 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSampling is Matter: Point-guided 3D Human Mesh Reconstruction
Apr 19, 2023



This paper presents a simple yet powerful method for 3D human mesh reconstruction from a single RGB image. Most recently, the non-local interactions of the whole mesh vertices have been effectively estimated in the transformer while the relationship between body parts also has begun to be handled via the graph model. Even though those approaches have shown the remarkable progress in 3D human mesh reconstruction, it is still difficult to directly infer the relationship between features, which are encoded from the 2D input image, and 3D coordinates of each vertex. To resolve this problem, we propose to design a simple feature sampling scheme. The key idea is to sample features in the embedded space by following the guide of points, which are estimated as projection results of 3D mesh vertices (i.e., ground truth). This helps the model to concentrate more on vertex-relevant features in the 2D space, thus leading to the reconstruction of the natural human pose. Furthermore, we apply progressive attention masking to precisely estimate local interactions between vertices even under severe occlusions. Experimental results on benchmark datasets show that the proposed method efficiently improves the performance of 3D human mesh reconstruction. The code and model are publicly available at: https://github.com/DCVL-3D/PointHMR_release.
Weakly-Supervised Stitching Network for Real-World Panoramic Image Generation
Sep 13, 2022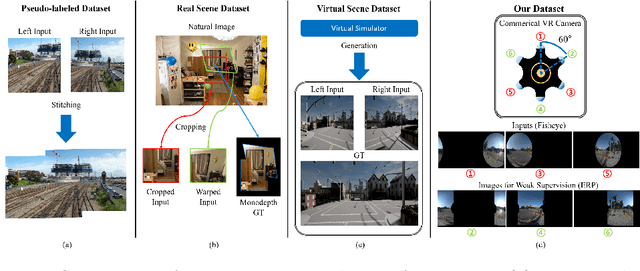
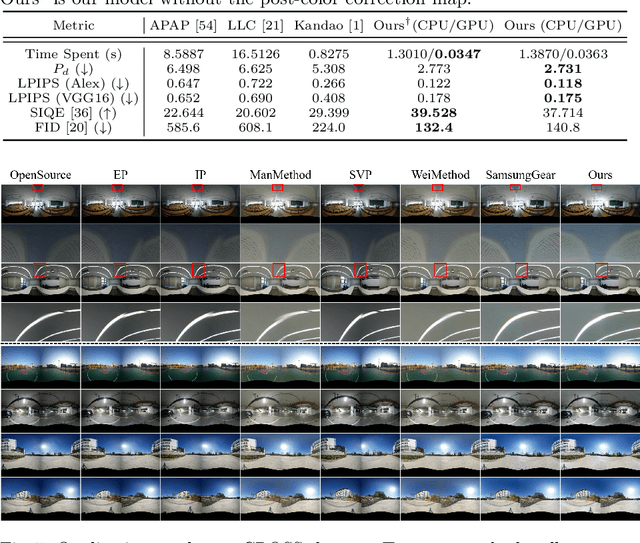
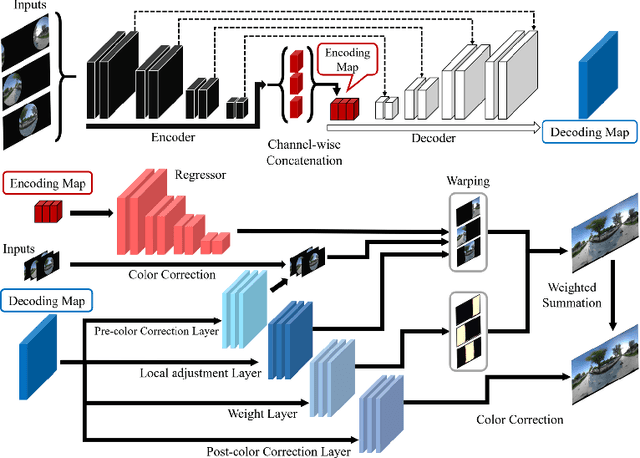

Recently, there has been growing attention on an end-to-end deep learning-based stitching model. However, the most challenging point in deep learning-based stitching is to obtain pairs of input images with a narrow field of view and ground truth images with a wide field of view captured from real-world scenes. To overcome this difficulty, we develop a weakly-supervised learning mechanism to train the stitching model without requiring genuine ground truth images. In addition, we propose a stitching model that takes multiple real-world fisheye images as inputs and creates a 360 output image in an equirectangular projection format. In particular, our model consists of color consistency corrections, warping, and blending, and is trained by perceptual and SSIM losses. The effectiveness of the proposed algorithm is verified on two real-world stitching datasets.