 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped Diffusion Language Models
May 25, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models for language modeling, yet the effective design of transformer architectures for MDMs remains underexplored. In this paper, we show that selectively looping the early-middle transformer layers significantly improves both training efficiency and model performance in MDMs. We call this approach LoopMDM(Looped Masked Diffusion Model), which brings two key benefits: looping layers at training-time yields a depth-scaling effect without adding parameters, while varying the number of loops at inference-time enables flexible compute scaling. Despite the simplicity, the results are striking: across multiple pre-training corpora, LoopMDM matches the performance of same-size MDMs with up to 3.3 fewer training FLOPs, while its final performance outperforms them on various reasoning benchmarks, including up to 8.5 points on GSM8K. It even surpasses deeper non-looped MDMs trained with comparable per-step compute, indicating that selective looping is more effective than naive depth scaling. Furthermore, LoopMDM can scale inference-time compute by increasing the number of loops. Adaptively adjusting the number of loops throughout the sampling process further yields additional gains in compute efficiency while maintaining performance. Lastly, with attention analysis, we provide evidence that looping is effective in MDMs by promoting interactions among masked positions. Our code and weights will be publicly released.
Understanding and Accelerating the Training of Masked Diffusion Language Models
May 13, 2026Masked diffusion models (MDMs) have emerged as a promising alternative to autoregressive models (ARMs) for language modeling. However, MDMs are known to learn substantially more slowly than ARMs, which may become problematic when scaling MDMs to larger models. Therefore, we ask the following question: how can we accelerate standard MDM training while maintaining its final performance? To this end, we first provide a detailed analysis of why MDM training is slow. We find that the main factor is the locality bias of language: the predictive information for a token is concentrated in nearby positions. We further investigate how this bias slows learning and suggest a simple yet effective remedy: bell-shaped time sampling as a training strategy. Notably, MDMs trained with our training recipe reach the same validation negative log-likelihood (NLL) up to $\sim4\times$ faster than standard training on One Billion Word Benchmark (LM1B). We also show faster improvements in generative perplexity, zero-shot perplexity, and downstream task performance on various benchmarks.
Unifying Masked Diffusion Models with Various Generation Orders and Beyond
Feb 02, 2026Masked diffusion models (MDMs) are a potential alternative to autoregressive models (ARMs) for language generation, but generation quality depends critically on the generation order. Prior work either hard-codes an ordering (e.g., blockwise left-to-right) or learns an ordering policy for a pretrained MDM, which incurs extra cost and can yield suboptimal solutions due to the two-stage optimization. Motivated by this, we propose order-expressive masked diffusion model (OeMDM) for a broad class of diffusion generative processes with various generation orders, enabling the interpretation of MDM, ARM, and block diffusion in a single framework. Furthermore, building on OeMDM, we introduce learnable-order masked diffusion model (LoMDM), which jointly learns the generation ordering and diffusion backbone through a single objective from scratch, enabling the diffusion model to generate text in context-dependent ordering. Empirically, we confirm that LoMDM outperforms various discrete diffusion models across multiple language modeling benchmarks.
Discontinuous Galerkin finite element operator network for solving non-smooth PDEs
Jan 07, 2026We introduce Discontinuous Galerkin Finite Element Operator Network (DG--FEONet), a data-free operator learning framework that combines the strengths of the discontinuous Galerkin (DG) method with neural networks to solve parametric partial differential equations (PDEs) with discontinuous coefficients and non-smooth solutions. Unlike traditional operator learning models such as DeepONet and Fourier Neural Operator, which require large paired datasets and often struggle near sharp features, our approach minimizes the residual of a DG-based weak formulation using the Symmetric Interior Penalty Galerkin (SIPG) scheme. DG-FEONet predicts element-wise solution coefficients via a neural network, enabling data-free training without the need for precomputed input-output pairs. We provide theoretical justification through convergence analysis and validate the model's performance on a series of one- and two-dimensional PDE problems, demonstrating accurate recovery of discontinuities, strong generalization across parameter space, and reliable convergence rates. Our results highlight the potential of combining local discretization schemes with machine learning to achieve robust, singularity-aware operator approximation in challenging PDE settings.
