 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHILCodec: High Fidelity and Lightweight Neural Audio Codec
May 08, 2024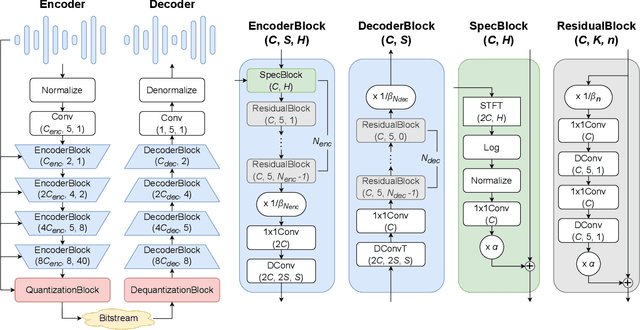
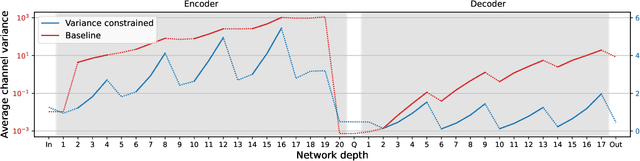
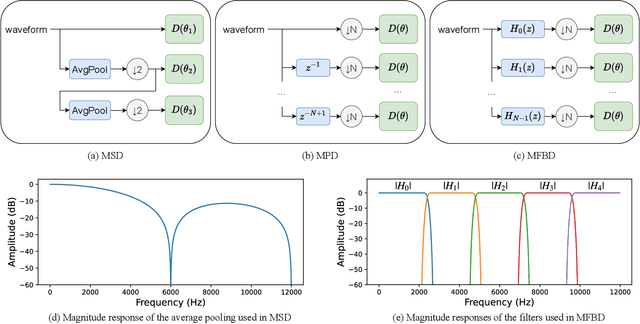
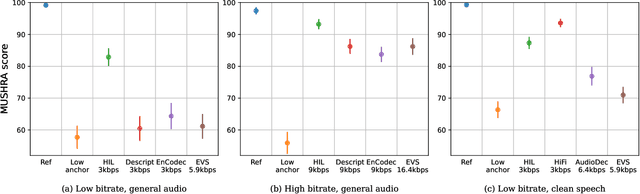
The recent advancement of end-to-end neural audio codecs enables compressing audio at very low bitrates while reconstructing the output audio with high fidelity. Nonetheless, such improvements often come at the cost of increased model complexity. In this paper, we identify and address the problems of existing neural audio codecs. We show that the performance of Wave-U-Net does not increase consistently as the network depth increases. We analyze the root cause of such a phenomenon and suggest a variance-constrained design. Also, we reveal various distortions in previous waveform domain discriminators and propose a novel distortion-free discriminator. The resulting model, \textit{HILCodec}, is a real-time streaming audio codec that demonstrates state-of-the-art quality across various bitrates and audio types.