 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransduce and Speak: Neural Transducer for Text-to-Speech with Semantic Token Prediction
Nov 08, 2023We introduce a text-to-speech(TTS) framework based on a neural transducer. We use discretized semantic tokens acquired from wav2vec2.0 embeddings, which makes it easy to adopt a neural transducer for the TTS framework enjoying its monotonic alignment constraints. The proposed model first generates aligned semantic tokens using the neural transducer, then synthesizes a speech sample from the semantic tokens using a non-autoregressive(NAR) speech generator. This decoupled framework alleviates the training complexity of TTS and allows each stage to focus on 1) linguistic and alignment modeling and 2) fine-grained acoustic modeling, respectively. Experimental results on the zero-shot adaptive TTS show that the proposed model exceeds the baselines in speech quality and speaker similarity via objective and subjective measures. We also investigate the inference speed and prosody controllability of our proposed model, showing the potential of the neural transducer for TTS frameworks.
Fully Unsupervised Training of Few-shot Keyword Spotting
Oct 07, 2022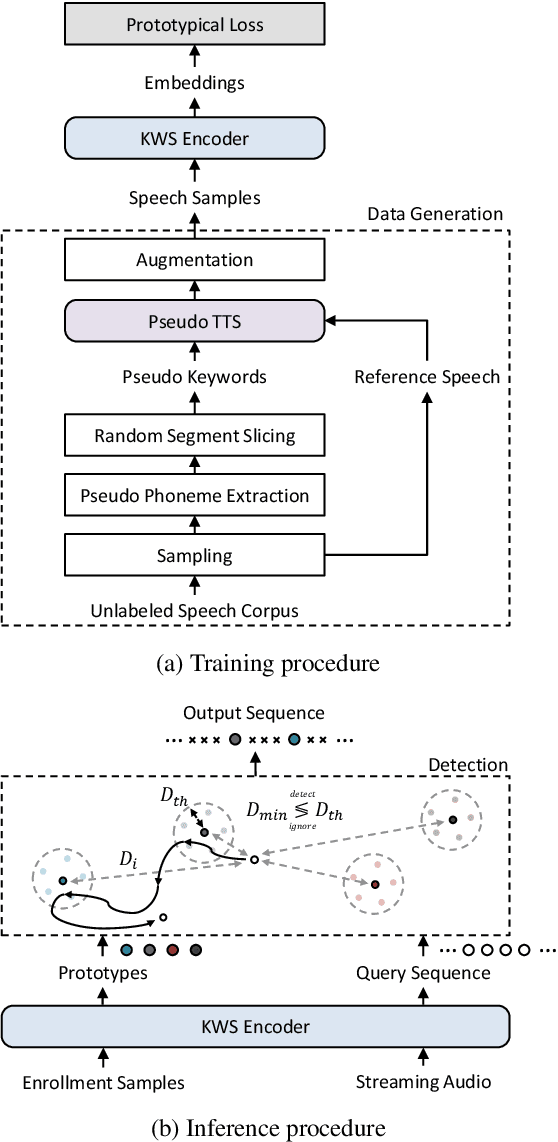
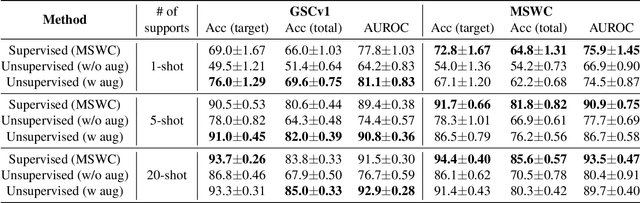

For training a few-shot keyword spotting (FS-KWS) model, a large labeled dataset containing massive target keywords has known to be essential to generalize to arbitrary target keywords with only a few enrollment samples. To alleviate the expensive data collection with labeling, in this paper, we propose a novel FS-KWS system trained only on synthetic data. The proposed system is based on metric learning enabling target keywords to be detected using distance metrics. Exploiting the speech synthesis model that generates speech with pseudo phonemes instead of texts, we easily obtain a large collection of multi-view samples with the same semantics. These samples are sufficient for training, considering metric learning does not intrinsically necessitate labeled data. All of the components in our framework do not require any supervision, making our method unsupervised. Experimental results on real datasets show our proposed method is competitive even without any labeled and real datasets.
