 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Unsupervised Training of Few-shot Keyword Spotting
Paper and Code
Oct 07, 2022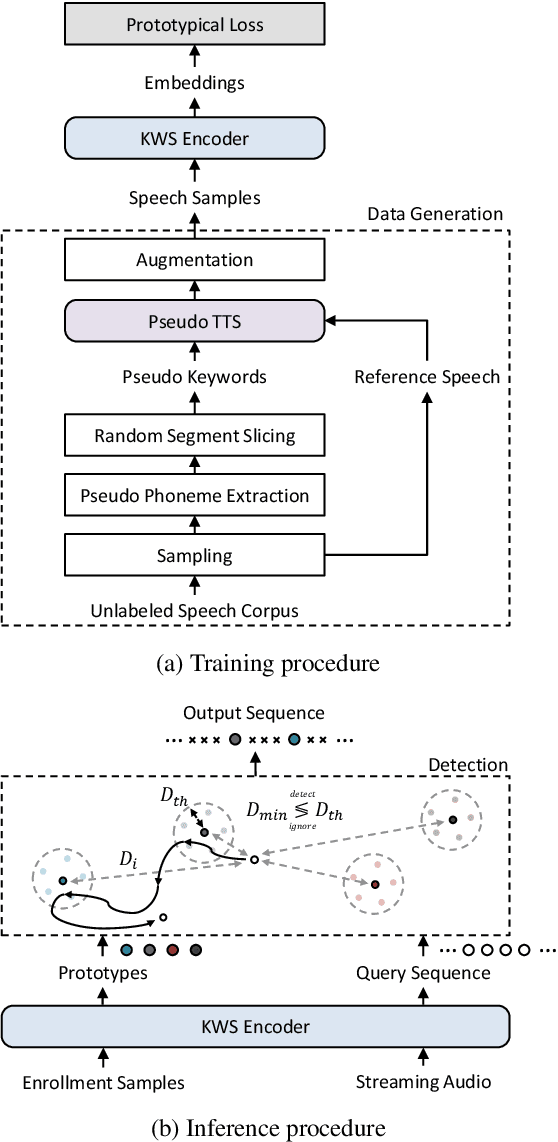
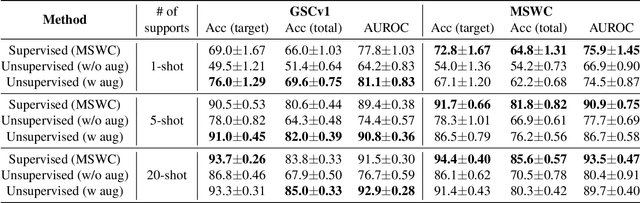

For training a few-shot keyword spotting (FS-KWS) model, a large labeled dataset containing massive target keywords has known to be essential to generalize to arbitrary target keywords with only a few enrollment samples. To alleviate the expensive data collection with labeling, in this paper, we propose a novel FS-KWS system trained only on synthetic data. The proposed system is based on metric learning enabling target keywords to be detected using distance metrics. Exploiting the speech synthesis model that generates speech with pseudo phonemes instead of texts, we easily obtain a large collection of multi-view samples with the same semantics. These samples are sufficient for training, considering metric learning does not intrinsically necessitate labeled data. All of the components in our framework do not require any supervision, making our method unsupervised. Experimental results on real datasets show our proposed method is competitive even without any labeled and real datasets.