 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Robustness of Reward Models for Mathematical Reasoning
Paper and Code
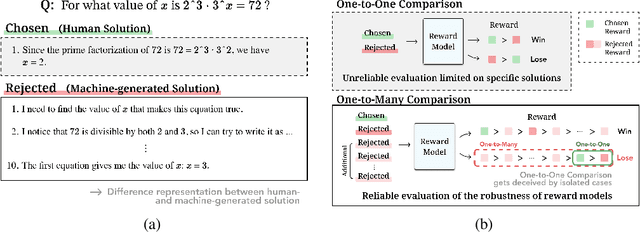
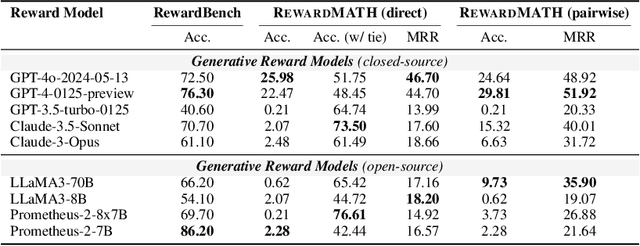
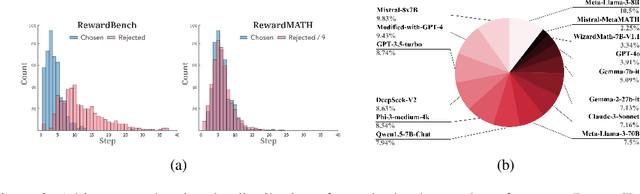
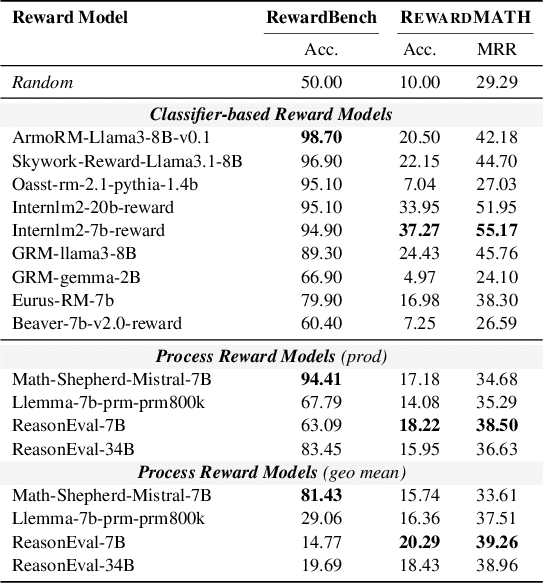
Reward models are key in reinforcement learning from human feedback (RLHF) systems, aligning the model behavior with human preferences. Particularly in the math domain, there have been plenty of studies using reward models to align policies for improving reasoning capabilities. Recently, as the importance of reward models has been emphasized, RewardBench is proposed to understand their behavior. However, we figure out that the math subset of RewardBench has different representations between chosen and rejected completions, and relies on a single comparison, which may lead to unreliable results as it only see an isolated case. Therefore, it fails to accurately present the robustness of reward models, leading to a misunderstanding of its performance and potentially resulting in reward hacking. In this work, we introduce a new design for reliable evaluation of reward models, and to validate this, we construct RewardMATH, a benchmark that effectively represents the robustness of reward models in mathematical reasoning tasks. We demonstrate that the scores on RewardMATH strongly correlate with the results of optimized policy and effectively estimate reward overoptimization, whereas the existing benchmark shows almost no correlation. The results underscore the potential of our design to enhance the reliability of evaluation, and represent the robustness of reward model. We make our code and data publicly available.