 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQE-CIR: Distinctive Query Embeddings through Learnable Attribute Weights and Target Relative Negative Sampling in Composed Image Retrieval
Mar 04, 2026Composed image retrieval (CIR) addresses the task of retrieving a target image by jointly interpreting a reference image and a modification text that specifies the intended change. Most existing methods are still built upon contrastive learning frameworks that treat the ground truth image as the only positive instance and all remaining images as negatives. This strategy inevitably introduces relevance suppression, where semantically related yet valid images are incorrectly pushed away, and semantic confusion, where different modification intents collapse into overlapping regions of the embedding space. As a result, the learned query representations often lack discriminativeness, particularly at fine-grained attribute modifications. To overcome these limitations, we propose distinctive query embeddings through learnable attribute weights and target relative negative sampling (DQE-CIR), a method designed to learn distinctive query embeddings by explicitly modeling target relative relevance during training. DQE-CIR incorporates learnable attribute weighting to emphasize distinctive visual features conditioned on the modification text, enabling more precise feature alignment between language and vision. Furthermore, we introduce target relative negative sampling, which constructs a target relative similarity distribution and selects informative negatives from a mid-zone region that excludes both easy negatives and ambiguous false negatives. This strategy enables more reliable retrieval for fine-grained attribute changes by improving query discriminativeness and reducing confusion caused by semantically similar but irrelevant candidates.
Breaking the Pre-Sampling Barrier: Activation-Informed Difficulty-Aware Self-Consistency
Feb 10, 2026Self-Consistency (SC) is an effective decoding strategy that improves the reasoning performance of Large Language Models (LLMs) by generating multiple chain-of-thought reasoning paths and selecting the final answer via majority voting. However, it suffers from substantial inference costs because it requires a large number of samples. To mitigate this issue, Difficulty-Adaptive Self-Consistency (DSC) was proposed to reduce unnecessary token usage for easy problems by adjusting the number of samples according to problem difficulty. However, DSC requires additional model calls and pre-sampling to estimate difficulty, and this process is repeated when applying to each dataset, leading to significant computational overhead. In this work, we propose Activation-Informed Difficulty-Aware Self-Consistency (ACTSC) to address these limitations. ACTSC leverages internal difficulty signals reflected in the feed-forward network neuron activations to construct a lightweight difficulty estimation probe, without any additional token generation or model calls. The probe dynamically adjusts the number of samples for SC and can be applied to new datasets without requiring pre-sampling for difficulty estimation. To validate its effectiveness, we conduct experiments on five benchmarks. Experimental results show that ACTSC effectively reduces inference costs while maintaining accuracy relative to existing methods.
RaDL: Relation-aware Disentangled Learning for Multi-Instance Text-to-Image Generation
Jul 16, 2025With recent advancements in text-to-image (T2I) models, effectively generating multiple instances within a single image prompt has become a crucial challenge. Existing methods, while successful in generating positions of individual instances, often struggle to account for relationship discrepancy and multiple attributes leakage. To address these limitations, this paper proposes the relation-aware disentangled learning (RaDL) framework. RaDL enhances instance-specific attributes through learnable parameters and generates relation-aware image features via Relation Attention, utilizing action verbs extracted from the global prompt. Through extensive evaluations on benchmarks such as COCO-Position, COCO-MIG, and DrawBench, we demonstrate that RaDL outperforms existing methods, showing significant improvements in positional accuracy, multiple attributes consideration, and the relationships between instances. Our results present RaDL as the solution for generating images that consider both the relationships and multiple attributes of each instance within the multi-instance image.
InfiniteHiP: Extending Language Model Context Up to 3 Million Tokens on a Single GPU
Feb 13, 2025In modern large language models (LLMs), handling very long context lengths presents significant challenges as it causes slower inference speeds and increased memory costs. Additionally, most existing pre-trained LLMs fail to generalize beyond their original training sequence lengths. To enable efficient and practical long-context utilization, we introduce InfiniteHiP, a novel, and practical LLM inference framework that accelerates processing by dynamically eliminating irrelevant context tokens through a modular hierarchical token pruning algorithm. Our method also allows generalization to longer sequences by selectively applying various RoPE adjustment methods according to the internal attention patterns within LLMs. Furthermore, we offload the key-value cache to host memory during inference, significantly reducing GPU memory pressure. As a result, InfiniteHiP enables the processing of up to 3 million tokens on a single L40s 48GB GPU -- 3x larger -- without any permanent loss of context information. Our framework achieves an 18.95x speedup in attention decoding for a 1 million token context without requiring additional training. We implement our method in the SGLang framework and demonstrate its effectiveness and practicality through extensive evaluations.
