 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Neural Architecture Search by Learning to Generate Graphs from Datasets
Jul 02, 2021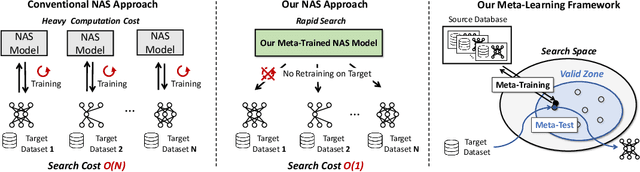
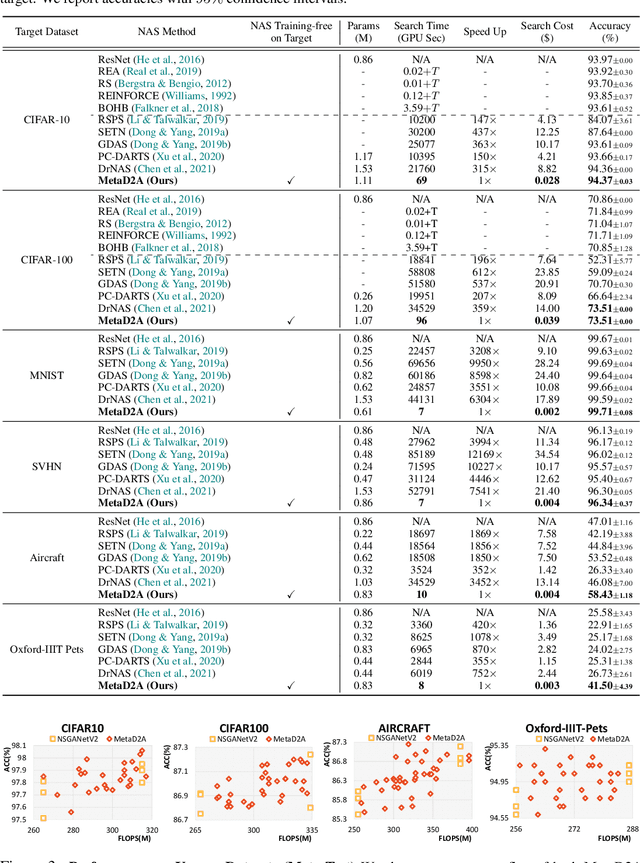
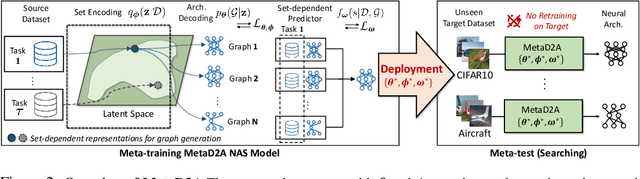
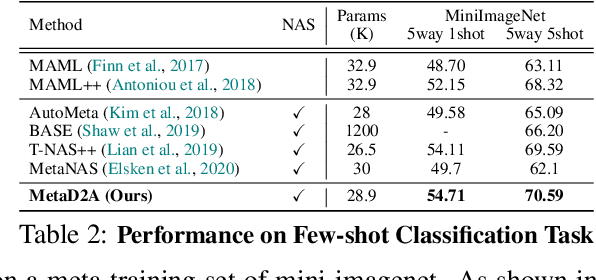
Despite the success of recent Neural Architecture Search (NAS) methods on various tasks which have shown to output networks that largely outperform human-designed networks, conventional NAS methods have mostly tackled the optimization of searching for the network architecture for a single task (dataset), which does not generalize well across multiple tasks (datasets). Moreover, since such task-specific methods search for a neural architecture from scratch for every given task, they incur a large computational cost, which is problematic when the time and monetary budget are limited. In this paper, we propose an efficient NAS framework that is trained once on a database consisting of datasets and pretrained networks and can rapidly search for a neural architecture for a novel dataset. The proposed MetaD2A (Meta Dataset-to-Architecture) model can stochastically generate graphs (architectures) from a given set (dataset) via a cross-modal latent space learned with amortized meta-learning. Moreover, we also propose a meta-performance predictor to estimate and select the best architecture without direct training on target datasets. The experimental results demonstrate that our model meta-learned on subsets of ImageNet-1K and architectures from NAS-Bench 201 search space successfully generalizes to multiple unseen datasets including CIFAR-10 and CIFAR-100, with an average search time of 33 GPU seconds. Even under MobileNetV3 search space, MetaD2A is 5.5K times faster than NSGANetV2, a transferable NAS method, with comparable performance. We believe that the MetaD2A proposes a new research direction for rapid NAS as well as ways to utilize the knowledge from rich databases of datasets and architectures accumulated over the past years. Code is available at https://github.com/HayeonLee/MetaD2A.
Task-Adaptive Neural Network Retrieval with Meta-Contrastive Learning
Mar 02, 2021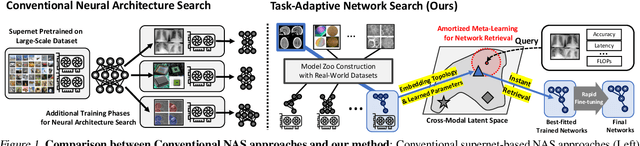
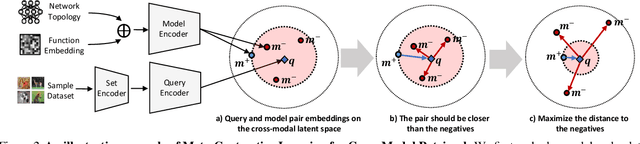
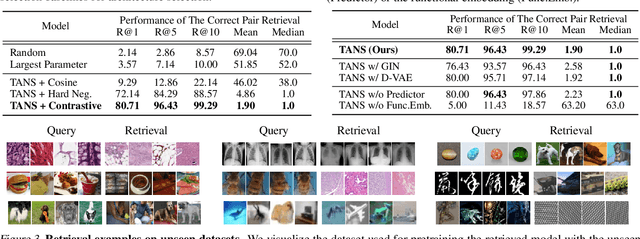
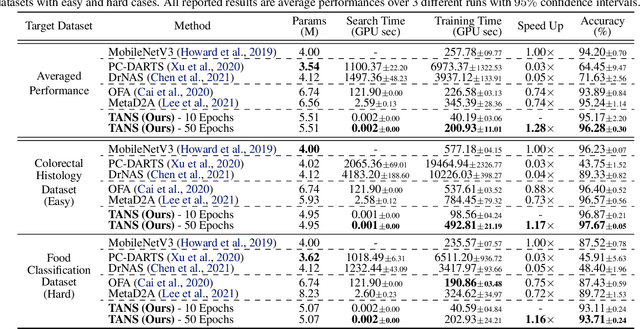
Most conventional Neural Architecture Search (NAS) approaches are limited in that they only generate architectures (network topologies) without searching for optimal parameters. While some NAS methods handle this issue by utilizing a supernet trained on a large-scale dataset such as ImageNet, they may be suboptimal if the target tasks are highly dissimilar from the dataset the supernet is trained on. To tackle this issue, we propose a novel neural network retrieval method, which retrieves the most optimal pre-trained network for a given task and constraints (e.g. number of parameters) from a model zoo. We train this framework by meta-learning a cross-modal latent space with contrastive loss, to maximize the similarity between a dataset and a network that obtains high performance on it, and minimize the similarity between an irrelevant dataset-network pair. We validate the efficacy of our method on ten real-world datasets, against existing NAS baselines. The results show that our method instantly retrieves networks that outperforms models obtained with the baselines with significantly fewer training steps to reach the target performance.