 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"When to Hand Off, When to Work Together": Expanding Human-Agent Co-Creative Collaboration through Concurrent Interaction
Mar 02, 2026Human collaborators coordinate dynamically through process visibility and workspace awareness, yet AI agents typically either provide only final outputs or expose read-only execution processes (e.g., planning, reasoning) without interpreting concurrent user actions on shared artifacts. Building on mixed-initiative interaction principles, we explore whether agents can achieve collaborative context awareness -- interpreting concurrent user actions on shared artifacts and adapting in real-time. Study 1 (N=10 professional designers) revealed that process visibility enabled reasoning about agent actions but exposed conflicts when agents could not distinguish feedback from independent work. We developed CLEO, which interprets collaborative intent and adapts in real-time. Study 2 (N=10, two-day with stimulated recall interviews) analyzed 214 turns, identifying five action patterns, six triggers, and four enabling factors explaining when designers choose delegation (70.1%), direction (28.5%), or concurrent work (31.8%). We present a decision model with six interaction loops, design implications, and an annotated dataset.
ClearFairy: Capturing Creative Workflows through Decision Structuring, In-Situ Questioning, and Rationale Inference
Sep 18, 2025Capturing professionals' decision-making in creative workflows is essential for reflection, collaboration, and knowledge sharing, yet existing methods often leave rationales incomplete and implicit decisions hidden. To address this, we present CLEAR framework that structures reasoning into cognitive decision steps-linked units of actions, artifacts, and self-explanations that make decisions traceable. Building on this framework, we introduce ClearFairy, a think-aloud AI assistant for UI design that detects weak explanations, asks lightweight clarifying questions, and infers missing rationales to ease the knowledge-sharing burden. In a study with twelve creative professionals, 85% of ClearFairy's inferred rationales were accepted, increasing strong explanations from 14% to over 83% of decision steps without adding cognitive demand. The captured steps also enhanced generative AI agents in Figma, yielding next-action predictions better aligned with professionals and producing more coherent design outcomes. For future research on human knowledge-grounded creative AI agents, we release a dataset of captured 417 decision steps.
Beyond Prompts: Learning from Human Communication for Enhanced AI Intent Alignment
May 09, 2024AI intent alignment, ensuring that AI produces outcomes as intended by users, is a critical challenge in human-AI interaction. The emergence of generative AI, including LLMs, has intensified the significance of this problem, as interactions increasingly involve users specifying desired results for AI systems. In order to support better AI intent alignment, we aim to explore human strategies for intent specification in human-human communication. By studying and comparing human-human and human-LLM communication, we identify key strategies that can be applied to the design of AI systems that are more effective at understanding and aligning with user intent. This study aims to advance toward a human-centered AI system by bringing together human communication strategies for the design of AI systems.
One vs. Many: Comprehending Accurate Information from Multiple Erroneous and Inconsistent AI Generations
May 09, 2024
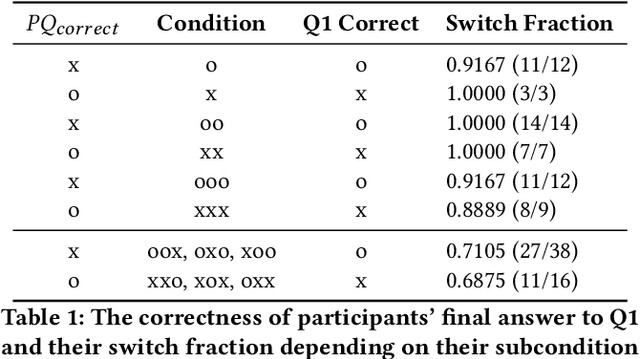
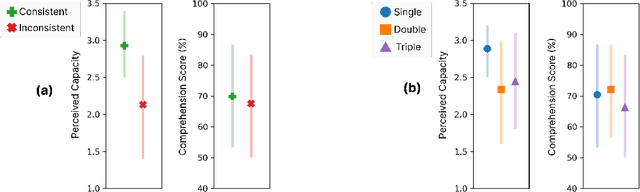
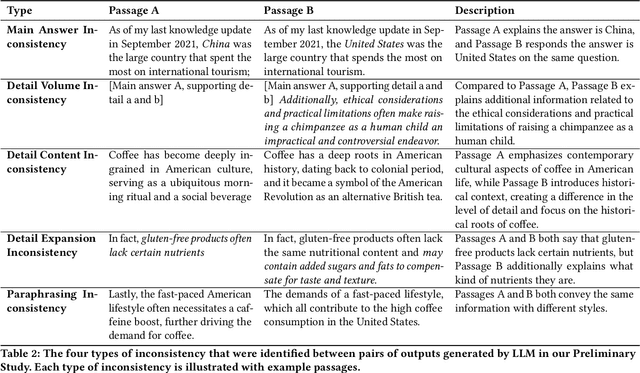
As Large Language Models (LLMs) are nondeterministic, the same input can generate different outputs, some of which may be incorrect or hallucinated. If run again, the LLM may correct itself and produce the correct answer. Unfortunately, most LLM-powered systems resort to single results which, correct or not, users accept. Having the LLM produce multiple outputs may help identify disagreements or alternatives. However, it is not obvious how the user will interpret conflicts or inconsistencies. To this end, we investigate how users perceive the AI model and comprehend the generated information when they receive multiple, potentially inconsistent, outputs. Through a preliminary study, we identified five types of output inconsistencies. Based on these categories, we conducted a study (N=252) in which participants were given one or more LLM-generated passages to an information-seeking question. We found that inconsistency within multiple LLM-generated outputs lowered the participants' perceived AI capacity, while also increasing their comprehension of the given information. Specifically, we observed that this positive effect of inconsistencies was most significant for participants who read two passages, compared to those who read three. Based on these findings, we present design implications that, instead of regarding LLM output inconsistencies as a drawback, we can reveal the potential inconsistencies to transparently indicate the limitations of these models and promote critical LLM usage.