 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Predictor: Performance Prediction for Agentic Workflows via Multi-View Encoding
May 26, 2025



Large language models (LLMs) have demonstrated remarkable capabilities across diverse tasks, but optimizing LLM-based agentic systems remains challenging due to the vast search space of agent configurations, prompting strategies, and communication patterns. Existing approaches often rely on heuristic-based tuning or exhaustive evaluation, which can be computationally expensive and suboptimal. This paper proposes Agentic Predictor, a lightweight predictor for efficient agentic workflow evaluation. Agentic Predictor is equipped with a multi-view workflow encoding technique that leverages multi-view representation learning of agentic systems by incorporating code architecture, textual prompts, and interaction graph features. To achieve high predictive accuracy while significantly reducing the number of required workflow evaluations for training a predictor, Agentic Predictor employs cross-domain unsupervised pretraining. By learning to approximate task success rates, Agentic Predictor enables fast and accurate selection of optimal agentic workflow configurations for a given task, significantly reducing the need for expensive trial-and-error evaluations. Experiments on a carefully curated benchmark spanning three domains show that our predictor outperforms state-of-the-art methods in both predictive accuracy and workflow utility, highlighting the potential of performance predictors in streamlining the design of LLM-based agentic workflows.
AutoML-Agent: A Multi-Agent LLM Framework for Full-Pipeline AutoML
Oct 03, 2024



Automated machine learning (AutoML) accelerates AI development by automating tasks in the development pipeline, such as optimal model search and hyperparameter tuning. Existing AutoML systems often require technical expertise to set up complex tools, which is in general time-consuming and requires a large amount of human effort. Therefore, recent works have started exploiting large language models (LLM) to lessen such burden and increase the usability of AutoML frameworks via a natural language interface, allowing non-expert users to build their data-driven solutions. These methods, however, are usually designed only for a particular process in the AI development pipeline and do not efficiently use the inherent capacity of the LLMs. This paper proposes AutoML-Agent, a novel multi-agent framework tailored for full-pipeline AutoML, i.e., from data retrieval to model deployment. AutoML-Agent takes user's task descriptions, facilitates collaboration between specialized LLM agents, and delivers deployment-ready models. Unlike existing work, instead of devising a single plan, we introduce a retrieval-augmented planning strategy to enhance exploration to search for more optimal plans. We also decompose each plan into sub-tasks (e.g., data preprocessing and neural network design) each of which is solved by a specialized agent we build via prompting executing in parallel, making the search process more efficient. Moreover, we propose a multi-stage verification to verify executed results and guide the code generation LLM in implementing successful solutions. Extensive experiments on seven downstream tasks using fourteen datasets show that AutoML-Agent achieves a higher success rate in automating the full AutoML process, yielding systems with good performance throughout the diverse domains.
Personalized Subgraph Federated Learning
Jun 21, 2022
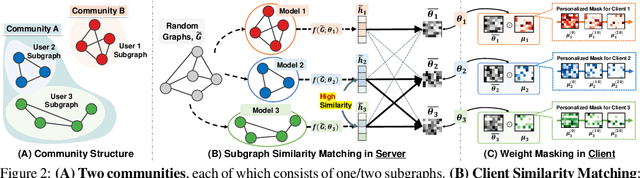


