 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStay in your Lane: Role Specific Queries with Overlap Suppression Loss for Dense Video Captioning
Mar 12, 2026Dense Video Captioning (DVC) is a challenging multimodal task that involves temporally localizing multiple events within a video and describing them with natural language. While query-based frameworks enable the simultaneous, end-to-end processing of localization and captioning, their reliance on shared queries often leads to significant multi-task interference between the two tasks, as well as temporal redundancy in localization. In this paper, we propose utilizing role-specific queries that separate localization and captioning into independent components, allowing each to exclusively learn its role. We then employ contrastive alignment to enforce semantic consistency between the corresponding outputs, ensuring coherent behavior across the separated queries. Furthermore, we design a novel suppression mechanism in which mutual temporal overlaps across queries are penalized to tackle temporal redundancy, supervising the model to learn distinct, non-overlapping event regions for more precise localization. Additionally, we introduce a lightweight module that captures core event concepts to further enhance semantic richness in captions through concept-level representations. We demonstrate the effectiveness of our method through extensive experiments on major DVC benchmarks YouCook2 and ActivityNet Captions.
LAMB: LLM-based Audio Captioning with Modality Gap Bridging via Cauchy-Schwarz Divergence
Jan 08, 2026Automated Audio Captioning aims to describe the semantic content of input audio. Recent works have employed large language models (LLMs) as a text decoder to leverage their reasoning capabilities. However, prior approaches that project audio features into the LLM embedding space without considering cross-modal alignment fail to fully utilize these capabilities. To address this, we propose LAMB, an LLM-based audio captioning framework that bridges the modality gap between audio embeddings and the LLM text embedding space. LAMB incorporates a Cross-Modal Aligner that minimizes Cauchy-Schwarz divergence while maximizing mutual information, yielding tighter alignment between audio and text at both global and token levels. We further design a Two-Stream Adapter that extracts semantically enriched audio embeddings, thereby delivering richer information to the Cross-Modal Aligner. Finally, leveraging the aligned audio embeddings, a proposed Token Guide directly computes scores within the LLM text embedding space to steer the output logits of generated captions. Experimental results confirm that our framework strengthens the reasoning capabilities of the LLM decoder, achieving state-of-the-art performance on AudioCaps.
LAVCap: LLM-based Audio-Visual Captioning using Optimal Transport
Jan 16, 2025



Automated audio captioning is a task that generates textual descriptions for audio content, and recent studies have explored using visual information to enhance captioning quality. However, current methods often fail to effectively fuse audio and visual data, missing important semantic cues from each modality. To address this, we introduce LAVCap, a large language model (LLM)-based audio-visual captioning framework that effectively integrates visual information with audio to improve audio captioning performance. LAVCap employs an optimal transport-based alignment loss to bridge the modality gap between audio and visual features, enabling more effective semantic extraction. Additionally, we propose an optimal transport attention module that enhances audio-visual fusion using an optimal transport assignment map. Combined with the optimal training strategy, experimental results demonstrate that each component of our framework is effective. LAVCap outperforms existing state-of-the-art methods on the AudioCaps dataset, without relying on large datasets or post-processing. Code is available at https://github.com/NAVER-INTEL-Co-Lab/gaudi-lavcap.
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Mar 14, 2024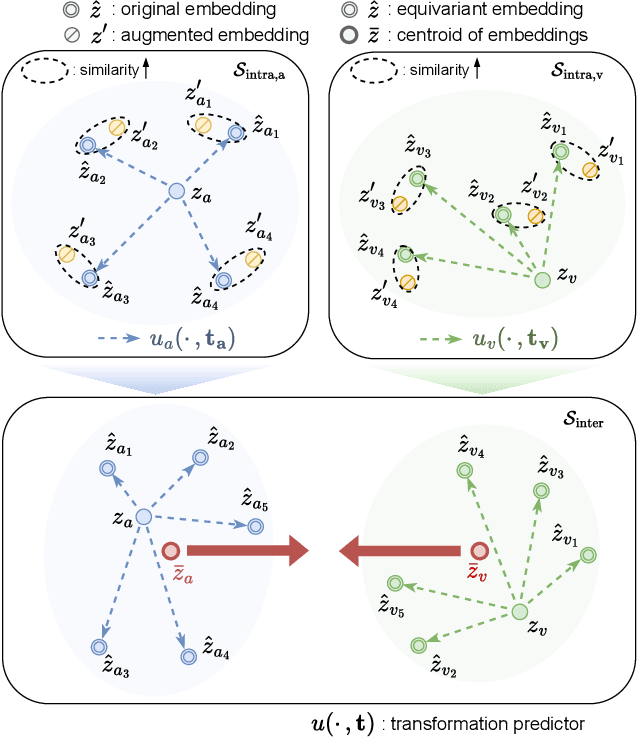

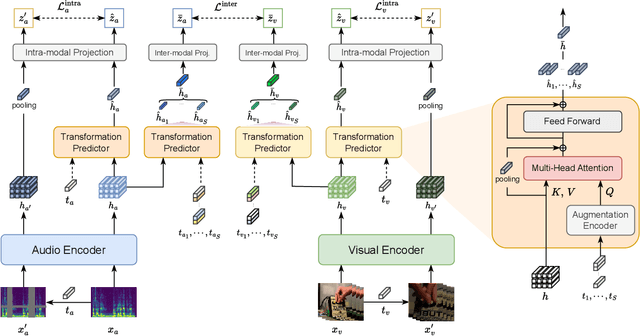

Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks.
That's What I Said: Fully-Controllable Talking Face Generation
Apr 06, 2023The goal of this paper is to synthesise talking faces with controllable facial motions. To achieve this goal, we propose two key ideas. The first is to establish a canonical space where every face has the same motion patterns but different identities. The second is to navigate a multimodal motion space that only represents motion-related features while eliminating identity information. To disentangle identity and motion, we introduce an orthogonality constraint between the two different latent spaces. From this, our method can generate natural-looking talking faces with fully controllable facial attributes and accurate lip synchronisation. Extensive experiments demonstrate that our method achieves state-of-the-art results in terms of both visual quality and lip-sync score. To the best of our knowledge, we are the first to develop a talking face generation framework that can accurately manifest full target facial motions including lip, head pose, and eye movements in the generated video without any additional supervision beyond RGB video with audio.