 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Latent Variable Model based Vertical Federated Learning with Flexible Alignment and Labeling Scenarios
May 16, 2025Federated learning (FL) has attracted significant attention for enabling collaborative learning without exposing private data. Among the primary variants of FL, vertical federated learning (VFL) addresses feature-partitioned data held by multiple institutions, each holding complementary information for the same set of users. However, existing VFL methods often impose restrictive assumptions such as a small number of participating parties, fully aligned data, or only using labeled data. In this work, we reinterpret alignment gaps in VFL as missing data problems and propose a unified framework that accommodates both training and inference under arbitrary alignment and labeling scenarios, while supporting diverse missingness mechanisms. In the experiments on 168 configurations spanning four benchmark datasets, six training-time missingness patterns, and seven testing-time missingness patterns, our method outperforms all baselines in 160 cases with an average gap of 9.6 percentage points over the next-best competitors. To the best of our knowledge, this is the first VFL framework to jointly handle arbitrary data alignment, unlabeled data, and multi-party collaboration all at once.
A Kernel Perspective on Distillation-based Collaborative Learning
Oct 23, 2024

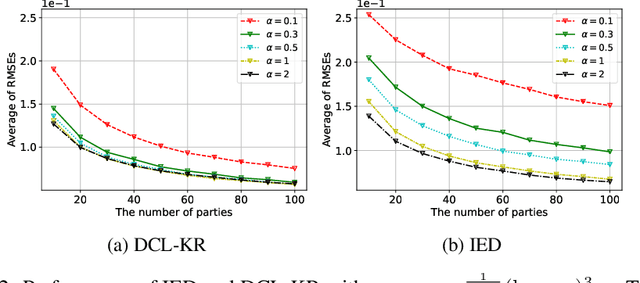

Over the past decade, there is a growing interest in collaborative learning that can enhance AI models of multiple parties. However, it is still challenging to enhance performance them without sharing private data and models from individual parties. One recent promising approach is to develop distillation-based algorithms that exploit unlabeled public data but the results are still unsatisfactory in both theory and practice. To tackle this problem, we rigorously analyze a representative distillation-based algorithm in the view of kernel regression. This work provides the first theoretical results to prove the (nearly) minimax optimality of the nonparametric collaborative learning algorithm that does not directly share local data or models in massively distributed statistically heterogeneous environments. Inspired by our theoretical results, we also propose a practical distillation-based collaborative learning algorithm based on neural network architecture. Our algorithm successfully bridges the gap between our theoretical assumptions and practical settings with neural networks through feature kernel matching. We simulate various regression tasks to verify our theory and demonstrate the practical feasibility of our proposed algorithm.