 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasurement-Consistent Langevin Corrector: A Remedy for Latent Diffusion Inverse Solvers
Jan 08, 2026With recent advances in generative models, diffusion models have emerged as powerful priors for solving inverse problems in each domain. Since Latent Diffusion Models (LDMs) provide generic priors, several studies have explored their potential as domain-agnostic zero-shot inverse solvers. Despite these efforts, existing latent diffusion inverse solvers suffer from their instability, exhibiting undesirable artifacts and degraded quality. In this work, we first identify the instability as a discrepancy between the solver's and true reverse diffusion dynamics, and show that reducing this gap stabilizes the solver. Building on this, we introduce Measurement-Consistent Langevin Corrector (MCLC), a theoretically grounded plug-and-play correction module that remedies the LDM-based inverse solvers through measurement-consistent Langevin updates. Compared to prior approaches that rely on linear manifold assumptions, which often do not hold in latent space, MCLC operates without this assumption, leading to more stable and reliable behavior. We experimentally demonstrate the effectiveness of MCLC and its compatibility with existing solvers across diverse image restoration tasks. Additionally, we analyze blob artifacts and offer insights into their underlying causes. We highlight that MCLC is a key step toward more robust zero-shot inverse problem solvers.
Identity-preserving Distillation Sampling by Fixed-Point Iterator
Feb 27, 2025Score distillation sampling (SDS) demonstrates a powerful capability for text-conditioned 2D image and 3D object generation by distilling the knowledge from learned score functions. However, SDS often suffers from blurriness caused by noisy gradients. When SDS meets the image editing, such degradations can be reduced by adjusting bias shifts using reference pairs, but the de-biasing techniques are still corrupted by erroneous gradients. To this end, we introduce Identity-preserving Distillation Sampling (IDS), which compensates for the gradient leading to undesired changes in the results. Based on the analysis that these errors come from the text-conditioned scores, a new regularization technique, called fixed-point iterative regularization (FPR), is proposed to modify the score itself, driving the preservation of the identity even including poses and structures. Thanks to a self-correction by FPR, the proposed method provides clear and unambiguous representations corresponding to the given prompts in image-to-image editing and editable neural radiance field (NeRF). The structural consistency between the source and the edited data is obviously maintained compared to other state-of-the-art methods.
A Noise is Worth Diffusion Guidance
Dec 05, 2024
Diffusion models excel in generating high-quality images. However, current diffusion models struggle to produce reliable images without guidance methods, such as classifier-free guidance (CFG). Are guidance methods truly necessary? Observing that noise obtained via diffusion inversion can reconstruct high-quality images without guidance, we focus on the initial noise of the denoising pipeline. By mapping Gaussian noise to `guidance-free noise', we uncover that small low-magnitude low-frequency components significantly enhance the denoising process, removing the need for guidance and thus improving both inference throughput and memory. Expanding on this, we propose \ours, a novel method that replaces guidance methods with a single refinement of the initial noise. This refined noise enables high-quality image generation without guidance, within the same diffusion pipeline. Our noise-refining model leverages efficient noise-space learning, achieving rapid convergence and strong performance with just 50K text-image pairs. We validate its effectiveness across diverse metrics and analyze how refined noise can eliminate the need for guidance. See our project page: https://cvlab-kaist.github.io/NoiseRefine/.
