 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Study: Enhancing Voice Spoofing Detection Models with wav2vec 2.0
Paper and Code
Feb 27, 2024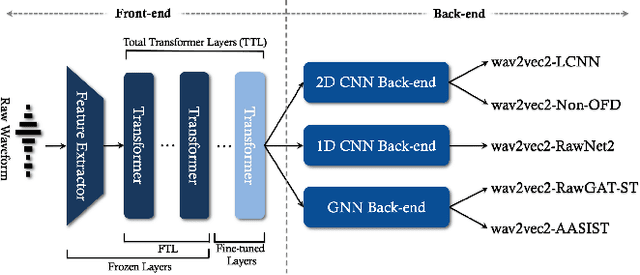
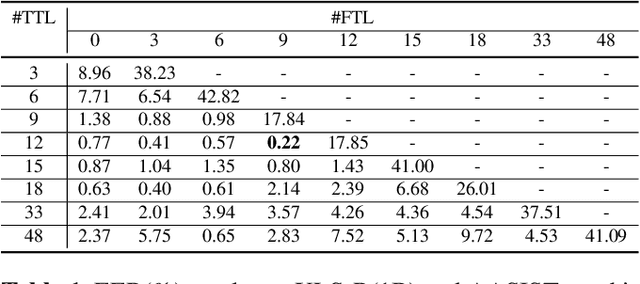
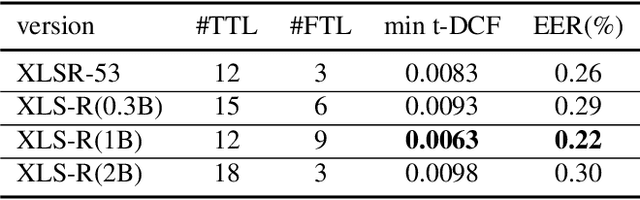
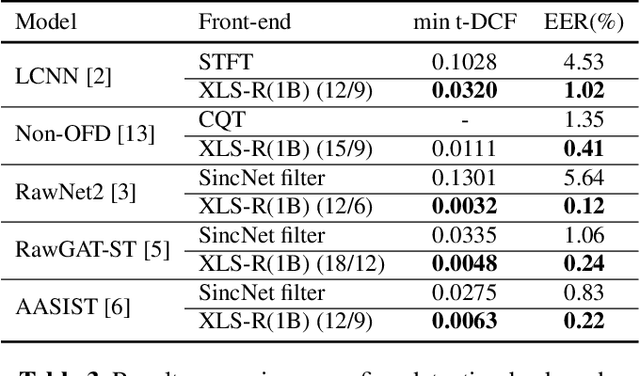
Conventional spoofing detection systems have heavily relied on the use of handcrafted features derived from speech data. However, a notable shift has recently emerged towards the direct utilization of raw speech waveforms, as demonstrated by methods like SincNet filters. This shift underscores the demand for more sophisticated audio sample features. Moreover, the success of deep learning models, particularly those utilizing large pretrained wav2vec 2.0 as a featurization front-end, highlights the importance of refined feature encoders. In response, this research assessed the representational capability of wav2vec 2.0 as an audio feature extractor, modifying the size of its pretrained Transformer layers through two key adjustments: (1) selecting a subset of layers starting from the leftmost one and (2) fine-tuning a portion of the selected layers from the rightmost one. We complemented this analysis with five spoofing detection back-end models, with a primary focus on AASIST, enabling us to pinpoint the optimal configuration for the selection and fine-tuning process. In contrast to conventional handcrafted features, our investigation identified several spoofing detection systems that achieve state-of-the-art performance in the ASVspoof 2019 LA dataset. This comprehensive exploration offers valuable insights into feature selection strategies, advancing the field of spoofing detection.