representations along frequency or channel dimension and processing them with dual AASIST branches. To enrich feature representations, we incorporate top-k transformer layer fusion using concatenation, CNN-gated, and SE-gated strategies. In addition, vocoder-based data augmentation is applied to improve robustness against unseen spoofing methods. Experimental results on the official test sets demonstrate that the proposed approach achieves competitive performance across the challenge tracks.
Sub-optimality of the Separation Principle for Quadratic Control from Bilinear Observations
Apr 15, 2025We consider the problem of controlling a linear dynamical system from bilinear observations with minimal quadratic cost. Despite the similarity of this problem to standard linear quadratic Gaussian (LQG) control, we show that when the observation model is bilinear, neither does the Separation Principle hold, nor is the optimal controller affine in the estimated state. Moreover, the cost-to-go is non-convex in the control input. Hence, finding an analytical expression for the optimal feedback controller is difficult in general. Under certain settings, we show that the standard LQG controller locally maximizes the cost instead of minimizing it. Furthermore, the optimal controllers (derived analytically) are not unique and are nonlinear in the estimated state. We also introduce a notion of input-dependent observability and derive conditions under which the Kalman filter covariance remains bounded. We illustrate our theoretical results through numerical experiments in multiple synthetic settings.
Experimental Study: Enhancing Voice Spoofing Detection Models with wav2vec 2.0
Feb 27, 2024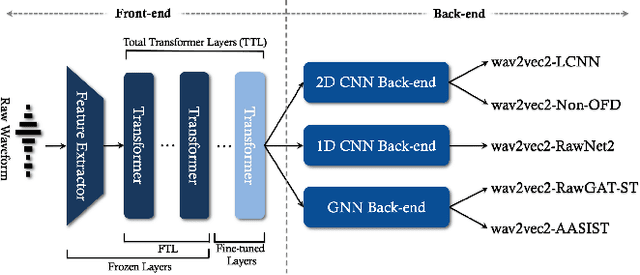
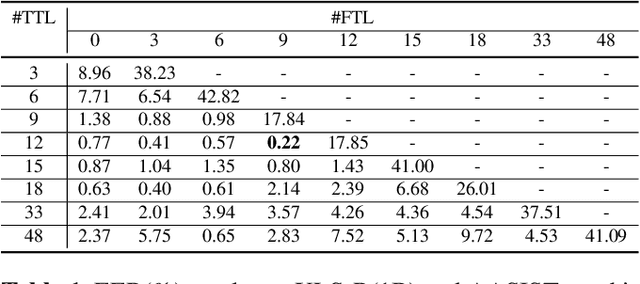
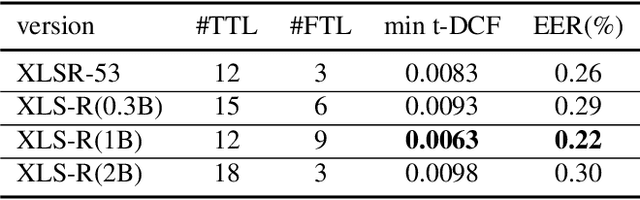
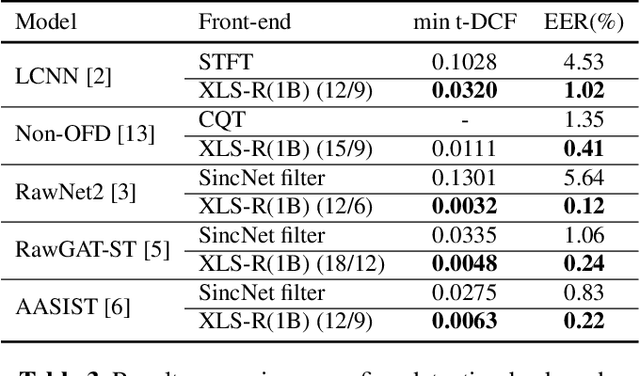
Conventional spoofing detection systems have heavily relied on the use of handcrafted features derived from speech data. However, a notable shift has recently emerged towards the direct utilization of raw speech waveforms, as demonstrated by methods like SincNet filters. This shift underscores the demand for more sophisticated audio sample features. Moreover, the success of deep learning models, particularly those utilizing large pretrained wav2vec 2.0 as a featurization front-end, highlights the importance of refined feature encoders. In response, this research assessed the representational capability of wav2vec 2.0 as an audio feature extractor, modifying the size of its pretrained Transformer layers through two key adjustments: (1) selecting a subset of layers starting from the leftmost one and (2) fine-tuning a portion of the selected layers from the rightmost one. We complemented this analysis with five spoofing detection back-end models, with a primary focus on AASIST, enabling us to pinpoint the optimal configuration for the selection and fine-tuning process. In contrast to conventional handcrafted features, our investigation identified several spoofing detection systems that achieve state-of-the-art performance in the ASVspoof 2019 LA dataset. This comprehensive exploration offers valuable insights into feature selection strategies, advancing the field of spoofing detection.