Fine-Grained Perturbation Guidance via Attention Head Selection
Jun 12, 2025Recent guidance methods in diffusion models steer reverse sampling by perturbing the model to construct an implicit weak model and guide generation away from it. Among these approaches, attention perturbation has demonstrated strong empirical performance in unconditional scenarios where classifier-free guidance is not applicable. However, existing attention perturbation methods lack principled approaches for determining where perturbations should be applied, particularly in Diffusion Transformer (DiT) architectures where quality-relevant computations are distributed across layers. In this paper, we investigate the granularity of attention perturbations, ranging from the layer level down to individual attention heads, and discover that specific heads govern distinct visual concepts such as structure, style, and texture quality. Building on this insight, we propose "HeadHunter", a systematic framework for iteratively selecting attention heads that align with user-centric objectives, enabling fine-grained control over generation quality and visual attributes. In addition, we introduce SoftPAG, which linearly interpolates each selected head's attention map toward an identity matrix, providing a continuous knob to tune perturbation strength and suppress artifacts. Our approach not only mitigates the oversmoothing issues of existing layer-level perturbation but also enables targeted manipulation of specific visual styles through compositional head selection. We validate our method on modern large-scale DiT-based text-to-image models including Stable Diffusion 3 and FLUX.1, demonstrating superior performance in both general quality enhancement and style-specific guidance. Our work provides the first head-level analysis of attention perturbation in diffusion models, uncovering interpretable specialization within attention layers and enabling practical design of effective perturbation strategies.
A Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
Continual Traffic Forecasting via Mixture of Experts
Jun 05, 2024



The real-world traffic networks undergo expansion through the installation of new sensors, implying that the traffic patterns continually evolve over time. Incrementally training a model on the newly added sensors would make the model forget the past knowledge, i.e., catastrophic forgetting, while retraining the model on the entire network to capture these changes is highly inefficient. To address these challenges, we propose a novel Traffic Forecasting Mixture of Experts (TFMoE) for traffic forecasting under evolving networks. The main idea is to segment the traffic flow into multiple homogeneous groups, and assign an expert model responsible for a specific group. This allows each expert model to concentrate on learning and adapting to a specific set of patterns, while minimizing interference between the experts during training, thereby preventing the dilution or replacement of prior knowledge, which is a major cause of catastrophic forgetting. Through extensive experiments on a real-world long-term streaming network dataset, PEMSD3-Stream, we demonstrate the effectiveness and efficiency of TFMoE. Our results showcase superior performance and resilience in the face of catastrophic forgetting, underscoring the effectiveness of our approach in dealing with continual learning for traffic flow forecasting in long-term streaming networks.
Temporal Graph Learning Recurrent Neural Network for Traffic Forecasting
Jun 04, 2024Accurate traffic flow forecasting is a crucial research topic in transportation management. However, it is a challenging problem due to rapidly changing traffic conditions, high nonlinearity of traffic flow, and complex spatial and temporal correlations of road networks. Most existing studies either try to capture the spatial dependencies between roads using the same semantic graph over different time steps, or assume all sensors on the roads are equally likely to be connected regardless of the distance between them. However, we observe that the spatial dependencies between roads indeed change over time, and two distant roads are not likely to be helpful to each other when predicting the traffic flow, both of which limit the performance of existing studies. In this paper, we propose Temporal Graph Learning Recurrent Neural Network (TGLRN) to address these problems. More precisely, to effectively model the nature of time series, we leverage Recurrent Neural Networks (RNNs) to dynamically construct a graph at each time step, thereby capturing the time-evolving spatial dependencies between roads (i.e., microscopic view). Simultaneously, we provide the Adaptive Structure Information to the model, ensuring that close and consecutive sensors are considered to be more important for predicting the traffic flow (i.e., macroscopic view). Furthermore, to endow TGLRN with robustness, we introduce an edge sampling strategy when constructing the graph at each time step, which eventually leads to further improvements on the model performance. Experimental results on four commonly used real-world benchmark datasets show the effectiveness of TGLRN.
