 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELO: Efficient Layer-Specific Optimization for Continual Pretraining of Multilingual LLMs
Jan 07, 2026We propose an efficient layer-specific optimization (ELO) method designed to enhance continual pretraining (CP) for specific languages in multilingual large language models (MLLMs). This approach addresses the common challenges of high computational cost and degradation of source language performance associated with traditional CP. The ELO method consists of two main stages: (1) ELO Pretraining, where a small subset of specific layers, identified in our experiments as the critically important first and last layers, are detached from the original MLLM and trained with the target language. This significantly reduces not only the number of trainable parameters but also the total parameters computed during the forward pass, minimizing GPU memory consumption and accelerating the training process. (2) Layer Alignment, where the newly trained layers are reintegrated into the original model, followed by a brief full fine-tuning step on a small dataset to align the parameters. Experimental results demonstrate that the ELO method achieves a training speedup of up to 6.46 times compared to existing methods, while improving target language performance by up to 6.2\% on qualitative benchmarks and effectively preserving source language (English) capabilities.
Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on Korean
Mar 21, 2024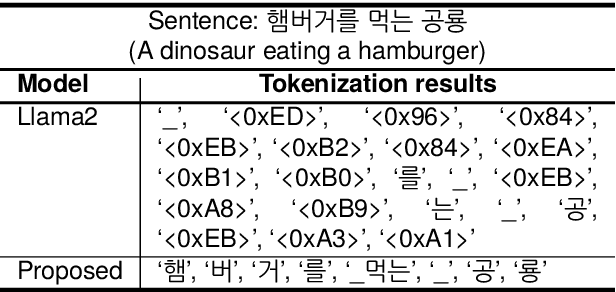
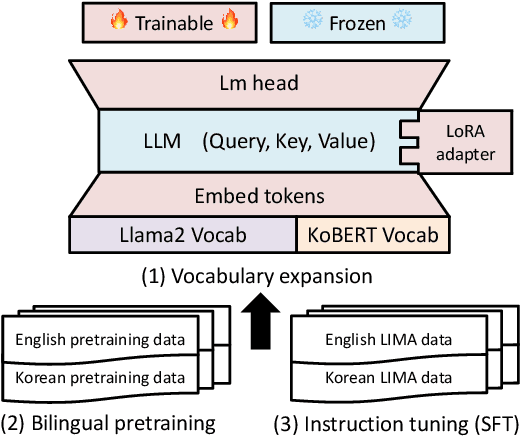

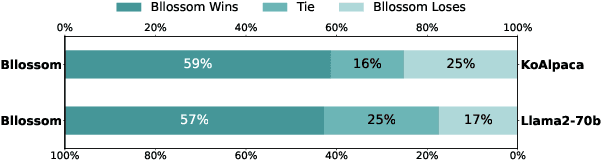
Large language models (LLMs) use pretraining to predict the subsequent word; however, their expansion requires significant computing resources. Numerous big tech companies and research institutes have developed multilingual LLMs (MLLMs) to meet current demands, overlooking less-resourced languages (LRLs). This study proposed three strategies to enhance the performance of LRLs based on the publicly available MLLMs. First, the MLLM vocabularies of LRLs were expanded to enhance expressiveness. Second, bilingual data were used for pretraining to align the high- and less-resourced languages. Third, a high-quality small-scale instruction dataset was constructed and instruction-tuning was performed to augment the LRL. The experiments employed the Llama2 model and Korean was used as the LRL, which was quantitatively evaluated against other developed LLMs across eight tasks. Furthermore, a qualitative assessment was performed based on human evaluation and GPT4. Experimental results showed that our proposed Bllossom model exhibited superior performance in qualitative analyses compared to previously proposed Korean monolingual models.