DeepPhaseCut: Deep Relaxation in Phase for Unsupervised Fourier Phase Retrieval
Nov 20, 2020
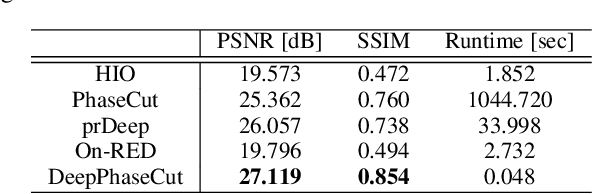
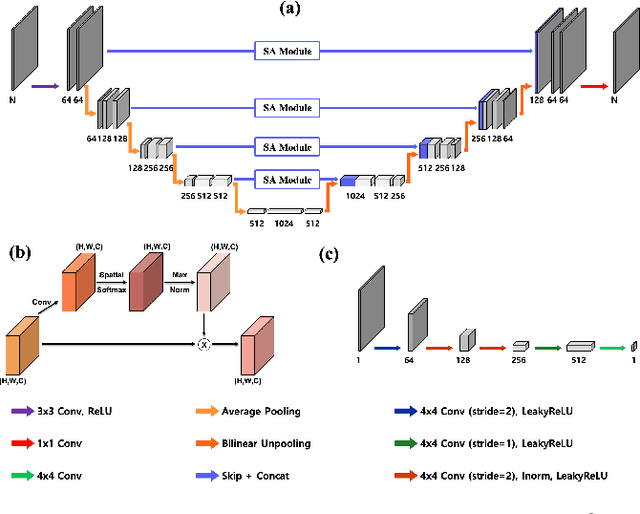
Fourier phase retrieval is a classical problem of restoring a signal only from the measured magnitude of its Fourier transform. Although Fienup-type algorithms, which use prior knowledge in both spatial and Fourier domains, have been widely used in practice, they can often stall in local minima. Modern methods such as PhaseLift and PhaseCut may offer performance guarantees with the help of convex relaxation. However, these algorithms are usually computationally intensive for practical use. To address this problem, we propose a novel, unsupervised, feed-forward neural network for Fourier phase retrieval which enables immediate high quality reconstruction. Unlike the existing deep learning approaches that use a neural network as a regularization term or an end-to-end blackbox model for supervised training, our algorithm is a feed-forward neural network implementation of PhaseCut algorithm in an unsupervised learning framework. Specifically, our network is composed of two generators: one for the phase estimation using PhaseCut loss, followed by another generator for image reconstruction, all of which are trained simultaneously using a cycleGAN framework without matched data. The link to the classical Fienup-type algorithms and the recent symmetry-breaking learning approach is also revealed. Extensive experiments demonstrate that the proposed method outperforms all existing approaches in Fourier phase retrieval problems.
Two-Stage Deep Learning for Accelerated 3D Time-of-Flight MRA without Matched Training Data
Aug 04, 2020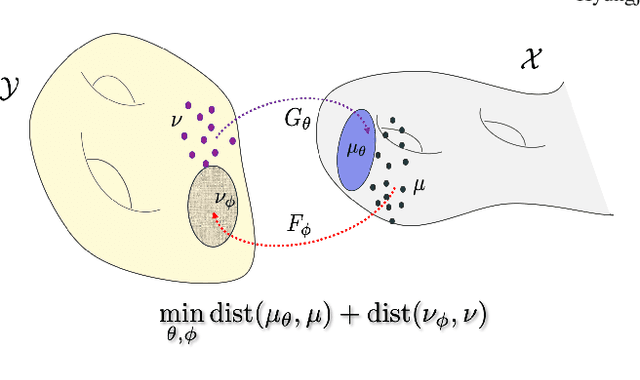