In real-world scenarios, subgraphs of a larger global graph may be distributed across multiple devices or institutions, and only locally accessible due to privacy restrictions, although there may be links between them. Recently proposed subgraph Federated Learning (FL) methods deal with those missing links across private local subgraphs while distributively training Graph Neural Networks (GNNs) on them. However, they have overlooked the inevitable heterogeneity among subgraphs, caused by subgraphs comprising different parts of a global graph. For example, a subgraph may belong to one of the communities within the larger global graph. A naive subgraph FL in such a case will collapse incompatible knowledge from local GNN models trained on heterogeneous graph distributions. To overcome such a limitation, we introduce a new subgraph FL problem, personalized subgraph FL, which focuses on the joint improvement of the interrelated local GNN models rather than learning a single global GNN model, and propose a novel framework, FEDerated Personalized sUBgraph learning (FED-PUB), to tackle it. A crucial challenge in personalized subgraph FL is that the server does not know which subgraph each client has. FED-PUB thus utilizes functional embeddings of the local GNNs using random graphs as inputs to compute similarities between them, and use them to perform weighted averaging for server-side aggregation. Further, it learns a personalized sparse mask at each client to select and update only the subgraph-relevant subset of the aggregated parameters. We validate FED-PUB for its subgraph FL performance on six datasets, considering both non-overlapping and overlapping subgraphs, on which ours largely outperforms relevant baselines.
Bitwidth Heterogeneous Federated Learning with Progressive Weight Dequantization
Mar 04, 2022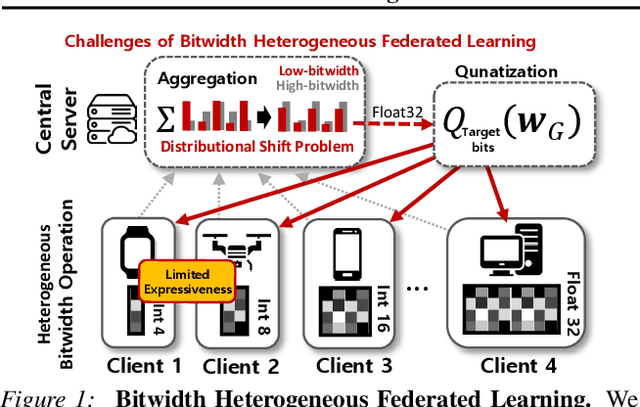

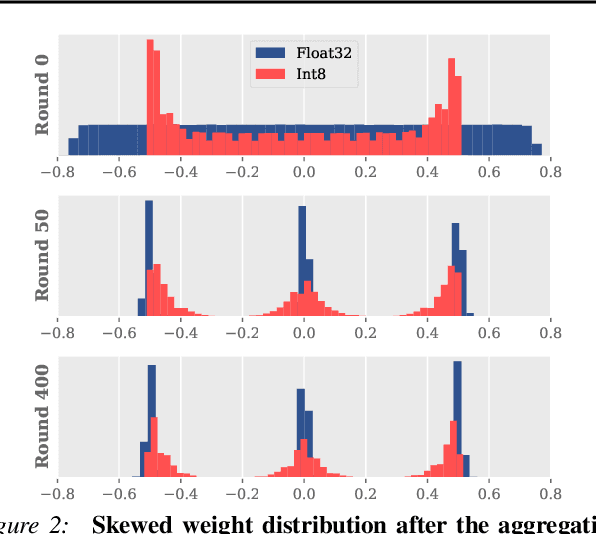
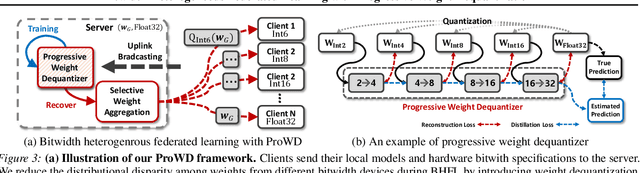
In practical federated learning scenarios, the participating devices may have different bitwidths for computation and memory storage by design. However, despite the progress made in device-heterogeneous federated learning scenarios, the heterogeneity in the bitwidth specifications in the hardware has been mostly overlooked. We introduce a pragmatic FL scenario with bitwidth heterogeneity across the participating devices, dubbed as Bitwidth Heterogeneous Federated Learning (BHFL). BHFL brings in a new challenge, that the aggregation of model parameters with different bitwidths could result in severe performance degeneration, especially for high-bitwidth models. To tackle this problem, we propose ProWD framework, which has a trainable weight dequantizer at the central server that progressively reconstructs the low-bitwidth weights into higher bitwidth weights, and finally into full-precision weights. ProWD further selectively aggregates the model parameters to maximize the compatibility across bit-heterogeneous weights. We validate ProWD against relevant FL baselines on the benchmark datasets, using clients with varying bitwidths. Our ProWD largely outperforms the baseline FL algorithms as well as naive approaches (e.g. grouped averaging) under the proposed BHFL scenario.
Factorized-FL: Agnostic Personalized Federated Learning with Kernel Factorization & Similarity Matching
Feb 01, 2022

