 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Evaluation of Prompting and Fine-Tuning for Applying Large Language Models to Grid-Structured Geospatial Data
May 21, 2025This paper presents a comparative study of large language models (LLMs) in interpreting grid-structured geospatial data. We evaluate the performance of a base model through structured prompting and contrast it with a fine-tuned variant trained on a dataset of user-assistant interactions. Our results highlight the strengths and limitations of zero-shot prompting and demonstrate the benefits of fine-tuning for structured geospatial and temporal reasoning.
Leveraging Large Language Models for Code Translation and Software Development in Scientific Computing
Oct 31, 2024The emergence of foundational models and generative artificial intelligence (GenAI) is poised to transform productivity in scientific computing, especially in code development, refactoring, and translating from one programming language to another. However, because the output of GenAI cannot be guaranteed to be correct, manual intervention remains necessary. Some of this intervention can be automated through task-specific tools, alongside additional methodologies for correctness verification and effective prompt development. We explored the application of GenAI in assisting with code translation, language interoperability, and codebase inspection within a legacy Fortran codebase used to simulate particle interactions at the Large Hadron Collider (LHC). In the process, we developed a tool, CodeScribe, which combines prompt engineering with user supervision to establish an efficient process for code conversion. In this paper, we demonstrate how CodeScribe assists in converting Fortran code to C++, generating Fortran-C APIs for integrating legacy systems with modern C++ libraries, and providing developer support for code organization and algorithm implementation. We also address the challenges of AI-driven code translation and highlight its benefits for enhancing productivity in scientific computing workflows.
BubbleML: A Multi-Physics Dataset and Benchmarks for Machine Learning
Jul 27, 2023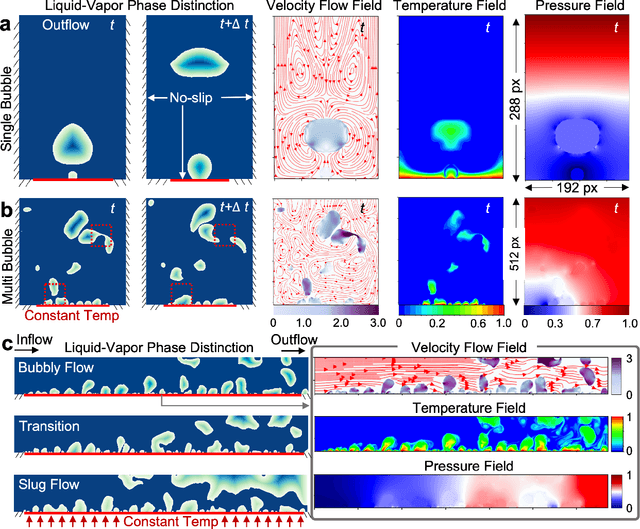

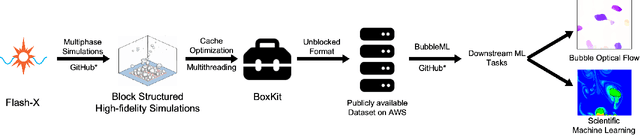

In the field of phase change phenomena, the lack of accessible and diverse datasets suitable for machine learning (ML) training poses a significant challenge. Existing experimental datasets are often restricted, with limited availability and sparse ground truth data, impeding our understanding of this complex multi-physics phenomena. To bridge this gap, we present the BubbleML Dataset(https://github.com/HPCForge/BubbleML) which leverages physics-driven simulations to provide accurate ground truth information for various boiling scenarios, encompassing nucleate pool boiling, flow boiling, and sub-cooled boiling. This extensive dataset covers a wide range of parameters, including varying gravity conditions, flow rates, sub-cooling levels, and wall superheat, comprising 51 simulations. BubbleML is validated against experimental observations and trends, establishing it as an invaluable resource for ML research. Furthermore, we showcase its potential to facilitate exploration of diverse downstream tasks by introducing two benchmarks: (a) optical flow analysis to capture bubble dynamics, and (b) operator networks for learning temperature dynamics. The BubbleML dataset and its benchmarks serve as a catalyst for advancements in ML-driven research on multi-physics phase change phenomena, enabling the development and comparison of state-of-the-art techniques and models.