 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Codec-based Speech Synthesis with Multi-Token Prediction and Speculative Decoding
Oct 17, 2024



The goal of this paper is to accelerate codec-based speech synthesis systems with minimum sacrifice to speech quality. We propose an enhanced inference method that allows for flexible trade-offs between speed and quality during inference without requiring additional training. Our core idea is to predict multiple tokens per inference step of the AR module using multiple prediction heads, resulting in a linear reduction in synthesis time as the number of heads increases. Furthermore, we introduce a novel speculative decoding technique that utilises a Viterbi-based algorithm to select the optimal sequence of generated tokens at each decoding step. In our experiments, we demonstrate that the time required to predict each token is reduced by a factor of 4 to 5 compared to baseline models, with minimal quality trade-off or even improvement in terms of speech intelligibility. Audio samples are available at: multpletokensprediction.github.io/multipletokensprediction.github.io/.
Boosting Unknown-number Speaker Separation with Transformer Decoder-based Attractor
Jan 23, 2024We propose a novel speech separation model designed to separate mixtures with an unknown number of speakers. The proposed model stacks 1) a dual-path processing block that can model spectro-temporal patterns, 2) a transformer decoder-based attractor (TDA) calculation module that can deal with an unknown number of speakers, and 3) triple-path processing blocks that can model inter-speaker relations. Given a fixed, small set of learned speaker queries and the mixture embedding produced by the dual-path blocks, TDA infers the relations of these queries and generates an attractor vector for each speaker. The estimated attractors are then combined with the mixture embedding by feature-wise linear modulation conditioning, creating a speaker dimension. The mixture embedding, conditioned with speaker information produced by TDA, is fed to the final triple-path blocks, which augment the dual-path blocks with an additional pathway dedicated to inter-speaker processing. The proposed approach outperforms the previous best reported in the literature, achieving 24.0 and 23.7 dB SI-SDR improvement (SI-SDRi) on WSJ0-2 and 3mix respectively, with a single model trained to separate 2- and 3-speaker mixtures. The proposed model also exhibits strong performance and generalizability at counting sources and separating mixtures with up to 5 speakers.
Neural Speech Enhancement with Very Low Algorithmic Latency and Complexity via Integrated Full- and Sub-Band Modeling
Apr 18, 2023



We propose FSB-LSTM, a novel long short-term memory (LSTM) based architecture that integrates full- and sub-band (FSB) modeling, for single- and multi-channel speech enhancement in the short-time Fourier transform (STFT) domain. The model maintains an information highway to flow an over-complete input representation through multiple FSB-LSTM modules. Each FSB-LSTM module consists of a full-band block to model spectro-temporal patterns at all frequencies and a sub-band block to model patterns within each sub-band, where each of the two blocks takes a down-sampled representation as input and returns an up-sampled discriminative representation to be added to the block input via a residual connection. The model is designed to have a low algorithmic complexity, a small run-time buffer and a very low algorithmic latency, at the same time producing a strong enhancement performance on a noisy-reverberant speech enhancement task even if the hop size is as low as $2$ ms.
TF-GridNet: Integrating Full- and Sub-Band Modeling for Speech Separation
Nov 22, 2022We propose TF-GridNet for speech separation. The model is a novel multi-path deep neural network (DNN) integrating full- and sub-band modeling in the time-frequency (T-F) domain. It stacks several multi-path blocks, each consisting of an intra-frame full-band module, a sub-band temporal module, and a cross-frame self-attention module. It is trained to perform complex spectral mapping, where the real and imaginary (RI) components of input signals are stacked as features to predict target RI components. We first evaluate it on monaural anechoic speaker separation. Without using data augmentation and dynamic mixing, it obtains a state-of-the-art 23.5 dB improvement in scale-invariant signal-to-distortion ratio (SI-SDR) on WSJ0-2mix, a standard dataset for two-speaker separation. To show its robustness to noise and reverberation, we evaluate it on monaural reverberant speaker separation using the SMS-WSJ dataset and on noisy-reverberant speaker separation using WHAMR!, and obtain state-of-the-art performance on both datasets. We then extend TF-GridNet to multi-microphone conditions through multi-microphone complex spectral mapping, and integrate it into a two-DNN system with a beamformer in between (named as MISO-BF-MISO in earlier studies), where the beamformer proposed in this paper is a novel multi-frame Wiener filter computed based on the outputs of the first DNN. State-of-the-art performance is obtained on the multi-channel tasks of SMS-WSJ and WHAMR!. Besides speaker separation, we apply the proposed algorithms to speech dereverberation and noisy-reverberant speech enhancement. State-of-the-art performance is obtained on a dereverberation dataset and on the dataset of the recent L3DAS22 multi-channel speech enhancement challenge.
TF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation
Sep 08, 2022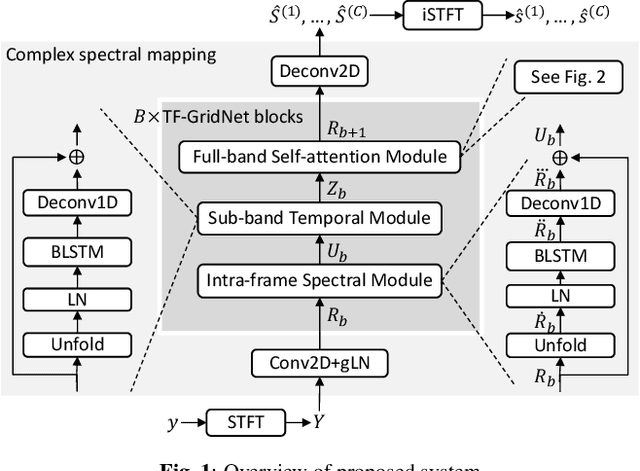
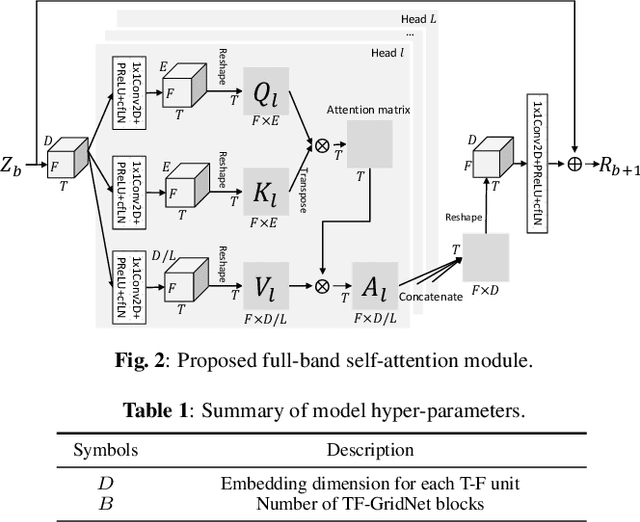


We propose TF-GridNet, a novel multi-path deep neural network (DNN) operating in the time-frequency (T-F) domain, for monaural talker-independent speaker separation in anechoic conditions. The model stacks several multi-path blocks, each consisting of an intra-frame spectral module, a sub-band temporal module, and a full-band self-attention module, to leverage local and global spectro-temporal information for separation. The model is trained to perform complex spectral mapping, where the real and imaginary (RI) components of the input mixture are stacked as input features to predict the target RI components. Besides using the scale-invariant signal-to-distortion ratio (SI-SDR) loss for model training, we include a novel loss term to encourage the separated sources to add up to the input mixture. Without using dynamic mixing, we obtain 23.4 dB SI-SDR improvement (SI-SDRi) on the WSJ0-2mix dataset, outperforming the previous best by a large margin.