 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKULTURE Bench: A Benchmark for Assessing Language Model in Korean Cultural Context
Dec 10, 2024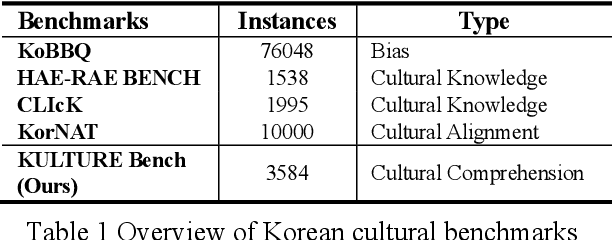


Large language models have exhibited significant enhancements in performance across various tasks. However, the complexity of their evaluation increases as these models generate more fluent and coherent content. Current multilingual benchmarks often use translated English versions, which may incorporate Western cultural biases that do not accurately assess other languages and cultures. To address this research gap, we introduce KULTURE Bench, an evaluation framework specifically designed for Korean culture that features datasets of cultural news, idioms, and poetry. It is designed to assess language models' cultural comprehension and reasoning capabilities at the word, sentence, and paragraph levels. Using the KULTURE Bench, we assessed the capabilities of models trained with different language corpora and analyzed the results comprehensively. The results show that there is still significant room for improvement in the models' understanding of texts related to the deeper aspects of Korean culture.
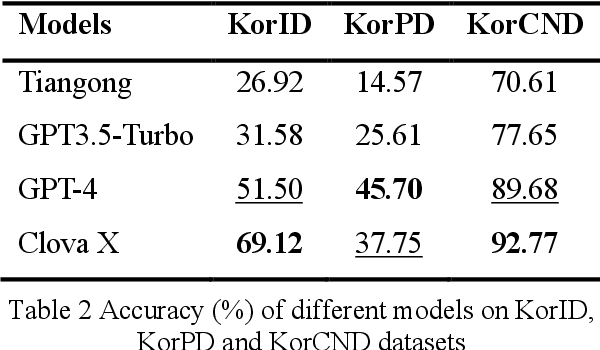
Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on Korean
Mar 21, 2024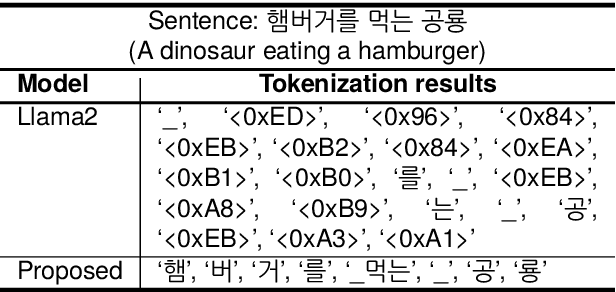
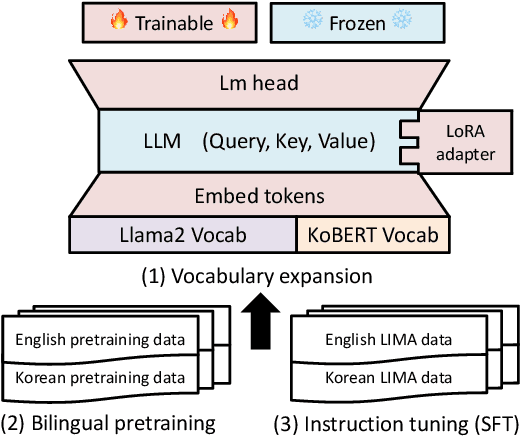

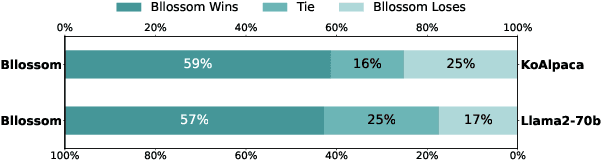
Large language models (LLMs) use pretraining to predict the subsequent word; however, their expansion requires significant computing resources. Numerous big tech companies and research institutes have developed multilingual LLMs (MLLMs) to meet current demands, overlooking less-resourced languages (LRLs). This study proposed three strategies to enhance the performance of LRLs based on the publicly available MLLMs. First, the MLLM vocabularies of LRLs were expanded to enhance expressiveness. Second, bilingual data were used for pretraining to align the high- and less-resourced languages. Third, a high-quality small-scale instruction dataset was constructed and instruction-tuning was performed to augment the LRL. The experiments employed the Llama2 model and Korean was used as the LRL, which was quantitatively evaluated against other developed LLMs across eight tasks. Furthermore, a qualitative assessment was performed based on human evaluation and GPT4. Experimental results showed that our proposed Bllossom model exhibited superior performance in qualitative analyses compared to previously proposed Korean monolingual models.
