 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPaCT GNN: Imposing invariance with Message Passing in Chronological split Temporal Graphs
Nov 17, 2024This paper addresses domain adaptation challenges in graph data resulting from chronological splits. In a transductive graph learning setting, where each node is associated with a timestamp, we focus on the task of Semi-Supervised Node Classification (SSNC), aiming to classify recent nodes using labels of past nodes. Temporal dependencies in node connections create domain shifts, causing significant performance degradation when applying models trained on historical data into recent data. Given the practical relevance of this scenario, addressing domain adaptation in chronological split data is crucial, yet underexplored. We propose Imposing invariance with Message Passing in Chronological split Temporal Graphs (IMPaCT), a method that imposes invariant properties based on realistic assumptions derived from temporal graph structures. Unlike traditional domain adaptation approaches which rely on unverifiable assumptions, IMPaCT explicitly accounts for the characteristics of chronological splits. The IMPaCT is further supported by rigorous mathematical analysis, including a derivation of an upper bound of the generalization error. Experimentally, IMPaCT achieves a 3.8% performance improvement over current SOTA method on the ogbn-mag graph dataset. Additionally, we introduce the Temporal Stochastic Block Model (TSBM), which replicates temporal graphs under varying conditions, demonstrating the applicability of our methods to general spatial GNNs.
A Joint Probabilistic Classification Model of Relevant and Irrelevant Sentences in Mathematical Word Problems
Nov 21, 2014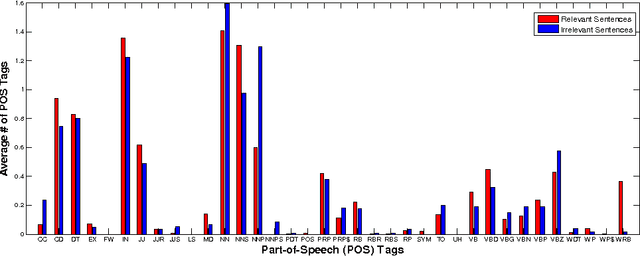


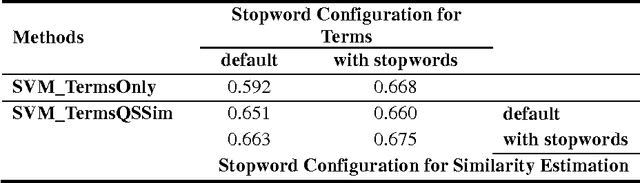
Estimating the difficulty level of math word problems is an important task for many educational applications. Identification of relevant and irrelevant sentences in math word problems is an important step for calculating the difficulty levels of such problems. This paper addresses a novel application of text categorization to identify two types of sentences in mathematical word problems, namely relevant and irrelevant sentences. A novel joint probabilistic classification model is proposed to estimate the joint probability of classification decisions for all sentences of a math word problem by utilizing the correlation among all sentences along with the correlation between the question sentence and other sentences, and sentence text. The proposed model is compared with i) a SVM classifier which makes independent classification decisions for individual sentences by only using the sentence text and ii) a novel SVM classifier that considers the correlation between the question sentence and other sentences along with the sentence text. An extensive set of experiments demonstrates the effectiveness of the joint probabilistic classification model for identifying relevant and irrelevant sentences as well as the novel SVM classifier that utilizes the correlation between the question sentence and other sentences. Furthermore, empirical results and analysis show that i) it is highly beneficial not to remove stopwords and ii) utilizing part of speech tagging does not make a significant improvement although it has been shown to be effective for the related task of math word problem type classification.