 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTREX: Tokenizer Regression for Optimal Data Mixture
Jan 20, 2026Building effective tokenizers for multilingual Large Language Models (LLMs) requires careful control over language-specific data mixtures. While a tokenizer's compression performance critically affects the efficiency of LLM training and inference, existing approaches rely on heuristics or costly large-scale searches to determine optimal language ratios. We introduce Tokenizer Regression for Optimal Data MiXture (TREX), a regression-based framework that efficiently predicts the optimal data mixture for tokenizer training. TREX trains small-scale proxy tokenizers on random mixtures, gathers their compression statistics, and learns to predict compression performance from data mixtures. This learned model enables scalable mixture search before large-scale tokenizer training, mitigating the accuracy-cost trade-off in multilingual tokenizer design. Tokenizers trained with TReX's predicted mixtures outperform mixtures based on LLaMA3 and uniform distributions by up to 12% in both inand out-of-distribution compression efficiency, demonstrating strong scalability, robustness, and practical effectiveness.
Solar Open Technical Report
Jan 11, 2026We introduce Solar Open, a 102B-parameter bilingual Mixture-of-Experts language model for underserved languages. Solar Open demonstrates a systematic methodology for building competitive LLMs by addressing three interconnected challenges. First, to train effectively despite data scarcity for underserved languages, we synthesize 4.5T tokens of high-quality, domain-specific, and RL-oriented data. Second, we coordinate this data through a progressive curriculum jointly optimizing composition, quality thresholds, and domain coverage across 20 trillion tokens. Third, to enable reasoning capabilities through scalable RL, we apply our proposed framework SnapPO for efficient optimization. Across benchmarks in English and Korean, Solar Open achieves competitive performance, demonstrating the effectiveness of this methodology for underserved language AI development.
ELO: Efficient Layer-Specific Optimization for Continual Pretraining of Multilingual LLMs
Jan 07, 2026We propose an efficient layer-specific optimization (ELO) method designed to enhance continual pretraining (CP) for specific languages in multilingual large language models (MLLMs). This approach addresses the common challenges of high computational cost and degradation of source language performance associated with traditional CP. The ELO method consists of two main stages: (1) ELO Pretraining, where a small subset of specific layers, identified in our experiments as the critically important first and last layers, are detached from the original MLLM and trained with the target language. This significantly reduces not only the number of trainable parameters but also the total parameters computed during the forward pass, minimizing GPU memory consumption and accelerating the training process. (2) Layer Alignment, where the newly trained layers are reintegrated into the original model, followed by a brief full fine-tuning step on a small dataset to align the parameters. Experimental results demonstrate that the ELO method achieves a training speedup of up to 6.46 times compared to existing methods, while improving target language performance by up to 6.2\% on qualitative benchmarks and effectively preserving source language (English) capabilities.
Enriching the Korean Learner Corpus with Multi-reference Annotations and Rubric-Based Scoring
May 01, 2025Despite growing global interest in Korean language education, there remains a significant lack of learner corpora tailored to Korean L2 writing. To address this gap, we enhance the KoLLA Korean learner corpus by adding multiple grammatical error correction (GEC) references, thereby enabling more nuanced and flexible evaluation of GEC systems, and reflects the variability of human language. Additionally, we enrich the corpus with rubric-based scores aligned with guidelines from the Korean National Language Institute, capturing grammatical accuracy, coherence, and lexical diversity. These enhancements make KoLLA a robust and standardized resource for research in Korean L2 education, supporting advancements in language learning, assessment, and automated error correction.
KFinEval-Pilot: A Comprehensive Benchmark Suite for Korean Financial Language Understanding
Apr 17, 2025We introduce KFinEval-Pilot, a benchmark suite specifically designed to evaluate large language models (LLMs) in the Korean financial domain. Addressing the limitations of existing English-centric benchmarks, KFinEval-Pilot comprises over 1,000 curated questions across three critical areas: financial knowledge, legal reasoning, and financial toxicity. The benchmark is constructed through a semi-automated pipeline that combines GPT-4-generated prompts with expert validation to ensure domain relevance and factual accuracy. We evaluate a range of representative LLMs and observe notable performance differences across models, with trade-offs between task accuracy and output safety across different model families. These results highlight persistent challenges in applying LLMs to high-stakes financial applications, particularly in reasoning and safety. Grounded in real-world financial use cases and aligned with the Korean regulatory and linguistic context, KFinEval-Pilot serves as an early diagnostic tool for developing safer and more reliable financial AI systems.
Enhancing Korean Dependency Parsing with Morphosyntactic Features
Mar 26, 2025This paper introduces UniDive for Korean, an integrated framework that bridges Universal Dependencies (UD) and Universal Morphology (UniMorph) to enhance the representation and processing of Korean {morphosyntax}. Korean's rich inflectional morphology and flexible word order pose challenges for existing frameworks, which often treat morphology and syntax separately, leading to inconsistencies in linguistic analysis. UniDive unifies syntactic and morphological annotations by preserving syntactic dependencies while incorporating UniMorph-derived features, improving consistency in annotation. We construct an integrated dataset and apply it to dependency parsing, demonstrating that enriched morphosyntactic features enhance parsing accuracy, particularly in distinguishing grammatical relations influenced by morphology. Our experiments, conducted with both encoder-only and decoder-only models, confirm that explicit morphological information contributes to more accurate syntactic analysis.
VLR-Bench: Multilingual Benchmark Dataset for Vision-Language Retrieval Augmented Generation
Dec 13, 2024