VideoICL: Confidence-based Iterative In-context Learning for Out-of-Distribution Video Understanding
Dec 03, 2024
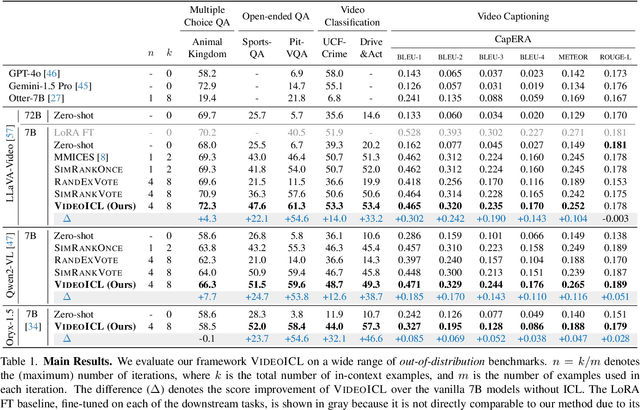


Recent advancements in video large multimodal models (LMMs) have significantly improved their video understanding and reasoning capabilities. However, their performance drops on out-of-distribution (OOD) tasks that are underrepresented in training data. Traditional methods like fine-tuning on OOD datasets are impractical due to high computational costs. While In-context learning (ICL) with demonstration examples has shown promising generalization performance in language tasks and image-language tasks without fine-tuning, applying ICL to video-language tasks faces challenges due to the limited context length in Video LMMs, as videos require longer token lengths. To address these issues, we propose VideoICL, a novel video in-context learning framework for OOD tasks that introduces a similarity-based relevant example selection strategy and a confidence-based iterative inference approach. This allows to select the most relevant examples and rank them based on similarity, to be used for inference. If the generated response has low confidence, our framework selects new examples and performs inference again, iteratively refining the results until a high-confidence response is obtained. This approach improves OOD video understanding performance by extending effective context length without incurring high costs. The experimental results on multiple benchmarks demonstrate significant performance gains, especially in domain-specific scenarios, laying the groundwork for broader video comprehension applications. Code will be released at https://github.com/KangsanKim07/VideoICL
HiP Attention: Sparse Sub-Quadratic Attention with Hierarchical Attention Pruning
Jun 14, 2024In modern large language models (LLMs), increasing sequence lengths is a crucial challenge for enhancing their comprehension and coherence in handling complex tasks such as multi-modal question answering. However, handling long context sequences with LLMs is prohibitively costly due to the conventional attention mechanism's quadratic time and space complexity, and the context window size is limited by the GPU memory. Although recent works have proposed linear and sparse attention mechanisms to address this issue, their real-world applicability is often limited by the need to re-train pre-trained models. In response, we propose a novel approach, Hierarchically Pruned Attention (HiP), which simultaneously reduces the training and inference time complexity from $O(T^2)$ to $O(T \log T)$ and the space complexity from $O(T^2)$ to $O(T)$. To this end, we devise a dynamic sparse attention mechanism that generates an attention mask through a novel tree-search-like algorithm for a given query on the fly. HiP is training-free as it only utilizes the pre-trained attention scores to spot the positions of the top-$k$ most significant elements for each query. Moreover, it ensures that no token is overlooked, unlike the sliding window-based sub-quadratic attention methods, such as StreamingLLM. Extensive experiments on diverse real-world benchmarks demonstrate that HiP significantly reduces prompt (i.e., prefill) and decoding latency and memory usage while maintaining high generation performance with little or no degradation. As HiP allows pretrained LLMs to scale to millions of tokens on commodity GPUs with no additional engineering due to its easy plug-and-play deployment, we believe that our work will have a large practical impact, opening up the possibility to many long-context LLM applications previously infeasible.
BiTAT: Neural Network Binarization with Task-dependent Aggregated Transformation
Jul 04, 2022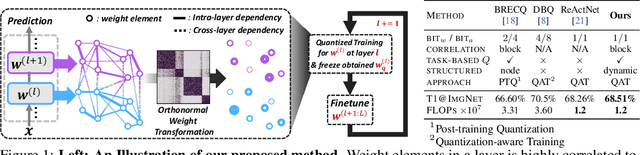
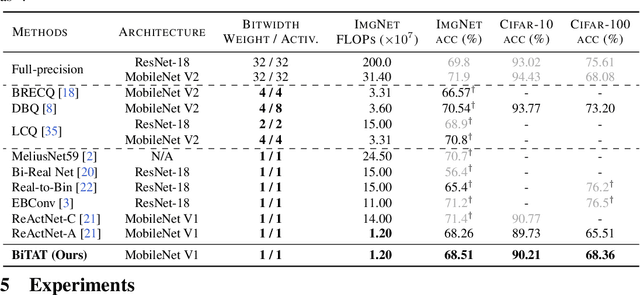
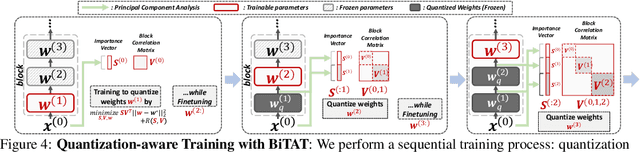
Neural network quantization aims to transform high-precision weights and activations of a given neural network into low-precision weights/activations for reduced memory usage and computation, while preserving the performance of the original model. However, extreme quantization (1-bit weight/1-bit activations) of compactly-designed backbone architectures (e.g., MobileNets) often used for edge-device deployments results in severe performance degeneration. This paper proposes a novel Quantization-Aware Training (QAT) method that can effectively alleviate performance degeneration even with extreme quantization by focusing on the inter-weight dependencies, between the weights within each layer and across consecutive layers. To minimize the quantization impact of each weight on others, we perform an orthonormal transformation of the weights at each layer by training an input-dependent correlation matrix and importance vector, such that each weight is disentangled from the others. Then, we quantize the weights based on their importance to minimize the loss of the information from the original weights/activations. We further perform progressive layer-wise quantization from the bottom layer to the top, so that quantization at each layer reflects the quantized distributions of weights and activations at previous layers. We validate the effectiveness of our method on various benchmark datasets against strong neural quantization baselines, demonstrating that it alleviates the performance degeneration on ImageNet and successfully preserves the full-precision model performance on CIFAR-100 with compact backbone networks.
