 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Automated Writing Evaluation with Corrective Feedback
Feb 27, 2024

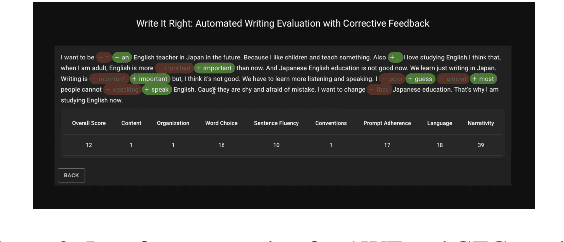

The utilization of technology in second language learning and teaching has become ubiquitous. For the assessment of writing specifically, automated writing evaluation (AWE) and grammatical error correction (GEC) have become immensely popular and effective methods for enhancing writing proficiency and delivering instant and individualized feedback to learners. By leveraging the power of natural language processing (NLP) and machine learning algorithms, AWE and GEC systems have been developed separately to provide language learners with automated corrective feedback and more accurate and unbiased scoring that would otherwise be subject to examiners. In this paper, we propose an integrated system for automated writing evaluation with corrective feedback as a means of bridging the gap between AWE and GEC results for second language learners. This system enables language learners to simulate the essay writing tests: a student writes and submits an essay, and the system returns the assessment of the writing along with suggested grammatical error corrections. Given that automated scoring and grammatical correction are more efficient and cost-effective than human grading, this integrated system would also alleviate the burden of manually correcting innumerable essays.
K-UniMorph: Korean Universal Morphology and its Feature Schema
May 17, 2023We present in this work a new Universal Morphology dataset for Korean. Previously, the Korean language has been underrepresented in the field of morphological paradigms amongst hundreds of diverse world languages. Hence, we propose this Universal Morphological paradigms for the Korean language that preserve its distinct characteristics. For our K-UniMorph dataset, we outline each grammatical criterion in detail for the verbal endings, clarify how to extract inflected forms, and demonstrate how we generate the morphological schemata. This dataset adopts morphological feature schema from Sylak-Glassman et al. (2015) and Sylak-Glassman (2016) for the Korean language as we extract inflected verb forms from the Sejong morphologically analyzed corpus that is one of the largest annotated corpora for Korean. During the data creation, our methodology also includes investigating the correctness of the conversion from the Sejong corpus. Furthermore, we carry out the inflection task using three different Korean word forms: letters, syllables and morphemes. Finally, we discuss and describe future perspectives on Korean morphological paradigms and the dataset.