Disentangled Speaker Representation Learning via Mutual Information Minimization
Aug 17, 2022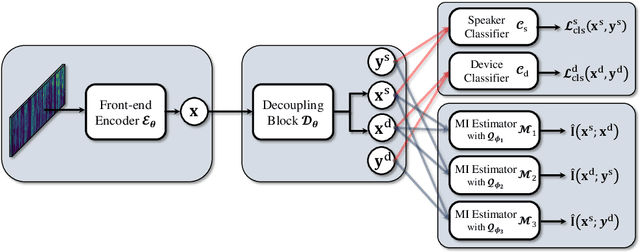
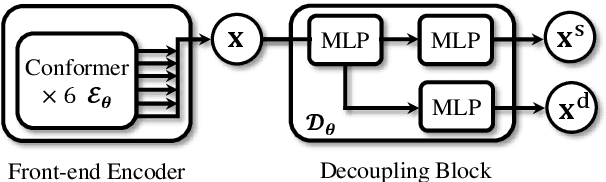
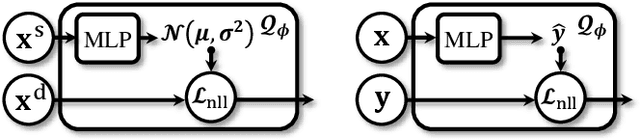
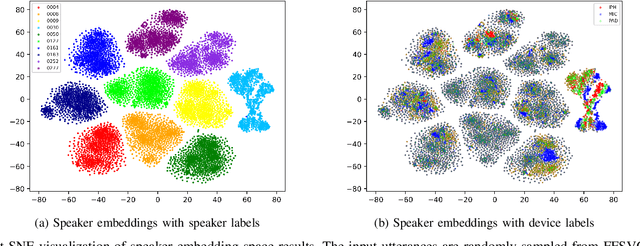
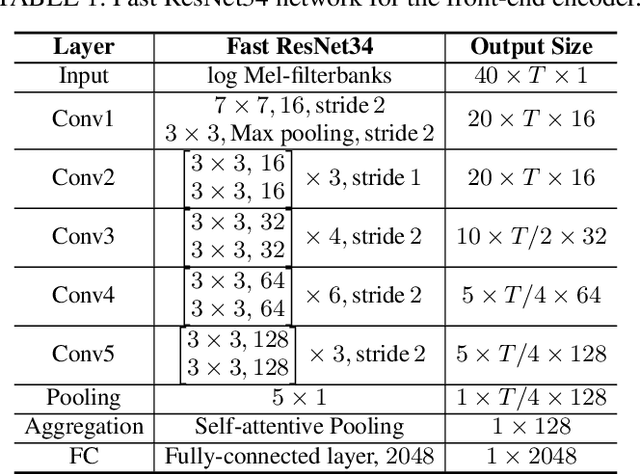
Domain mismatch problem caused by speaker-unrelated feature has been a major topic in speaker recognition. In this paper, we propose an explicit disentanglement framework to unravel speaker-relevant features from speaker-unrelated features via mutual information (MI) minimization. To achieve our goal of minimizing MI between speaker-related and speaker-unrelated features, we adopt a contrastive log-ratio upper bound (CLUB), which exploits the upper bound of MI. Our framework is constructed in a 3-stage structure. First, in the front-end encoder, input speech is encoded into shared initial embedding. Next, in the decoupling block, shared initial embedding is split into separate speaker-related and speaker-unrelated embeddings. Finally, disentanglement is conducted by MI minimization in the last stage. Experiments on Far-Field Speaker Verification Challenge 2022 (FFSVC2022) demonstrate that our proposed framework is effective for disentanglement. Also, to utilize domain-unknown datasets containing numerous speakers, we pre-trained the front-end encoder with VoxCeleb datasets. We then fine-tuned the speaker embedding model in the disentanglement framework with FFSVC 2022 dataset. The experimental results show that fine-tuning with a disentanglement framework on a existing pre-trained model is valid and can further improve performance.