Analysis of the Penn Korean Universal Dependency Treebank (PKT-UD): Manual Revision to Build Robust Parsing Model in Korean
May 26, 2020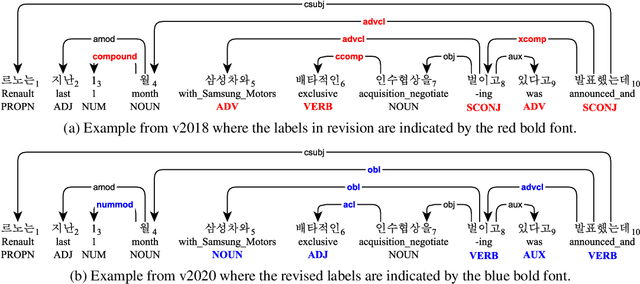
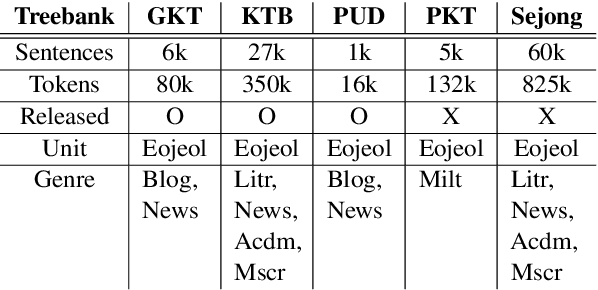
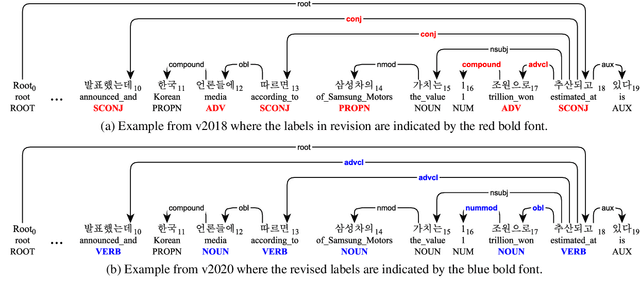
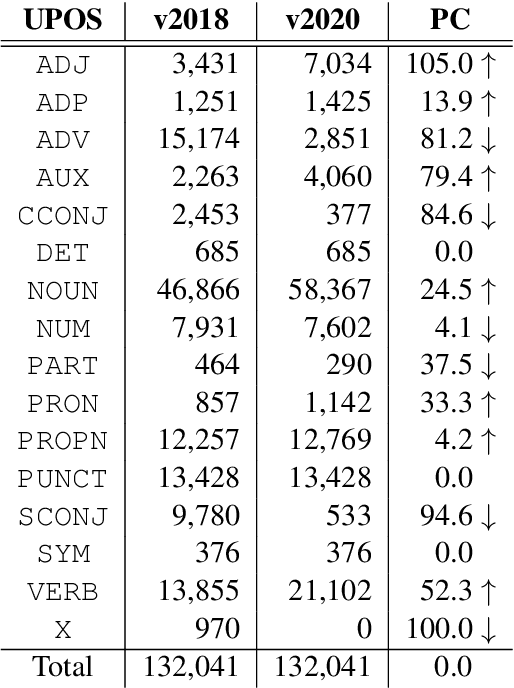
In this paper, we first open on important issues regarding the Penn Korean Universal Treebank (PKT-UD) and address these issues by revising the entire corpus manually with the aim of producing cleaner UD annotations that are more faithful to Korean grammar. For compatibility to the rest of UD corpora, we follow the UDv2 guidelines, and extensively revise the part-of-speech tags and the dependency relations to reflect morphological features and flexible word-order aspects in Korean. The original and the revised versions of PKT-UD are experimented with transformer-based parsing models using biaffine attention. The parsing model trained on the revised corpus shows a significant improvement of 3.0% in labeled attachment score over the model trained on the previous corpus. Our error analysis demonstrates that this revision allows the parsing model to learn relations more robustly, reducing several critical errors that used to be made by the previous model.