 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Speaker Representation Learning via Mutual Information Minimization
Paper and Code
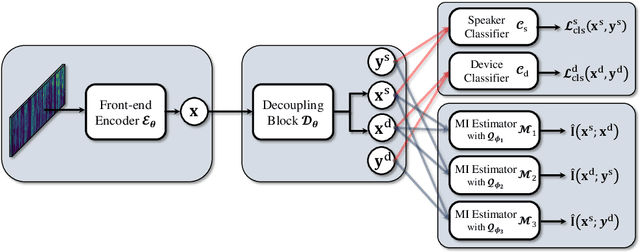
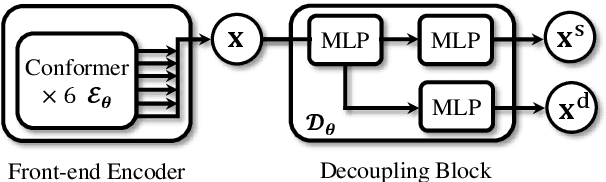
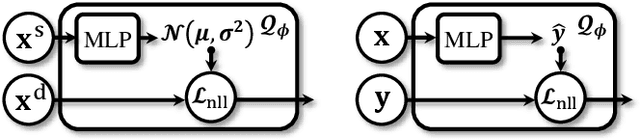
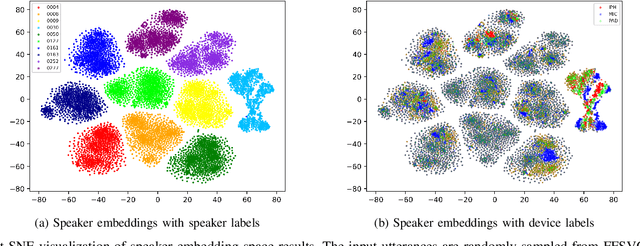
Domain mismatch problem caused by speaker-unrelated feature has been a major topic in speaker recognition. In this paper, we propose an explicit disentanglement framework to unravel speaker-relevant features from speaker-unrelated features via mutual information (MI) minimization. To achieve our goal of minimizing MI between speaker-related and speaker-unrelated features, we adopt a contrastive log-ratio upper bound (CLUB), which exploits the upper bound of MI. Our framework is constructed in a 3-stage structure. First, in the front-end encoder, input speech is encoded into shared initial embedding. Next, in the decoupling block, shared initial embedding is split into separate speaker-related and speaker-unrelated embeddings. Finally, disentanglement is conducted by MI minimization in the last stage. Experiments on Far-Field Speaker Verification Challenge 2022 (FFSVC2022) demonstrate that our proposed framework is effective for disentanglement. Also, to utilize domain-unknown datasets containing numerous speakers, we pre-trained the front-end encoder with VoxCeleb datasets. We then fine-tuned the speaker embedding model in the disentanglement framework with FFSVC 2022 dataset. The experimental results show that fine-tuning with a disentanglement framework on a existing pre-trained model is valid and can further improve performance.