 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Networks Efficiently Learn Low-Dimensional Representations with SGD
Sep 29, 2022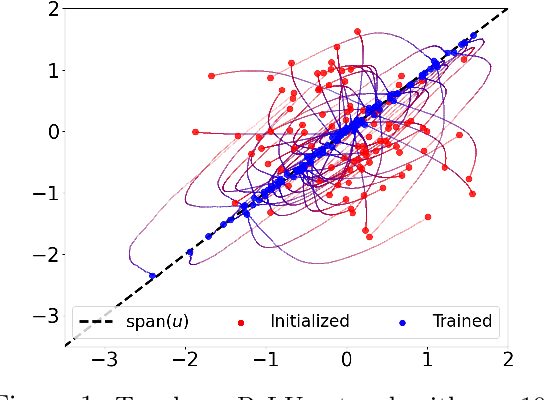
We study the problem of training a two-layer neural network (NN) of arbitrary width using stochastic gradient descent (SGD) where the input $\boldsymbol{x}\in \mathbb{R}^d$ is Gaussian and the target $y \in \mathbb{R}$ follows a multiple-index model, i.e., $y=g(\langle\boldsymbol{u_1},\boldsymbol{x}\rangle,...,\langle\boldsymbol{u_k},\boldsymbol{x}\rangle)$ with a noisy link function $g$. We prove that the first-layer weights of the NN converge to the $k$-dimensional principal subspace spanned by the vectors $\boldsymbol{u_1},...,\boldsymbol{u_k}$ of the true model, when online SGD with weight decay is used for training. This phenomenon has several important consequences when $k \ll d$. First, by employing uniform convergence on this smaller subspace, we establish a generalization error bound of $\mathcal{O}(\sqrt{{kd}/{T}})$ after $T$ iterations of SGD, which is independent of the width of the NN. We further demonstrate that, SGD-trained ReLU NNs can learn a single-index target of the form $y=f(\langle\boldsymbol{u},\boldsymbol{x}\rangle) + \epsilon$ by recovering the principal direction, with a sample complexity linear in $d$ (up to log factors), where $f$ is a monotonic function with at most polynomial growth, and $\epsilon$ is the noise. This is in contrast to the known $d^{\Omega(p)}$ sample requirement to learn any degree $p$ polynomial in the kernel regime, and it shows that NNs trained with SGD can outperform the neural tangent kernel at initialization. Finally, we also provide compressibility guarantees for NNs using the approximate low-rank structure produced by SGD.
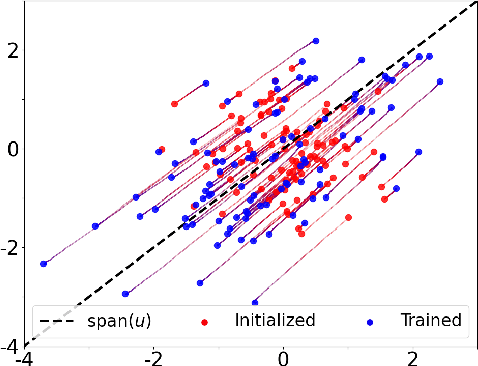
Convergence Analysis and Implicit Regularization of Feedback Alignment for Deep Linear Networks
Oct 20, 2021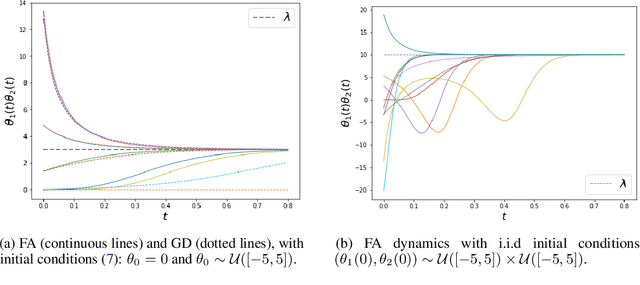
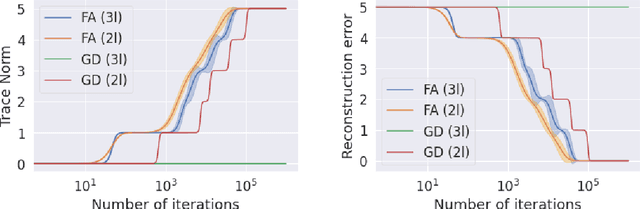
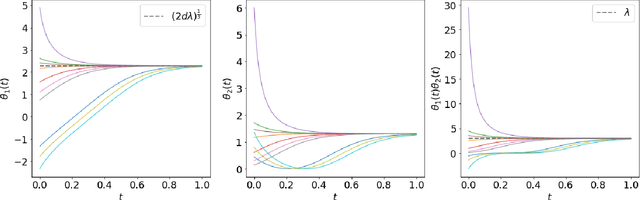
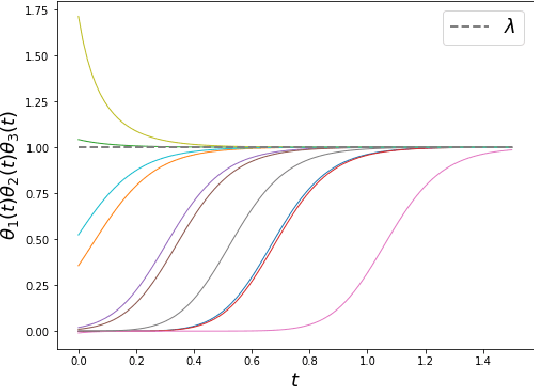