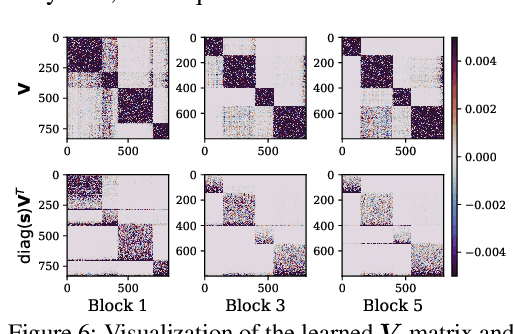
Bitwidth Heterogeneous Federated Learning with Progressive Weight Dequantization
Mar 04, 2022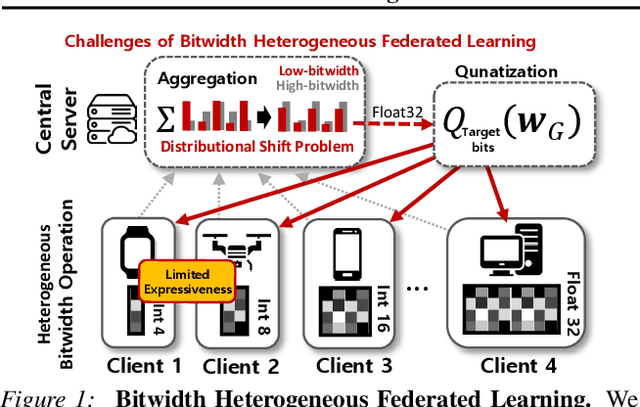

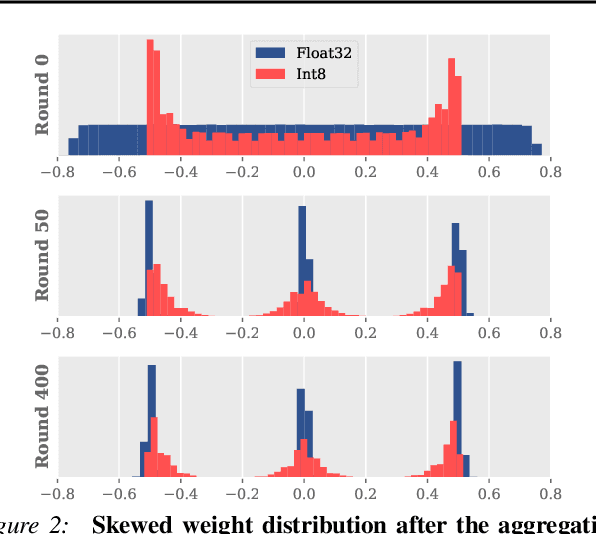
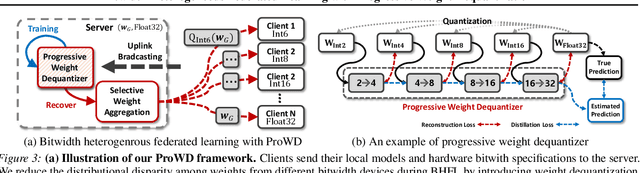
In practical federated learning scenarios, the participating devices may have different bitwidths for computation and memory storage by design. However, despite the progress made in device-heterogeneous federated learning scenarios, the heterogeneity in the bitwidth specifications in the hardware has been mostly overlooked. We introduce a pragmatic FL scenario with bitwidth heterogeneity across the participating devices, dubbed as Bitwidth Heterogeneous Federated Learning (BHFL). BHFL brings in a new challenge, that the aggregation of model parameters with different bitwidths could result in severe performance degeneration, especially for high-bitwidth models. To tackle this problem, we propose ProWD framework, which has a trainable weight dequantizer at the central server that progressively reconstructs the low-bitwidth weights into higher bitwidth weights, and finally into full-precision weights. ProWD further selectively aggregates the model parameters to maximize the compatibility across bit-heterogeneous weights. We validate ProWD against relevant FL baselines on the benchmark datasets, using clients with varying bitwidths. Our ProWD largely outperforms the baseline FL algorithms as well as naive approaches (e.g. grouped averaging) under the proposed BHFL scenario.