 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOcclusion-Aware Multimodal Beam Prediction and Pose Estimation for mmWave V2I
Mar 26, 2026We propose an occlusion-aware multimodal learning framework that is inspired by simultaneous localization and mapping (SLAM) concepts for trajectory interpretation and pose prediction. Targeting mmWave vehicle-to-infrastructure (V2I) beam management under dynamic blockage, our Transformer-based fusion network ingests synchronized RGB images, LiDAR point clouds, radar range-angle maps, GNSS, and short-term mmWave power history. It jointly predicts the receive beam index, blockage probability, and 2D position using labels automatically derived from 64-beam sweep power vectors, while an offline LiDAR map enables SLAM-style trajectory visualization. On the 60 GHz DeepSense 6G Scenario 31 dataset, the model achieves 50.92\% Top-1 and 86.50\% Top-3 beam accuracy with 0.018 bits/s/Hz spectral-efficiency loss, 63.35\% blocked-class F1, and 1.33m position RMSE. Multimodal fusion outperforms radio-only and strong camera-only baselines, showing the value of coupling perception and communication for future 6G V2I systems.
Sensing-Assisted Adaptive Beam Probing with Calibrated Multimodal Priors and Uncertainty-Aware Scheduling
Mar 25, 2026Highly directional mmWave/THz links require rapid beam alignment, yet exhaustive codebook sweeps incur prohibitive training overhead. This letter proposes a sensing-assisted adaptive probing policy that maps multimodal sensing (radar/LiDAR/camera) to a calibrated prior over beams, predicts per-beam reward with a deep Q-ensemble whose disagreement serves as a practical epistemic-uncertainty proxy, and schedules a small probe set using a Prior-Q upper-confidence score. The probing budget is adapted from prior entropy, explicitly coupling sensing confidence to communication overhead, while a margin-based safety rule prevents low signal-to-noise ratio (SNR) locks. Experiments on DeepSense-6G (train: scenarios 42 and 44; test:43) with a 21-beam discrete Fourier transform (DFT) codebook achieve Top-1/Top-3 of 0.81/0.99 with expected beam probe of 2 per sweep and zero observed outages at θ = 0 dB with margin Δ = 3 dB. The results show that multimodal priors with ensemble uncertainty match link quality and improve reliability compared to ablations while cutting overhead with better predictive model.
Environment-aware Near-field UE Tracking under Partial Blockage and Reflection
Mar 13, 2026This paper proposes an environment-aware near-field (NF) user equipment (UE) tracking method for extremely large aperture arrays. By integrating known surface geometries and tracking the line-of-sight (LOS) and non-line-of-sight (NLOS) indicators per antenna element, the method captures partial blockages and reflections specific to the NF spherical-wavefront regime, which are unavailable under the conventional far-field (FF) assumption. The UE positions are tracked by maximizing the cosine similarity between the predicted and received channels, enabling tracking even under complete LOS obstruction. Simulation results confirm that increasing environment-awareness improves accuracy, and that NF consistently outperforms FF baselines, achieving a $0.22\,\mathrm{m}$ root-mean-square error with full environment-awareness.
I Dropped a Neural Net
Feb 23, 2026A recent Dwarkesh Patel podcast with John Collison and Elon Musk featured an interesting puzzle from Jane Street: they trained a neural net, shuffled all 96 layers, and asked to put them back in order. Given unlabelled layers of a Residual Network and its training dataset, we recover the exact ordering of the layers. The problem decomposes into pairing each block's input and output projections ($48!$ possibilities) and ordering the reassembled blocks ($48!$ possibilities), for a combined search space of $(48!)^2 \approx 10^{122}$, which is more than the atoms in the observable universe. We show that stability conditions during training like dynamic isometry leave the product $W_{\text{out}} W_{\text{in}}$ for correctly paired layers with a negative diagonal structure, allowing us to use diagonal dominance ratio as a signal for pairing. For ordering, we seed-initialize with a rough proxy such as delta-norm or $\|W_{\text{out}}\|_F$ then hill-climb to zero mean squared error.
System-Level Comparison of Multimodal and In-Band mmWave Sensing for Beam Prediction in 6G ISAC
Jan 03, 2026Integrated sensing and communication (ISAC) can reduce beam-training overhead in mmWave vehicle-to-infrastructure (V2I) links by enabling in-band sensing-based beam prediction, while exteroceptive sensors can further enhance the prediction accuracy. This work develop a system-level framework that evaluates camera, LiDAR, radar, GPS, and in-band mmWave power, both individually and in multimodal fusion using the DeepSense-6G Scenario-33 dataset. A latency-aware neural network composed of lightweight convolutional (CNN) and multilayer-perceptron (MLP) encoders predict a 64-beam index. We assess performance using Top-k accuracy alongside spectral-efficiency (SE) gap, signal-to-noise-ratio (SNR) gap, rate loss, and end-to-end latency. Results show that the mmWave power vector is a strong standalone predictor, and fusing exteroceptive sensors with it preserves high performance: mmWave alone and mmWave+LiDAR/GPS/Radar achieve 98% Top-5 accuracy, while mmWave+camera achieves 94% Top-5 accuracy. The proposed framework establishes calibrated baselines for 6G ISAC-assisted beam prediction in V2I systems.
Spatio-Temporal Graphs Beyond Grids: Benchmark for Maritime Anomaly Detection
Dec 23, 2025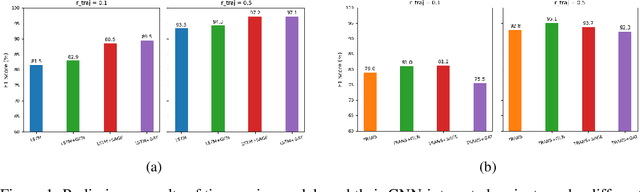

