 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform Stability and Generalization Error of GD and SGD on Fixed-Point Parameters
Jun 05, 2026We analyze generalization error, uniform stability, and uniform argument stability of gradient descent (GD) and stochastic gradient descent (SGD) over discrete parameter spaces, where each update involves deterministic or stochastic rounding. We show that deterministic rounding degrades the generalization error of GD on convex, Lipschitz, and smooth loss functions, increasing the rate from $O(T/n)$ to $O(T/\sqrt{n})$, and establish matching lower bounds. We further prove that uniform stability of GD becomes $Ω(T)$, showing that stability-based generalization bounds are vacuous in this setting. In contrast, for the same losses, stochastic gradient descent with deterministic rounding admits nontrivial uniform stability guarantees, which differ qualitatively from the real-valued case and exhibit distinct dependencies on the number of iterations and the dimension: we prove tight bounds $O(T/n)$ for one dimension and $O(T^2/n)$ for higher dimensions. We also show that stochastic rounding can introduce generalization error that increases with the dimension; such a phenomenon is absent in standard real-valued optimization and in the deterministic rounding case. Finally, we provide upper bounds on uniform argument stability for stochastic rounding schemes and show that these bounds are tight when the loss can be represented as a sum of coordinate-wise functions.
Expressive Power of Floating-Point Neural Networks with Arbitrary Reduction Orders and Inexact Activation Implementations
May 27, 2026Most existing expressivity theories for neural networks assume exact real arithmetic, whereas practical neural networks are executed under finite-precision floating-point arithmetic with implementation-dependent execution semantics. Recent works have begun studying the expressive power of floating-point neural networks, but existing results are limited to highly restricted activation functions and idealized assumptions such as fixed left-to-right reduction orders and correctly rounded activation implementations. In this work, we study the expressive power of floating-point neural networks under generalized floating-point execution semantics, including arbitrary reduction orders and inexact activation implementations with bounded ulp errors. We investigate when floating-point neural networks can represent arbitrary functions between floating-point domains exactly. To this end, we introduce a general distinguishability framework and show that the ability to distinguish every pair of distinct inputs in the first layer is necessary for universal representability. This characterization yields broad classes of activation implementations that are not universal representators, extending previous isolated counterexamples such as the correctly rounded cosine activation. We further prove that a suitable form of distinguishability is also sufficient for universal representability under mild conditions on the activation implementation. Using this framework, we establish universal representability results for a broad class of practical activation functions, including implementations of $\mathrm{Sigmoid}$, $\tanh$, $\mathrm{ReLU}$, $\mathrm{ELU}$, $\mathrm{SeLU}$, $\mathrm{GeLU}$, $\mathrm{Swish}$, $\mathrm{Mish}$, and $\sin$, under significantly more realistic floating-point execution models than previously known.
Floating-Point Networks with Automatic Differentiation Can Represent Almost All Floating-Point Functions and Their Gradients
May 03, 2026Theoretical studies show that for any differentiable function on a compact domain, there exists a neural network that approximates both the function values and gradients. However, such a result cannot be used in practice since it assumes real parameters and exact internal operations. In contrast, real implementations only use a finite subset of reals and machine operations with round-off errors. In this work, we investigate whether a similar result holds for neural networks under floating-point arithmetic, when the gradient with respect to the input is computed by the automatic differentiation algorithm $D^\mathtt{AD}$. We first show that given a floating-point function $φ$ (e.g., a loss function), arbitrary function values and gradients can be represented by a floating-point network $f$ and $D^\mathtt{AD}(φ\circ f)$, respectively. We further extend this result: given $φ_1,\dots,φ_n$, $D^\mathtt{AD}(φ_i\circ f)$ can simultaneously represent arbitrary gradients while $f$ represents the target values, under mild conditions. Our results hold for practical activation functions, e.g., $\mathrm{ReLU}$, $\mathrm{ELU}$, $\mathrm{GeLU}$, $\mathrm{Swish}$, $\mathrm{Sigmoid}$, and $\mathrm{tanh}$.
