 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Curious Class of Adpositional Multiword Expressions in Korean
Feb 17, 2026Multiword expressions (MWEs) have been widely studied in cross-lingual annotation frameworks such as PARSEME. However, Korean MWEs remain underrepresented in these efforts. In particular, Korean multiword adpositions lack systematic analysis, annotated resources, and integration into existing multilingual frameworks. In this paper, we study a class of Korean functional multiword expressions: postpositional verb-based constructions (PVCs). Using data from Korean Wikipedia, we survey and analyze several PVC expressions and contrast them with non-MWEs and light verb constructions (LVCs) with similar structure. Building on this analysis, we propose annotation guidelines designed to support future work in Korean multiword adpositions and facilitate alignment with cross-lingual frameworks.
Analysis of the Penn Korean Universal Dependency Treebank (PKT-UD): Manual Revision to Build Robust Parsing Model in Korean
May 26, 2020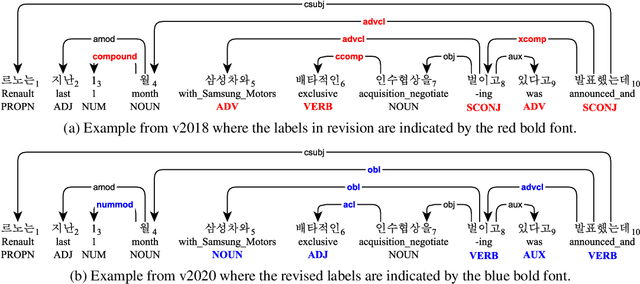
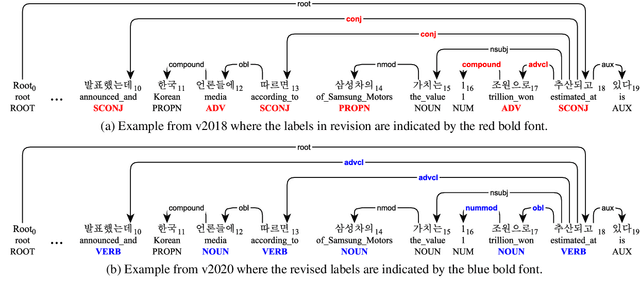
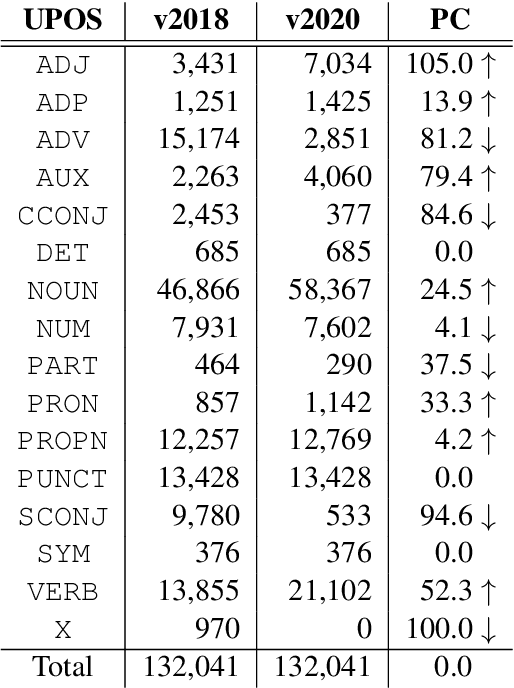
In this paper, we first open on important issues regarding the Penn Korean Universal Treebank (PKT-UD) and address these issues by revising the entire corpus manually with the aim of producing cleaner UD annotations that are more faithful to Korean grammar. For compatibility to the rest of UD corpora, we follow the UDv2 guidelines, and extensively revise the part-of-speech tags and the dependency relations to reflect morphological features and flexible word-order aspects in Korean. The original and the revised versions of PKT-UD are experimented with transformer-based parsing models using biaffine attention. The parsing model trained on the revised corpus shows a significant improvement of 3.0% in labeled attachment score over the model trained on the previous corpus. Our error analysis demonstrates that this revision allows the parsing model to learn relations more robustly, reducing several critical errors that used to be made by the previous model.
Adposition and Case Supersenses v2: Guidelines for English
Jul 02, 2018This document offers a detailed linguistic description of SNACS (Semantic Network of Adposition and Case Supersenses; Schneider et al., 2018), an inventory of 50 semantic labels ("supersenses") that characterize the use of adpositions and case markers at a somewhat coarse level of granularity, as demonstrated in the STREUSLE 4.1 corpus (https://github.com/nert-gu/streusle/). Though the SNACS inventory aspires to be universal, this document is specific to English; documentation for other languages will be published separately. Version 2 is a revision of the supersense inventory proposed for English by Schneider et al. (2015, 2016) (henceforth "v1"), which in turn was based on previous schemes. The present inventory was developed after extensive review of the v1 corpus annotations for English, plus previously unanalyzed genitive case possessives (Blodgett and Schneider, 2018), as well as consideration of adposition and case phenomena in Hebrew, Hindi, Korean, and German. Hwang et al. (2017) present the theoretical underpinnings of the v2 scheme. Schneider et al. (2018) summarize the scheme, its application to English corpus data, and an automatic disambiguation task.
Coping with Construals in Broad-Coverage Semantic Annotation of Adpositions
Mar 10, 2017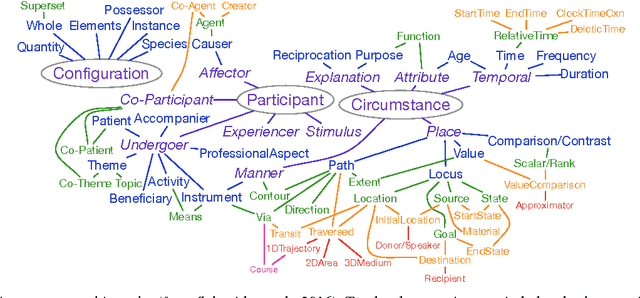
We consider the semantics of prepositions, revisiting a broad-coverage annotation scheme used for annotating all 4,250 preposition tokens in a 55,000 word corpus of English. Attempts to apply the scheme to adpositions and case markers in other languages, as well as some problematic cases in English, have led us to reconsider the assumption that a preposition's lexical contribution is equivalent to the role/relation that it mediates. Our proposal is to embrace the potential for construal in adposition use, expressing such phenomena directly at the token level to manage complexity and avoid sense proliferation. We suggest a framework to represent both the scene role and the adposition's lexical function so they can be annotated at scale---supporting automatic, statistical processing of domain-general language---and sketch how this representation would inform a constructional analysis.