Safe and Efficient Trajectory Optimization for Autonomous Vehicles using B-spline with Incremental Path Flattening
Nov 13, 2023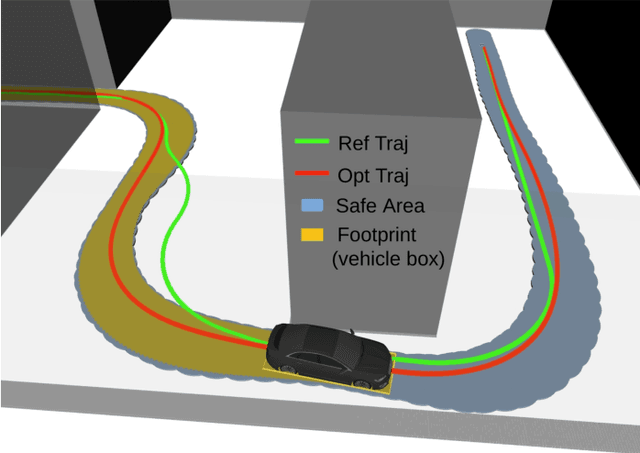
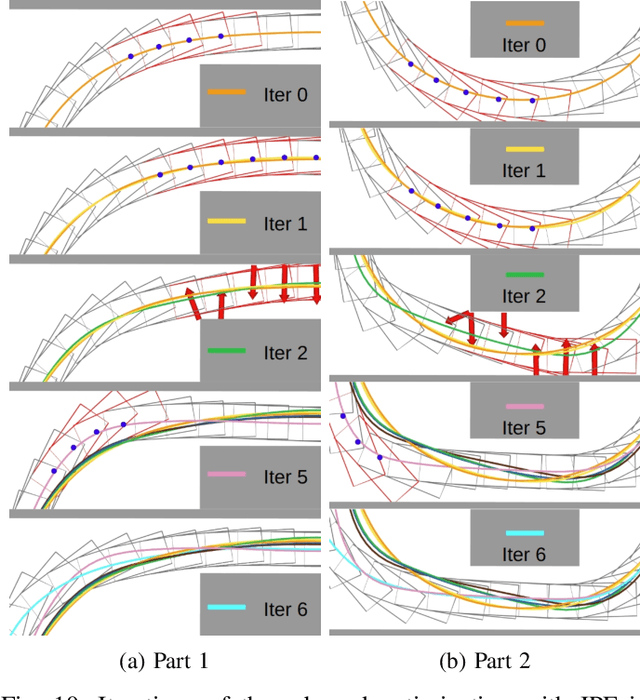
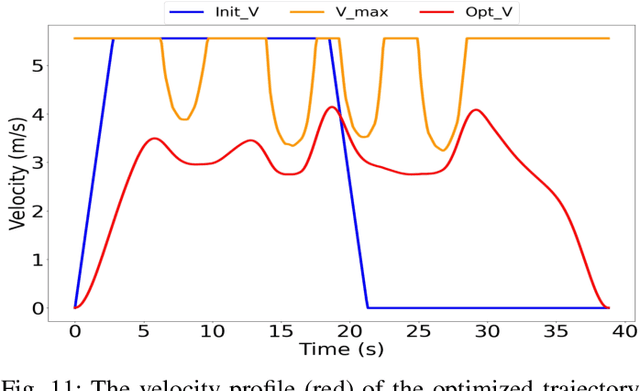
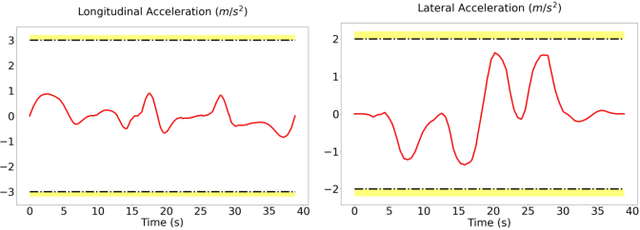
B-spline-based trajectory optimization has been widely used in robot navigation, especially as quadrotor-like vehicles can easily enjoy the advantage of a B-spline curve (e.g. computational efficiency) with its convex hull property for trajectory optimization. Nevertheless, leveraging the B-splined-based optimization algorithm to generate a collision-free trajectory for autonomous vehicles is still challenging because their complex vehicle kinematics make it difficult to use the convex hull property. In this paper, we propose a novel trajectory optimization algorithm for autonomous vehicles that enables the advantage of a B-spline curve into a B-spline-based optimization algorithm by incorporating vehicle kinematics with two methods. An incremental path flattening is a new method that iteratively increases path curvature weight around vehicle collision points to find a collision-free path by reducing swept volume. A new swept volume estimation method can reduce over-approximation of the swept volume and make the vehicle pass through a narrow corridor without losing safety. Furthermore, a clamped B-spline curvature constraint, which can simplify a B-spline curvature constraint, is added with other feasibility constraints (e.g. longitudinal \& lateral velocity and acceleration) for the vehicle kinodynamic constraints. Our experimental results demonstrate that our method outperforms state-of-the-art baselines in various simulated environments and verifies its valid tracking performance with an autonomous vehicle in a real-world scenario.
On the training and generalization of deep operator networks
Sep 02, 2023We present a novel training method for deep operator networks (DeepONets), one of the most popular neural network models for operators. DeepONets are constructed by two sub-networks, namely the branch and trunk networks. Typically, the two sub-networks are trained simultaneously, which amounts to solving a complex optimization problem in a high dimensional space. In addition, the nonconvex and nonlinear nature makes training very challenging. To tackle such a challenge, we propose a two-step training method that trains the trunk network first and then sequentially trains the branch network. The core mechanism is motivated by the divide-and-conquer paradigm and is the decomposition of the entire complex training task into two subtasks with reduced complexity. Therein the Gram-Schmidt orthonormalization process is introduced which significantly improves stability and generalization ability. On the theoretical side, we establish a generalization error estimate in terms of the number of training data, the width of DeepONets, and the number of input and output sensors. Numerical examples are presented to demonstrate the effectiveness of the two-step training method, including Darcy flow in heterogeneous porous media.