Mapper-GIN: Lightweight Structural Graph Abstraction for Corrupted 3D Point Cloud Classification
Feb 05, 2026Robust 3D point cloud classification is often pursued by scaling up backbones or relying on specialized data augmentation. We instead ask whether structural abstraction alone can improve robustness, and study a simple topology-inspired decomposition based on the Mapper algorithm. We propose Mapper-GIN, a lightweight pipeline that partitions a point cloud into overlapping regions using Mapper (PCA lens, cubical cover, and followed by density-based clustering), constructs a region graph from their overlaps, and performs graph classification with a Graph Isomorphism Network. On the corruption benchmark ModelNet40-C, Mapper-GIN achieves competitive and stable accuracy under Noise and Transformation corruptions with only 0.5M parameters. In contrast to prior approaches that require heavier architectures or additional mechanisms to gain robustness, Mapper-GIN attains strong corruption robustness through simple region-level graph abstraction and GIN message passing. Overall, our results suggest that region-graph structure offers an efficient and interpretable source of robustness for 3D visual recognition.
On the Expressive Power of Floating-Point Transformers
Jan 23, 2026The study on the expressive power of transformers shows that transformers are permutation equivariant, and they can approximate all permutation-equivariant continuous functions on a compact domain. However, these results are derived under real parameters and exact operations, while real implementations on computers can only use a finite set of numbers and inexact machine operations with round-off errors. In this work, we investigate the representability of floating-point transformers that use floating-point parameters and floating-point operations. Unlike existing results under exact operations, we first show that floating-point transformers can represent a class of non-permutation-equivariant functions even without positional encoding. Furthermore, we prove that floating-point transformers can represent all permutation-equivariant functions when the sequence length is bounded, but they cannot when the sequence length is large. We also found the minimal equivariance structure in floating-point transformers, and show that all non-trivial additive positional encoding can harm the representability of floating-point transformers.
A Framework for Personalized Persuasiveness Prediction via Context-Aware User Profiling
Jan 09, 2026Estimating the persuasiveness of messages is critical in various applications, from recommender systems to safety assessment of LLMs. While it is imperative to consider the target persuadee's characteristics, such as their values, experiences, and reasoning styles, there is currently no established systematic framework to optimize leveraging a persuadee's past activities (e.g., conversations) to the benefit of a persuasiveness prediction model. To address this problem, we propose a context-aware user profiling framework with two trainable components: a query generator that generates optimal queries to retrieve persuasion-relevant records from a user's history, and a profiler that summarizes these records into a profile to effectively inform the persuasiveness prediction model. Our evaluation on the ChangeMyView Reddit dataset shows consistent improvements over existing methods across multiple predictor models, with gains of up to +13.77%p in F1 score. Further analysis shows that effective user profiles are context-dependent and predictor-specific, rather than relying on static attributes or surface-level similarity. Together, these results highlight the importance of task-oriented, context-dependent user profiling for personalized persuasiveness prediction.
Deep Latent Variable Model based Vertical Federated Learning with Flexible Alignment and Labeling Scenarios
May 16, 2025Federated learning (FL) has attracted significant attention for enabling collaborative learning without exposing private data. Among the primary variants of FL, vertical federated learning (VFL) addresses feature-partitioned data held by multiple institutions, each holding complementary information for the same set of users. However, existing VFL methods often impose restrictive assumptions such as a small number of participating parties, fully aligned data, or only using labeled data. In this work, we reinterpret alignment gaps in VFL as missing data problems and propose a unified framework that accommodates both training and inference under arbitrary alignment and labeling scenarios, while supporting diverse missingness mechanisms. In the experiments on 168 configurations spanning four benchmark datasets, six training-time missingness patterns, and seven testing-time missingness patterns, our method outperforms all baselines in 160 cases with an average gap of 9.6 percentage points over the next-best competitors. To the best of our knowledge, this is the first VFL framework to jointly handle arbitrary data alignment, unlabeled data, and multi-party collaboration all at once.
