 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStop-RAG: Value-Based Retrieval Control for Iterative RAG
Oct 16, 2025Iterative retrieval-augmented generation (RAG) enables large language models to answer complex multi-hop questions, but each additional loop increases latency, costs, and the risk of introducing distracting evidence, motivating the need for an efficient stopping strategy. Existing methods either use a predetermined number of iterations or rely on confidence proxies that poorly reflect whether more retrieval will actually help. We cast iterative RAG as a finite-horizon Markov decision process and introduce Stop-RAG, a value-based controller that adaptively decides when to stop retrieving. Trained with full-width forward-view Q($\lambda$) targets from complete trajectories, Stop-RAG learns effective stopping policies while remaining compatible with black-box APIs and existing pipelines. On multi-hop question-answering benchmarks, Stop-RAG consistently outperforms both fixed-iteration baselines and prompting-based stopping with LLMs. These results highlight adaptive stopping as a key missing component in current agentic systems, and demonstrate that value-based control can improve the accuracy of RAG systems.
Nonlinear Inverse Design of Mechanical Multi-Material Metamaterials Enabled by Video Denoising Diffusion and Structure Identifier
Sep 20, 2024



Metamaterials, synthetic materials with customized properties, have emerged as a promising field due to advancements in additive manufacturing. These materials derive unique mechanical properties from their internal lattice structures, which are often composed of multiple materials that repeat geometric patterns. While traditional inverse design approaches have shown potential, they struggle to map nonlinear material behavior to multiple possible structural configurations. This paper presents a novel framework leveraging video diffusion models, a type of generative artificial Intelligence (AI), for inverse multi-material design based on nonlinear stress-strain responses. Our approach consists of two key components: (1) a fields generator using a video diffusion model to create solution fields based on target nonlinear stress-strain responses, and (2) a structure identifier employing two UNet models to determine the corresponding multi-material 2D design. By incorporating multiple materials, plasticity, and large deformation, our innovative design method allows for enhanced control over the highly nonlinear mechanical behavior of metamaterials commonly seen in real-world applications. It offers a promising solution for generating next-generation metamaterials with finely tuned mechanical characteristics.
Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on Korean
Mar 21, 2024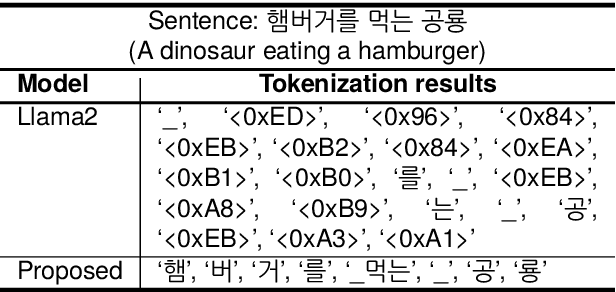
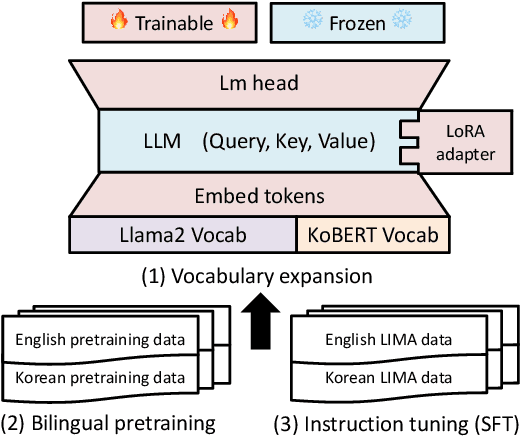

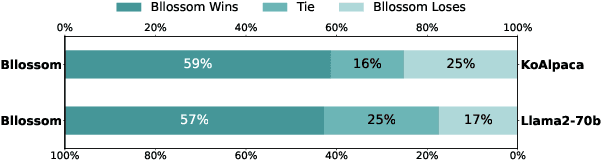
Large language models (LLMs) use pretraining to predict the subsequent word; however, their expansion requires significant computing resources. Numerous big tech companies and research institutes have developed multilingual LLMs (MLLMs) to meet current demands, overlooking less-resourced languages (LRLs). This study proposed three strategies to enhance the performance of LRLs based on the publicly available MLLMs. First, the MLLM vocabularies of LRLs were expanded to enhance expressiveness. Second, bilingual data were used for pretraining to align the high- and less-resourced languages. Third, a high-quality small-scale instruction dataset was constructed and instruction-tuning was performed to augment the LRL. The experiments employed the Llama2 model and Korean was used as the LRL, which was quantitatively evaluated against other developed LLMs across eight tasks. Furthermore, a qualitative assessment was performed based on human evaluation and GPT4. Experimental results showed that our proposed Bllossom model exhibited superior performance in qualitative analyses compared to previously proposed Korean monolingual models.