We propose the VLR-Bench, a visual question answering (VQA) benchmark for evaluating vision language models (VLMs) based on retrieval augmented generation (RAG). Unlike existing evaluation datasets for external knowledge-based VQA, the proposed VLR-Bench includes five input passages. This allows testing of the ability to determine which passage is useful for answering a given query, a capability lacking in previous research. In this context, we constructed a dataset of 32,000 automatically generated instruction-following examples, which we denote as VLR-IF. This dataset is specifically designed to enhance the RAG capabilities of VLMs by enabling them to learn how to generate appropriate answers based on input passages. We evaluated the validity of the proposed benchmark and training data and verified its performance using the state-of-the-art Llama3-based VLM, the Llava-Llama-3 model. The proposed VLR-Bench and VLR-IF datasets are publicly available online.
K-UD: Revising Korean Universal Dependencies Guidelines
Dec 01, 2024

Critique has surfaced concerning the existing linguistic annotation framework for Korean Universal Dependencies (UDs), particularly in relation to syntactic relationships. In this paper, our primary objective is to refine the definition of syntactic dependency of UDs within the context of analyzing the Korean language. Our aim is not only to achieve a consensus within UDs but also to garner agreement beyond the UD framework for analyzing Korean sentences using dependency structure, by establishing a linguistic consensus model.
Unlocking Korean Verbs: A User-Friendly Exploration into the Verb Lexicon
Oct 01, 2024



The Sejong dictionary dataset offers a valuable resource, providing extensive coverage of morphology, syntax, and semantic representation. This dataset can be utilized to explore linguistic information in greater depth. The labeled linguistic structures within this dataset form the basis for uncovering relationships between words and phrases and their associations with target verbs. This paper introduces a user-friendly web interface designed for the collection and consolidation of verb-related information, with a particular focus on subcategorization frames. Additionally, it outlines our efforts in mapping this information by aligning subcategorization frames with corresponding illustrative sentence examples. Furthermore, we provide a Python library that would simplify syntactic parsing and semantic role labeling. These tools are intended to assist individuals interested in harnessing the Sejong dictionary dataset to develop applications for Korean language processing.
Optimizing Language Augmentation for Multilingual Large Language Models: A Case Study on Korean
Mar 21, 2024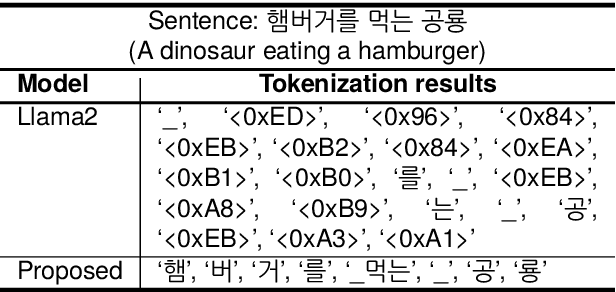
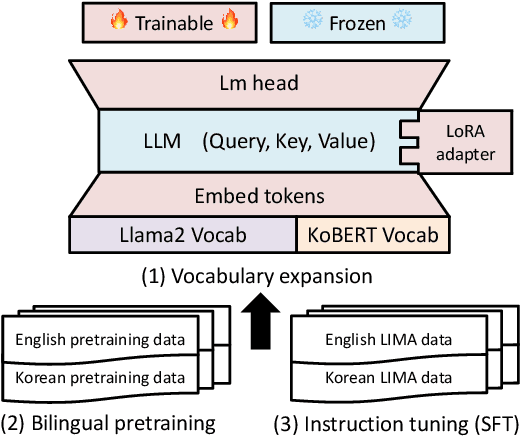

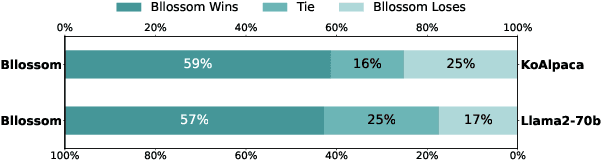
Large language models (LLMs) use pretraining to predict the subsequent word; however, their expansion requires significant computing resources. Numerous big tech companies and research institutes have developed multilingual LLMs (MLLMs) to meet current demands, overlooking less-resourced languages (LRLs). This study proposed three strategies to enhance the performance of LRLs based on the publicly available MLLMs. First, the MLLM vocabularies of LRLs were expanded to enhance expressiveness. Second, bilingual data were used for pretraining to align the high- and less-resourced languages. Third, a high-quality small-scale instruction dataset was constructed and instruction-tuning was performed to augment the LRL. The experiments employed the Llama2 model and Korean was used as the LRL, which was quantitatively evaluated against other developed LLMs across eight tasks. Furthermore, a qualitative assessment was performed based on human evaluation and GPT4. Experimental results showed that our proposed Bllossom model exhibited superior performance in qualitative analyses compared to previously proposed Korean monolingual models.