IMPaCT GNN: Imposing invariance with Message Passing in Chronological split Temporal Graphs
Nov 17, 2024This paper addresses domain adaptation challenges in graph data resulting from chronological splits. In a transductive graph learning setting, where each node is associated with a timestamp, we focus on the task of Semi-Supervised Node Classification (SSNC), aiming to classify recent nodes using labels of past nodes. Temporal dependencies in node connections create domain shifts, causing significant performance degradation when applying models trained on historical data into recent data. Given the practical relevance of this scenario, addressing domain adaptation in chronological split data is crucial, yet underexplored. We propose Imposing invariance with Message Passing in Chronological split Temporal Graphs (IMPaCT), a method that imposes invariant properties based on realistic assumptions derived from temporal graph structures. Unlike traditional domain adaptation approaches which rely on unverifiable assumptions, IMPaCT explicitly accounts for the characteristics of chronological splits. The IMPaCT is further supported by rigorous mathematical analysis, including a derivation of an upper bound of the generalization error. Experimentally, IMPaCT achieves a 3.8% performance improvement over current SOTA method on the ogbn-mag graph dataset. Additionally, we introduce the Temporal Stochastic Block Model (TSBM), which replicates temporal graphs under varying conditions, demonstrating the applicability of our methods to general spatial GNNs.
A Kernel Perspective on Distillation-based Collaborative Learning
Oct 23, 2024

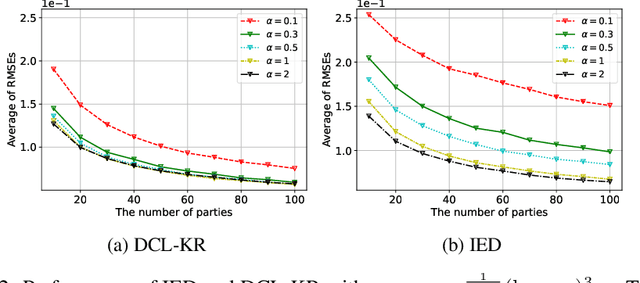

Over the past decade, there is a growing interest in collaborative learning that can enhance AI models of multiple parties. However, it is still challenging to enhance performance them without sharing private data and models from individual parties. One recent promising approach is to develop distillation-based algorithms that exploit unlabeled public data but the results are still unsatisfactory in both theory and practice. To tackle this problem, we rigorously analyze a representative distillation-based algorithm in the view of kernel regression. This work provides the first theoretical results to prove the (nearly) minimax optimality of the nonparametric collaborative learning algorithm that does not directly share local data or models in massively distributed statistically heterogeneous environments. Inspired by our theoretical results, we also propose a practical distillation-based collaborative learning algorithm based on neural network architecture. Our algorithm successfully bridges the gap between our theoretical assumptions and practical settings with neural networks through feature kernel matching. We simulate various regression tasks to verify our theory and demonstrate the practical feasibility of our proposed algorithm.
On Expressive Power of Quantized Neural Networks under Fixed-Point Arithmetic
Aug 30, 2024Research into the expressive power of neural networks typically considers real parameters and operations without rounding error. In this work, we study universal approximation property of quantized networks under discrete fixed-point parameters and fixed-point operations that may incur errors due to rounding. We first provide a necessary condition and a sufficient condition on fixed-point arithmetic and activation functions for universal approximation of quantized networks. Then, we show that various popular activation functions satisfy our sufficient condition, e.g., Sigmoid, ReLU, ELU, SoftPlus, SiLU, Mish, and GELU. In other words, networks using those activation functions are capable of universal approximation. We further show that our necessary condition and sufficient condition coincide under a mild condition on activation functions: e.g., for an activation function $\sigma$, there exists a fixed-point number $x$ such that $\sigma(x)=0$. Namely, we find a necessary and sufficient condition for a large class of activation functions. We lastly show that even quantized networks using binary weights in $\{-1,1\}$ can also universally approximate for practical activation functions.