 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploitation of Channel-Learning for Enhancing 5G Blind Beam Index Detection
Dec 07, 2020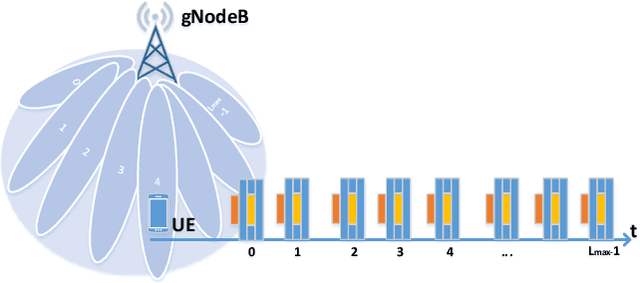
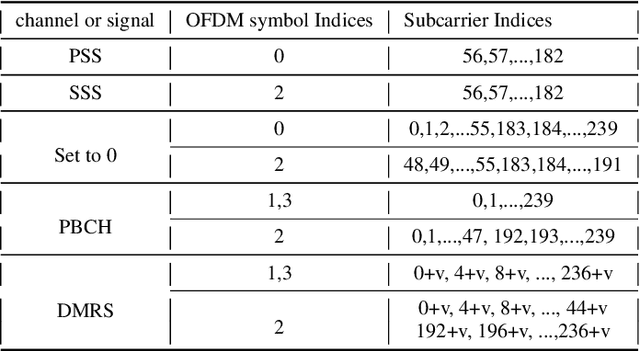
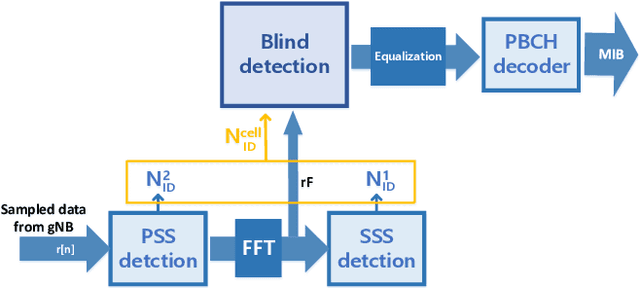

Proliferation of 5G devices and services has driven the demand for wide-scale enhancements ranging from data rate, reliability, and compatibility to sustain the ever increasing growth of the telecommunication industry. In this regard, this work investigates how machine learning technology can improve the performance of 5G cell and beam index search in practice. The cell search is an essential function for a User Equipment (UE) to be initially associated with a base station, and is also important to further maintain the wireless connection. Unlike the former generation cellular systems, the 5G UE faces with an additional challenge to detect suitable beams as well as the cell identities in the cell search procedures. Herein, we propose and implement new channel-learning schemes to enhance the performance of 5G beam index detection. The salient point lies in the use of machine learning models and softwarization for practical implementations in a system level. We develop the proposed channel-learning scheme including algorithmic procedures and corroborative system structure for efficient beam index detection. We also implement a real-time operating 5G testbed based on the off-the-shelf Software Defined Radio (SDR) platform and conduct intensive experiments with commercial 5G base stations. The experimental results indicate that the proposed channel-learning schemes outperform the conventional correlation-based scheme in real 5G channel environments.
Analysis of the Penn Korean Universal Dependency Treebank (PKT-UD): Manual Revision to Build Robust Parsing Model in Korean
May 26, 2020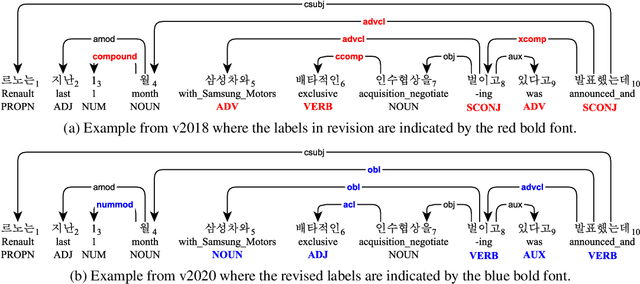
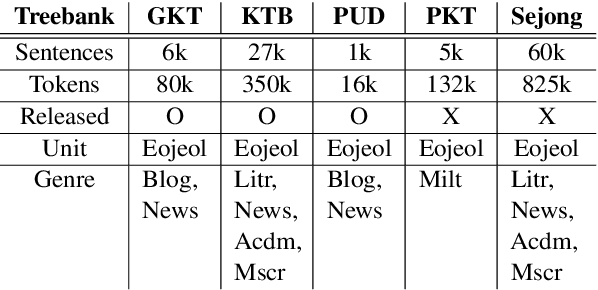
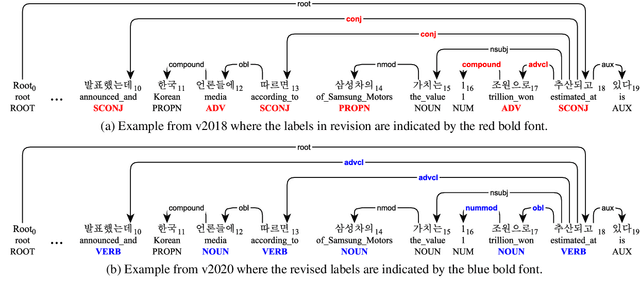
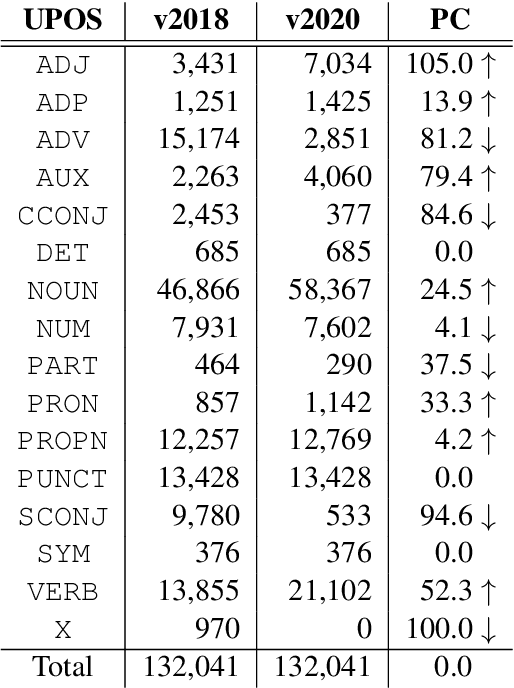
In this paper, we first open on important issues regarding the Penn Korean Universal Treebank (PKT-UD) and address these issues by revising the entire corpus manually with the aim of producing cleaner UD annotations that are more faithful to Korean grammar. For compatibility to the rest of UD corpora, we follow the UDv2 guidelines, and extensively revise the part-of-speech tags and the dependency relations to reflect morphological features and flexible word-order aspects in Korean. The original and the revised versions of PKT-UD are experimented with transformer-based parsing models using biaffine attention. The parsing model trained on the revised corpus shows a significant improvement of 3.0% in labeled attachment score over the model trained on the previous corpus. Our error analysis demonstrates that this revision allows the parsing model to learn relations more robustly, reducing several critical errors that used to be made by the previous model.