Spatio-temporal graph neural networks (ST-GNNs) have achieved notable success in structured domains such as road traffic and public transportation, where spatial entities can be naturally represented as fixed nodes. In contrast, many real-world systems including maritime traffic lack such fixed anchors, making the construction of spatio-temporal graphs a fundamental challenge. Anomaly detection in these non-grid environments is particularly difficult due to the absence of canonical reference points, the sparsity and irregularity of trajectories, and the fact that anomalies may manifest at multiple granularities. In this work, we introduce a novel benchmark dataset for anomaly detection in the maritime domain, extending the Open Maritime Traffic Analysis Dataset (OMTAD) into a benchmark tailored for graph-based anomaly detection. Our dataset enables systematic evaluation across three different granularities: node-level, edge-level, and graph-level anomalies. We plan to employ two specialized LLM-based agents: \emph{Trajectory Synthesizer} and \emph{Anomaly Injector} to construct richer interaction contexts and generate semantically meaningful anomalies. We expect this benchmark to promote reproducibility and to foster methodological advances in anomaly detection for non-grid spatio-temporal systems.
Mobility-Aware Localization in mmWave Channel: Adaptive Hybrid Filtering Approach
Oct 08, 2025Precise user localization and tracking enhances energy-efficient and ultra-reliable low latency applications in the next generation wireless networks. In addition to computational complexity and data association challenges with Kalman-filter localization techniques, estimation errors tend to grow as the user's trajectory speed increases. By exploiting mmWave signals for joint sensing and communication, our approach dispenses with additional sensors adopted in most techniques while retaining high resolution spatial cues. We present a hybrid mobility-aware adaptive framework that selects the Extended Kalman filter at pedestrian speed and the Unscented Kalman filter at vehicular speed. The scheme mitigates data-association problem and estimation errors through adaptive noise scaling, chi-square gating, Rauch-Tung-Striebel smoothing. Evaluations using Absolute Trajectory Error, Relative Pose Error, Normalized Estimated Error Squared and Root Mean Square Error metrics demonstrate roughly 30-60% improvement in their respective regimes indicating a clear advantage over existing approaches tailored to either indoor or static settings.
DropGaussian: Structural Regularization for Sparse-view Gaussian Splatting
Apr 01, 2025



Recently, 3D Gaussian splatting (3DGS) has gained considerable attentions in the field of novel view synthesis due to its fast performance while yielding the excellent image quality. However, 3DGS in sparse-view settings (e.g., three-view inputs) often faces with the problem of overfitting to training views, which significantly drops the visual quality of novel view images. Many existing approaches have tackled this issue by using strong priors, such as 2D generative contextual information and external depth signals. In contrast, this paper introduces a prior-free method, so-called DropGaussian, with simple changes in 3D Gaussian splatting. Specifically, we randomly remove Gaussians during the training process in a similar way of dropout, which allows non-excluded Gaussians to have larger gradients while improving their visibility. This makes the remaining Gaussians to contribute more to the optimization process for rendering with sparse input views. Such simple operation effectively alleviates the overfitting problem and enhances the quality of novel view synthesis. By simply applying DropGaussian to the original 3DGS framework, we can achieve the competitive performance with existing prior-based 3DGS methods in sparse-view settings of benchmark datasets without any additional complexity. The code and model are publicly available at: https://github.com/DCVL-3D/DropGaussian release.
SPECTra: Scalable Multi-Agent Reinforcement Learning with Permutation-Free Networks
Mar 14, 2025



In cooperative multi-agent reinforcement learning (MARL), the permutation problem where the state space grows exponentially with the number of agents reduces sample efficiency. Additionally, many existing architectures struggle with scalability, relying on a fixed structure tied to a specific number of agents, limiting their applicability to environments with a variable number of entities. While approaches such as graph neural networks (GNNs) and self-attention mechanisms have progressed in addressing these challenges, they have significant limitations as dense GNNs and self-attention mechanisms incur high computational costs. To overcome these limitations, we propose a novel agent network and a non-linear mixing network that ensure permutation-equivariance and scalability, allowing them to generalize to environments with various numbers of agents. Our agent network significantly reduces computational complexity, and our scalable hypernetwork enables efficient weight generation for non-linear mixing. Additionally, we introduce curriculum learning to improve training efficiency. Experiments on SMACv2 and Google Research Football (GRF) demonstrate that our approach achieves superior learning performance compared to existing methods. By addressing both permutation-invariance and scalability in MARL, our work provides a more efficient and adaptable framework for cooperative MARL. Our code is available at https://github.com/funny-rl/SPECTra.
Adaptive Sparsified Graph Learning Framework for Vessel Behavior Anomalies
Feb 20, 2025Graph neural networks have emerged as a powerful tool for learning spatiotemporal interactions. However, conventional approaches often rely on predefined graphs, which may obscure the precise relationships being modeled. Additionally, existing methods typically define nodes based on fixed spatial locations, a strategy that is ill-suited for dynamic environments like maritime environments. Our method introduces an innovative graph representation where timestamps are modeled as distinct nodes, allowing temporal dependencies to be explicitly captured through graph edges. This setup is extended to construct a multi-ship graph that effectively captures spatial interactions while preserving graph sparsity. The graph is processed using Graph Convolutional Network layers to capture spatiotemporal patterns, with a forecasting layer for feature prediction and a Variational Graph Autoencoder for reconstruction, enabling robust anomaly detection.