 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Me Finish My Sentence: Video Temporal Grounding with Holistic Text Understanding
Paper and Code
Oct 17, 2024


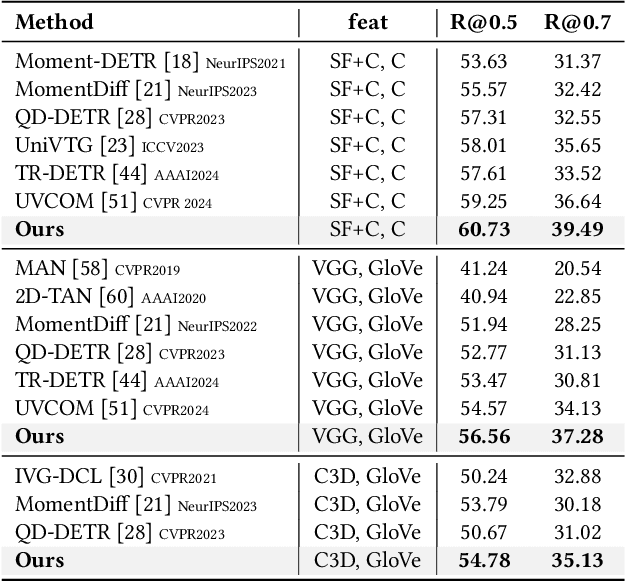
Video Temporal Grounding (VTG) aims to identify visual frames in a video clip that match text queries. Recent studies in VTG employ cross-attention to correlate visual frames and text queries as individual token sequences. However, these approaches overlook a crucial aspect of the problem: a holistic understanding of the query sentence. A model may capture correlations between individual word tokens and arbitrary visual frames while possibly missing out on the global meaning. To address this, we introduce two primary contributions: (1) a visual frame-level gate mechanism that incorporates holistic textual information, (2) cross-modal alignment loss to learn the fine-grained correlation between query and relevant frames. As a result, we regularize the effect of individual word tokens and suppress irrelevant visual frames. We demonstrate that our method outperforms state-of-the-art approaches in VTG benchmarks, indicating that holistic text understanding guides the model to focus on the semantically important parts within the video.