Bootstrap Equilibrium and Probabilistic Speaker Representation Learning for Self-supervised Speaker Verification
Dec 24, 2021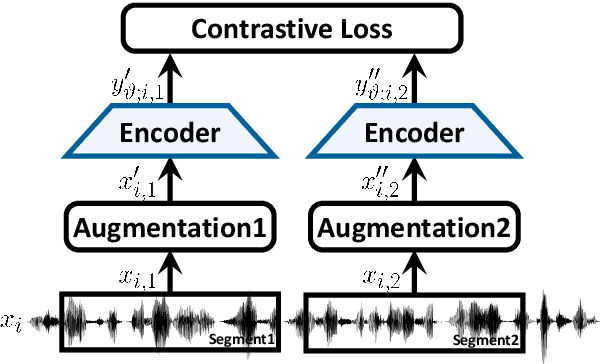
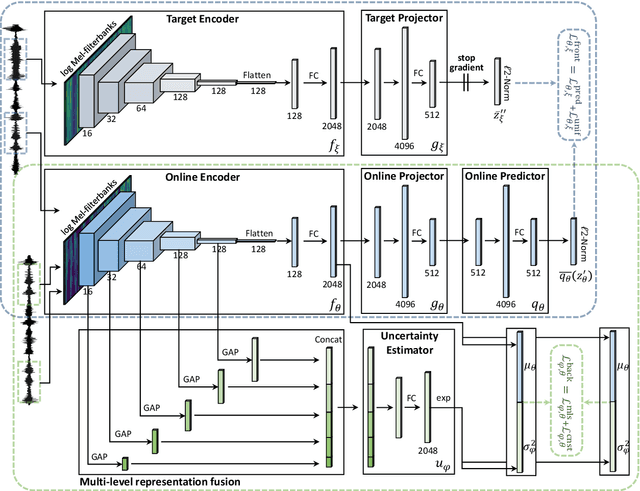
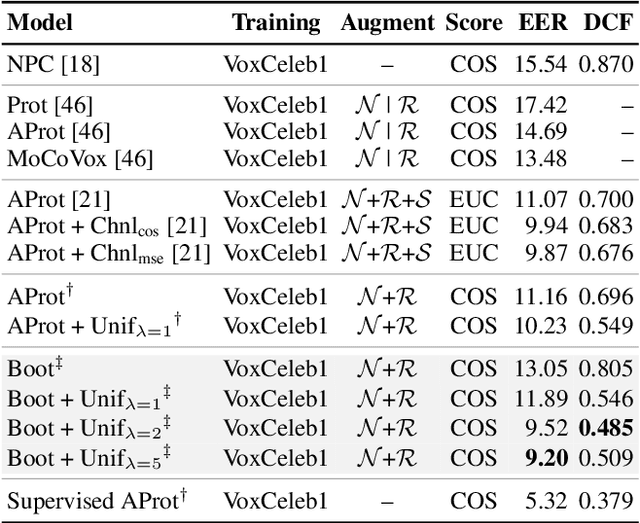
In this paper, we propose self-supervised speaker representation learning strategies, which comprise of a bootstrap equilibrium speaker representation learning in the front-end and an uncertainty-aware probabilistic speaker embedding training in the back-end. In the front-end stage, we learn the speaker representations via the bootstrap training scheme with the uniformity regularization term. In the back-end stage, the probabilistic speaker embeddings are estimated by maximizing the mutual likelihood score between the speech samples belonging to the same speaker, which provide not only speaker representations but also data uncertainty. Experimental results show that the proposed bootstrap equilibrium training strategy can effectively help learn the speaker representations and outperforms the conventional methods based on contrastive learning. Also, we demonstrate that the integrated two-stage framework further improves the speaker verification performance on the VoxCeleb1 test set in terms of EER and MinDCF.