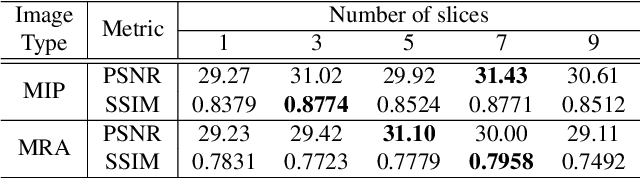
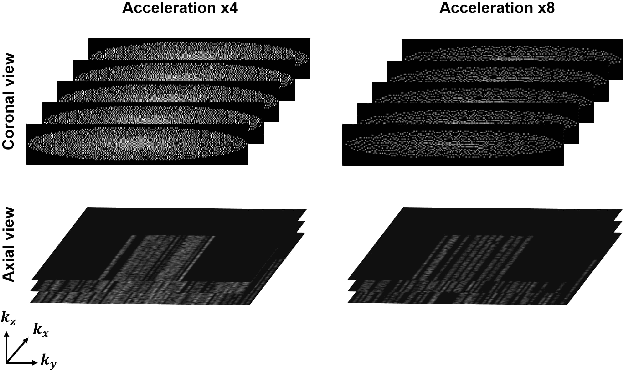
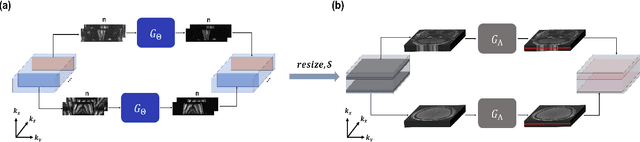
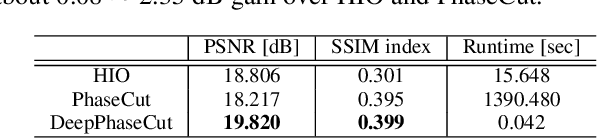
Time-of-flight magnetic resonance angiography (TOF-MRA) is one of the most widely used non-contrast MR imaging methods to visualize blood vessels, but due to the 3-D volume acquisition highly accelerated acquisition is necessary. Accordingly, high quality reconstruction from undersampled TOF-MRA is an important research topic for deep learning. However, most existing deep learning works require matched reference data for supervised training, which are often difficult to obtain. By extending the recent theoretical understanding of cycleGAN from the optimal transport theory, here we propose a novel two-stage unsupervised deep learning approach, which is composed of the multi-coil reconstruction network along the coronal plane followed by a multi-planar refinement network along the axial plane. Specifically, the first network is trained in the square-root of sum of squares (SSoS) domain to achieve high quality parallel image reconstruction, whereas the second refinement network is designed to efficiently learn the characteristics of highly-activated blood flow using double-headed max-pool discriminator. Extensive experiments demonstrate that the proposed learning process without matched reference exceeds performance of state-of-the-art compressed sensing (CS)-based method and provides comparable or even better results than supervised learning approaches.
Unsupervised Deep Learning for MR Angiography with Flexible Temporal Resolution
Mar 29, 2020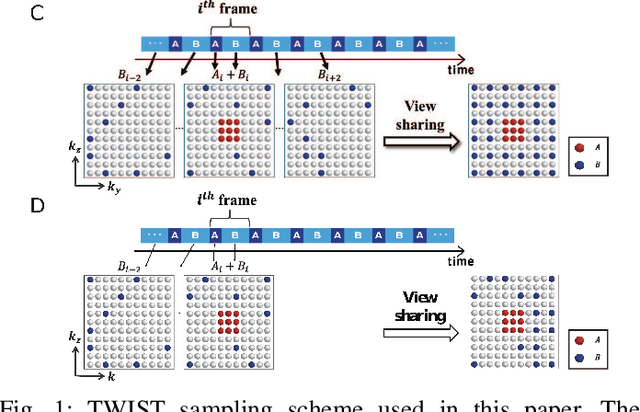
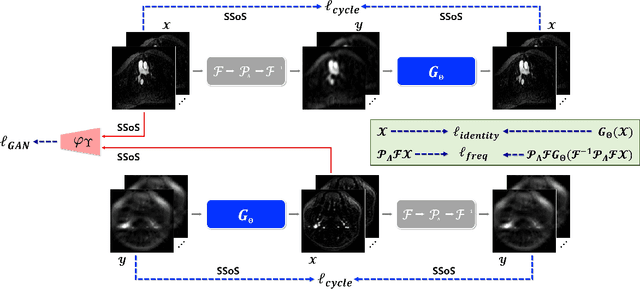
