 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Exponential Extension of Sliding Window Context with Cascading KV Cache
Jun 24, 2024
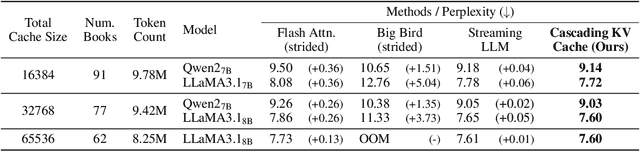


The context window within a transformer provides a form of active memory for the current task, which can be useful for few-shot learning and conditional generation, both which depend heavily on previous context tokens. However, as the context length grows, the computational cost increases quadratically. Recent works have shown that saving a few initial tokens along with a fixed-sized sliding window leads to stable streaming generation with linear complexity in transformer-based Large Language Models (LLMs). However, they make suboptimal use of the fixed window by naively evicting all tokens unconditionally from the key-value (KV) cache once they reach the end of the window, resulting in tokens being forgotten and no longer able to affect subsequent predictions. To overcome this limitation, we propose a novel mechanism for storing longer sliding window contexts with the same total cache size by keeping separate cascading sub-cache buffers whereby each subsequent buffer conditionally accepts a fraction of the relatively more important tokens evicted from the previous buffer. Our method results in a dynamic KV cache that can store tokens from the more distant past than a fixed, static sliding window approach. Our experiments show improvements of 5.6% on long context generation (LongBench), 1.2% in streaming perplexity (PG19), and 0.6% in language understanding (MMLU STEM) using LLMs given the same fixed cache size. Additionally, we provide an efficient implementation that improves the KV cache latency from 1.33ms per caching operation to 0.54ms, a 59% speedup over previous work.
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Jun 14, 2024In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T \log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
REP: Resource-Efficient Prompting for On-device Continual Learning
Jun 07, 2024



On-device continual learning (CL) requires the co-optimization of model accuracy and resource efficiency to be practical. This is extremely challenging because it must preserve accuracy while learning new tasks with continuously drifting data and maintain both high energy and memory efficiency to be deployable on real-world devices. Typically, a CL method leverages one of two types of backbone networks: CNN or ViT. It is commonly believed that CNN-based CL excels in resource efficiency, whereas ViT-based CL is superior in model performance, making each option attractive only for a single aspect. In this paper, we revisit this comparison while embracing powerful pre-trained ViT models of various sizes, including ViT-Ti (5.8M parameters). Our detailed analysis reveals that many practical options exist today for making ViT-based methods more suitable for on-device CL, even when accuracy, energy, and memory are all considered. To further expand this impact, we introduce REP, which improves resource efficiency specifically targeting prompt-based rehearsal-free methods. Our key focus is on avoiding catastrophic trade-offs with accuracy while trimming computational and memory costs throughout the training process. We achieve this by exploiting swift prompt selection that enhances input data using a carefully provisioned model, and by developing two novel algorithms-adaptive token merging (AToM) and adaptive layer dropping (ALD)-that optimize the prompt updating stage. In particular, AToM and ALD perform selective skipping across the data and model-layer dimensions without compromising task-specific features in vision transformer models. Extensive experiments on three image classification datasets validate REP's superior resource efficiency over current state-of-the-art methods.
Cost-effective On-device Continual Learning over Memory Hierarchy with Miro
Aug 17, 2023Continual learning (CL) trains NN models incrementally from a continuous stream of tasks. To remember previously learned knowledge, prior studies store old samples over a memory hierarchy and replay them when new tasks arrive. Edge devices that adopt CL to preserve data privacy are typically energy-sensitive and thus require high model accuracy while not compromising energy efficiency, i.e., cost-effectiveness. Our work is the first to explore the design space of hierarchical memory replay-based CL to gain insights into achieving cost-effectiveness on edge devices. We present Miro, a novel system runtime that carefully integrates our insights into the CL framework by enabling it to dynamically configure the CL system based on resource states for the best cost-effectiveness. To reach this goal, Miro also performs online profiling on parameters with clear accuracy-energy trade-offs and adapts to optimal values with low overhead. Extensive evaluations show that Miro significantly outperforms baseline systems we build for comparison, consistently achieving higher cost-effectiveness.
Carousel Memory: Rethinking the Design of Episodic Memory for Continual Learning
Oct 15, 2021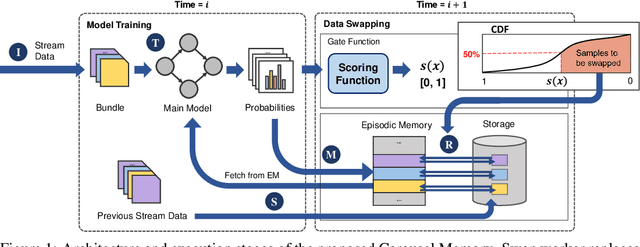
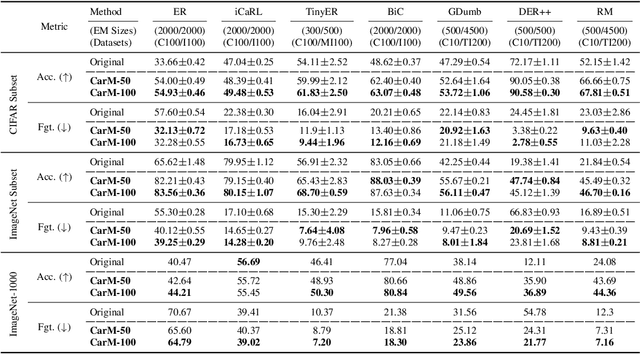
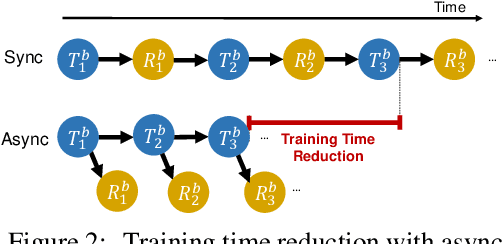
Continual Learning (CL) is an emerging machine learning paradigm that aims to learn from a continuous stream of tasks without forgetting knowledge learned from the previous tasks. To avoid performance decrease caused by forgetting, prior studies exploit episodic memory (EM), which stores a subset of the past observed samples while learning from new non-i.i.d. data. Despite the promising results, since CL is often assumed to execute on mobile or IoT devices, the EM size is bounded by the small hardware memory capacity and makes it infeasible to meet the accuracy requirements for real-world applications. Specifically, all prior CL methods discard samples overflowed from the EM and can never retrieve them back for subsequent training steps, incurring loss of information that would exacerbate catastrophic forgetting. We explore a novel hierarchical EM management strategy to address the forgetting issue. In particular, in mobile and IoT devices, real-time data can be stored not just in high-speed RAMs but in internal storage devices as well, which offer significantly larger capacity than the RAMs. Based on this insight, we propose to exploit the abundant storage to preserve past experiences and alleviate the forgetting by allowing CL to efficiently migrate samples between memory and storage without being interfered by the slow access speed of the storage. We call it Carousel Memory (CarM). As CarM is complementary to existing CL methods, we conduct extensive evaluations of our method with seven popular CL methods and show that CarM significantly improves the accuracy of the methods across different settings by large margins in final average accuracy (up to 28.4%) while retaining the same training efficiency.