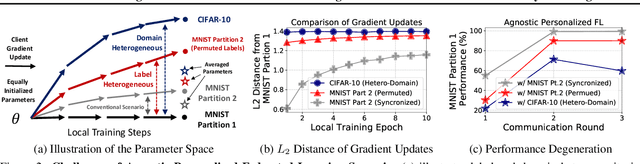

In real-world federated learning scenarios, participants could have their own personalized labels which are incompatible with those from other clients, due to using different label permutations or tackling completely different tasks or domains. However, most existing FL approaches cannot effectively tackle such extremely heterogeneous scenarios since they often assume that (1) all participants use a synchronized set of labels, and (2) they train on the same task from the same domain. In this work, to tackle these challenges, we introduce Factorized-FL, which allows to effectively tackle label- and task-heterogeneous federated learning settings by factorizing the model parameters into a pair of vectors, where one captures the common knowledge across different labels and tasks and the other captures knowledge specific to the task each local model tackles. Moreover, based on the distance in the client-specific vector space, Factorized-FL performs selective aggregation scheme to utilize only the knowledge from the relevant participants for each client. We extensively validate our method on both label- and domain-heterogeneous settings, on which it outperforms the state-of-the-art personalized federated learning methods.
Task-Adaptive Neural Network Retrieval with Meta-Contrastive Learning
Mar 02, 2021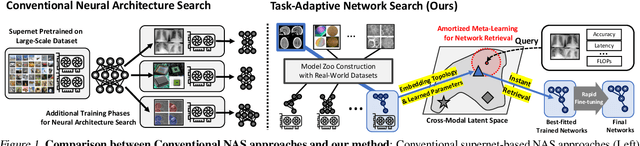
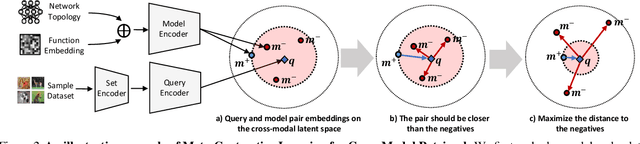
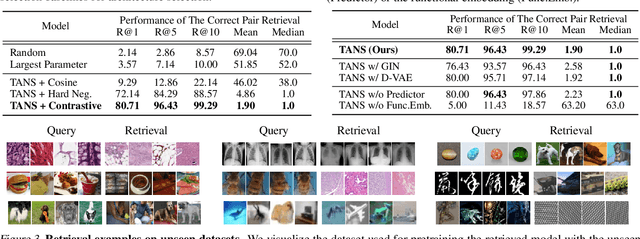
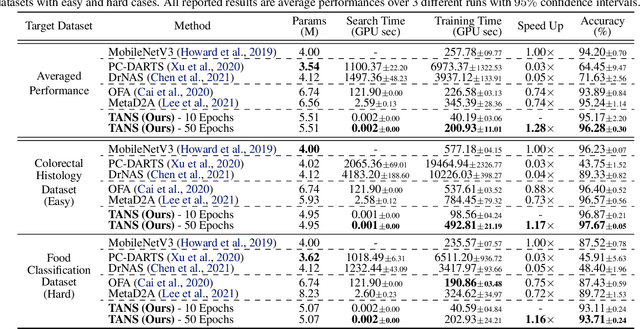
Most conventional Neural Architecture Search (NAS) approaches are limited in that they only generate architectures (network topologies) without searching for optimal parameters. While some NAS methods handle this issue by utilizing a supernet trained on a large-scale dataset such as ImageNet, they may be suboptimal if the target tasks are highly dissimilar from the dataset the supernet is trained on. To tackle this issue, we propose a novel neural network retrieval method, which retrieves the most optimal pre-trained network for a given task and constraints (e.g. number of parameters) from a model zoo. We train this framework by meta-learning a cross-modal latent space with contrastive loss, to maximize the similarity between a dataset and a network that obtains high performance on it, and minimize the similarity between an irrelevant dataset-network pair. We validate the efficacy of our method on ten real-world datasets, against existing NAS baselines. The results show that our method instantly retrieves networks that outperforms models obtained with the baselines with significantly fewer training steps to reach the target performance.
Federated Semi-Supervised Learning with Inter-Client Consistency
Jul 14, 2020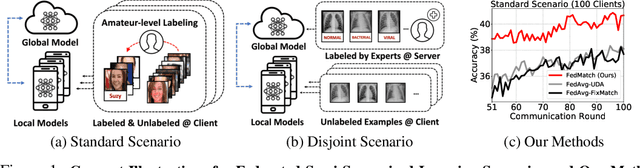