We theoretically analyze the Feedback Alignment (FA) algorithm, an efficient alternative to backpropagation for training neural networks. We provide convergence guarantees with rates for deep linear networks for both continuous and discrete dynamics. Additionally, we study incremental learning phenomena for shallow linear networks. Interestingly, certain specific initializations imply that negligible components are learned before the principal ones, thus potentially negatively affecting the effectiveness of such a learning algorithm; a phenomenon we classify as implicit anti-regularization. We also provide initialization schemes where the components of the problem are approximately learned by decreasing order of importance, thus providing a form of implicit regularization.
A Study of Condition Numbers for First-Order Optimization
Dec 25, 2020
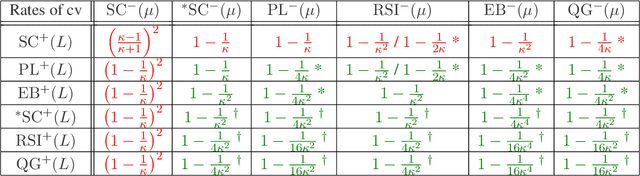
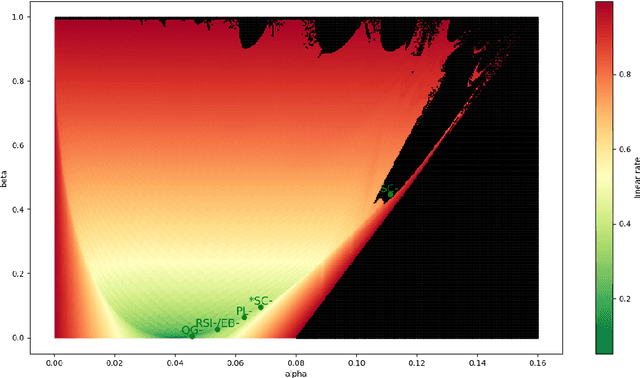
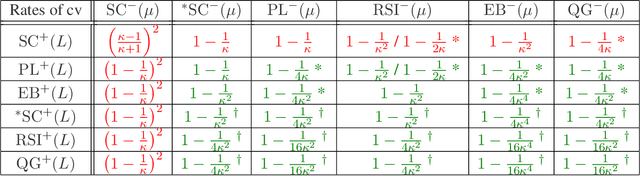
The study of first-order optimization algorithms (FOA) typically starts with assumptions on the objective functions, most commonly smoothness and strong convexity. These metrics are used to tune the hyperparameters of FOA. We introduce a class of perturbations quantified via a new norm, called *-norm. We show that adding a small perturbation to the objective function has an equivalently small impact on the behavior of any FOA, which suggests that it should have a minor impact on the tuning of the algorithm. However, we show that smoothness and strong convexity can be heavily impacted by arbitrarily small perturbations, leading to excessively conservative tunings and convergence issues. In view of these observations, we propose a notion of continuity of the metrics, which is essential for a robust tuning strategy. Since smoothness and strong convexity are not continuous, we propose a comprehensive study of existing alternative metrics which we prove to be continuous. We describe their mutual relations and provide their guaranteed convergence rates for the Gradient Descent algorithm accordingly tuned. Finally we discuss how our work impacts the theoretical understanding of FOA and their performances.