 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTesting using Privileged Information by Adapting Features with Statistical Dependence
Paper and Code
Nov 04, 2021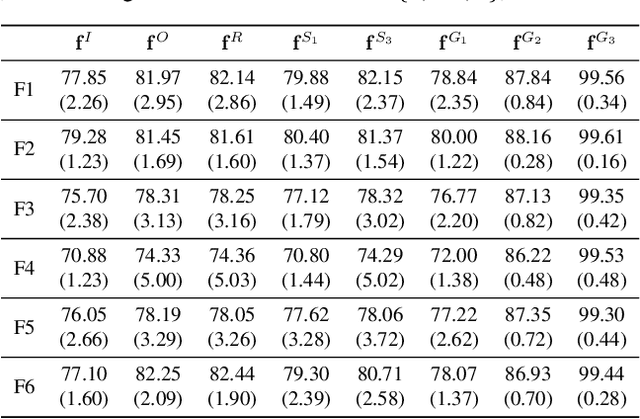
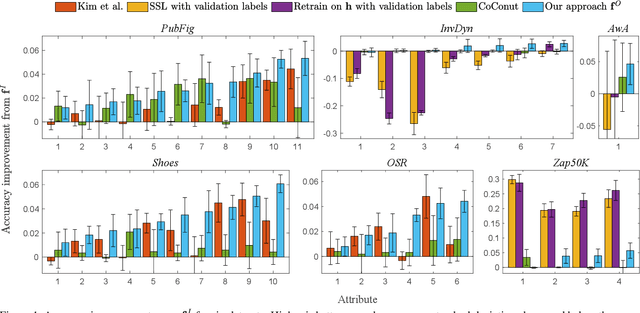
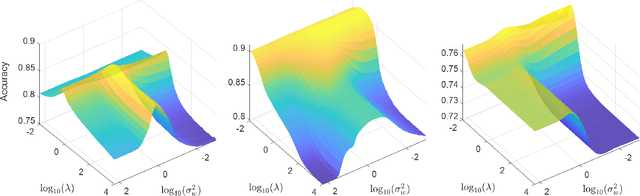
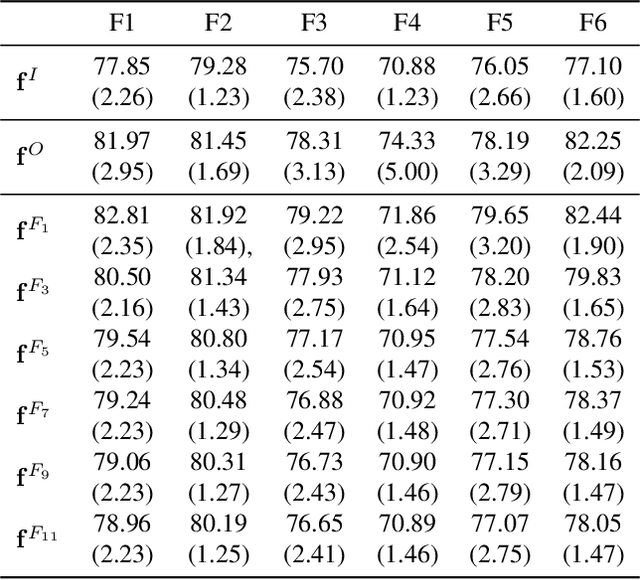
Given an imperfect predictor, we exploit additional features at test time to improve the predictions made, without retraining and without knowledge of the prediction function. This scenario arises if training labels or data are proprietary, restricted, or no longer available, or if training itself is prohibitively expensive. We assume that the additional features are useful if they exhibit strong statistical dependence to the underlying perfect predictor. Then, we empirically estimate and strengthen the statistical dependence between the initial noisy predictor and the additional features via manifold denoising. As an example, we show that this approach leads to improvement in real-world visual attribute ranking. Project webpage: http://www.jamestompkin.com/tupi