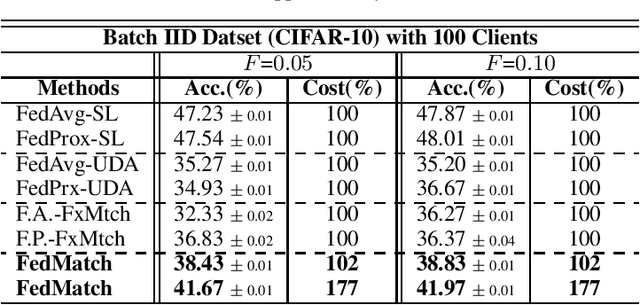

While existing federated learning approaches mostly require that clients have fully-labeled data to train on, in realistic settings, data obtained at the client side often comes without any accompanying labels. Such deficiency of labels may result from either high labeling cost, or difficulty of annotation due to requirement of expert knowledge. Thus the private data at each client may be only partly labeled, or completely unlabeled with labeled data being available only at the server, which leads us to a new problem of Federated Semi-Supervised Learning (FSSL). In this work, we study this new problem of semi-supervised learning under federated learning framework, and propose a novel method to tackle it, which we refer to as Federated Matching (FedMatch). FedMatch improves upon naive federated semi-supervised learning approaches with a new inter-client consistency loss and decomposition of the parameters into parameters for labeled and unlabeled data. Through extensive experimental validation of our method in two different scenarios, we show that our method outperforms both local semi-supervised learning and baselines which naively combine federated learning with semi-supervised learning.
Federated Continual Learning with Adaptive Parameter Communication
Mar 10, 2020
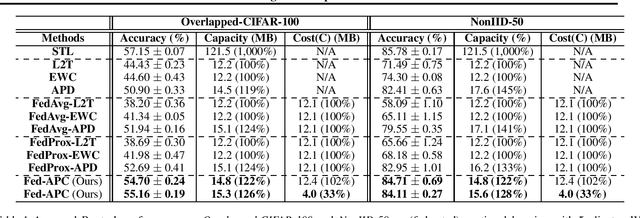


There has been a surge of interest in continual learning and federated learning, both of which are important in training deep neural networks in real-world scenarios. Yet little research has been done regarding the scenario where each client learns on a sequence of tasks from private local data. This problem of federated continual learning poses new challenges to continual learning, such as utilizing knowledge and preventing interference from tasks learned on other clients. To resolve these issues, we propose a novel federated continual learning framework, Federated continual learning with Adaptive Parameter Communication, which additively decomposes the network weights into global shared parameters and sparse task-specific parameters. This decomposition allows to minimize interference between incompatible tasks, and also allows inter-client knowledge transfer by communicating the sparse task-specific parameters. Our federated continual learning framework is also communication-efficient, due to high sparsity of the parameters and sparse parameter update. We validate APC against existing federated learning and local continual learning methods under varying degrees of task similarity across clients, and show that our model significantly outperforms them with a large reduction in the communication cost.