 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-GridNet: Making Time-Frequency Domain Models Great Again for Monaural Speaker Separation
Paper and Code
Sep 08, 2022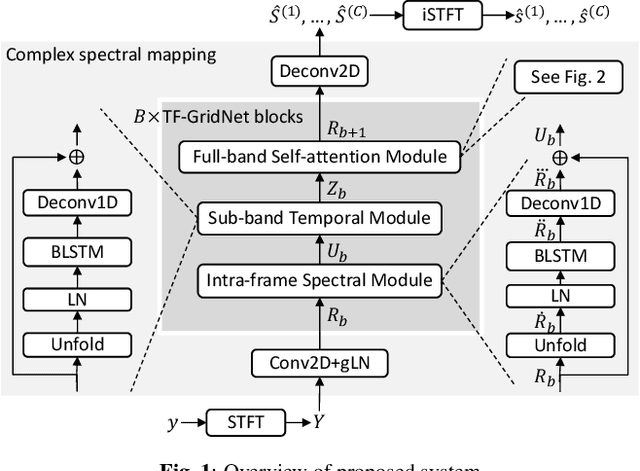
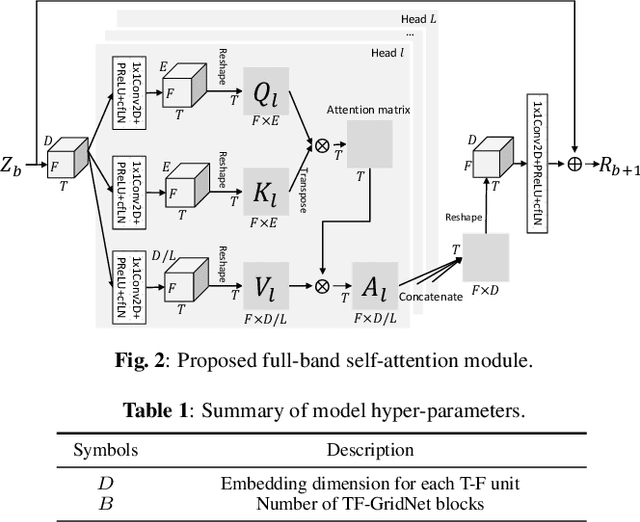


We propose TF-GridNet, a novel multi-path deep neural network (DNN) operating in the time-frequency (T-F) domain, for monaural talker-independent speaker separation in anechoic conditions. The model stacks several multi-path blocks, each consisting of an intra-frame spectral module, a sub-band temporal module, and a full-band self-attention module, to leverage local and global spectro-temporal information for separation. The model is trained to perform complex spectral mapping, where the real and imaginary (RI) components of the input mixture are stacked as input features to predict the target RI components. Besides using the scale-invariant signal-to-distortion ratio (SI-SDR) loss for model training, we include a novel loss term to encourage the separated sources to add up to the input mixture. Without using dynamic mixing, we obtain 23.4 dB SI-SDR improvement (SI-SDRi) on the WSJ0-2mix dataset, outperforming the previous best by a large margin.