CAU_KU team's submission to ADD 2022 Challenge task 1: Low-quality fake audio detection through frequency feature masking
Feb 09, 2022
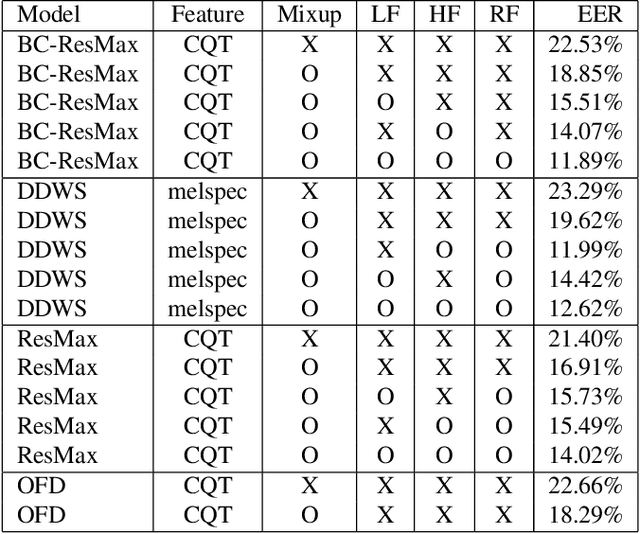
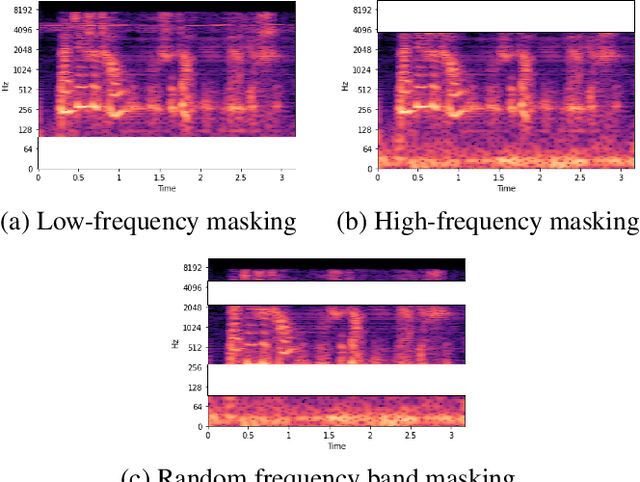

This technical report describes Chung-Ang University and Korea University (CAU_KU) team's model participating in the Audio Deep Synthesis Detection (ADD) 2022 Challenge, track 1: Low-quality fake audio detection. For track 1, we propose a frequency feature masking (FFM) augmentation technique to deal with a low-quality audio environment. %detection that spectrogram-based models can be applied. We applied FFM and mixup augmentation on five spectrogram-based deep neural network architectures that performed well for spoofing detection using mel-spectrogram and constant Q transform (CQT) features. Our best submission achieved 23.8% of EER ranked 3rd on track 1.