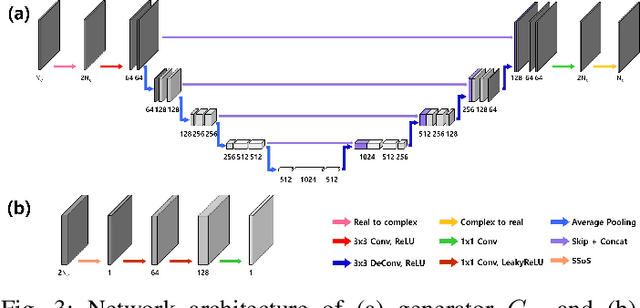
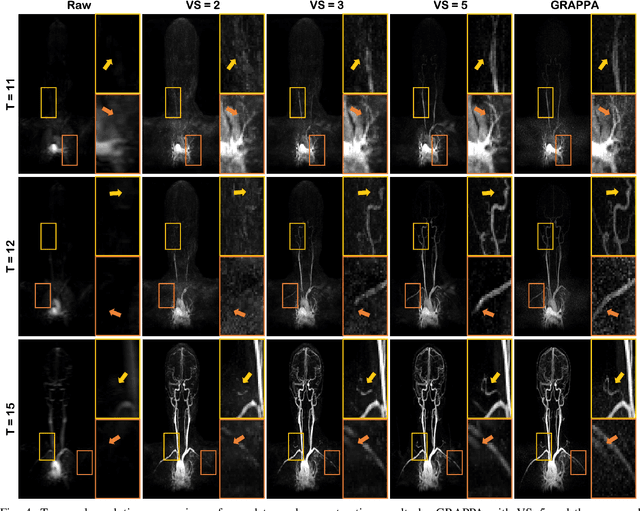
Time-resolved MR angiography (tMRA) has been widely used for dynamic contrast enhanced MRI (DCE-MRI) due to its highly accelerated acquisition. In tMRA, the periphery of the k-space data are sparsely sampled so that neighbouring frames can be merged to construct one temporal frame. However, this view-sharing scheme fundamentally limits the temporal resolution, and it is not possible to change the view-sharing number to achieve different spatio-temporal resolution trade-off. Although many deep learning approaches have been recently proposed for MR reconstruction from sparse samples, the existing approaches usually require matched fully sampled k-space reference data for supervised training, which is not suitable for tMRA. This is because high spatio-temporal resolution ground-truth images are not available for tMRA. To address this problem, here we propose a novel unsupervised deep learning using optimal transport driven cycle-consistent generative adversarial network (cycleGAN). In contrast to the conventional cycleGAN with two pairs of generator and discriminator, the new architecture requires just a single pair of generator and discriminator, which makes the training much simpler and improves the performance. Reconstruction results using in vivo tMRA data set confirm that the proposed method can immediately generate high quality reconstruction results at various choices of view-sharing numbers, allowing us to exploit better trade-off between spatial and temporal resolution in time-resolved MR angiography.
Geometric Approaches to Increase the Expressivity of Deep Neural Networks for MR Reconstruction
Mar 17, 2020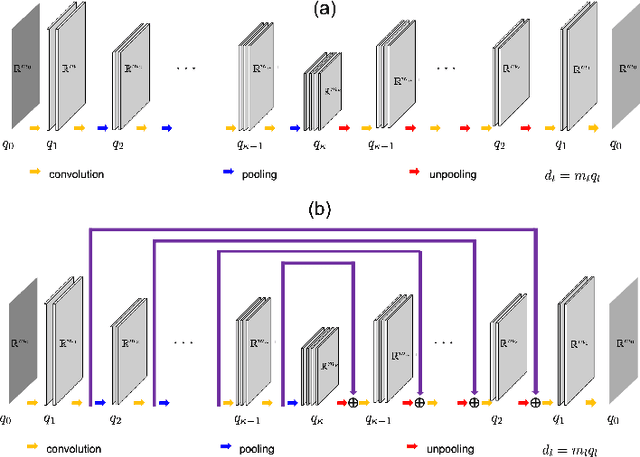
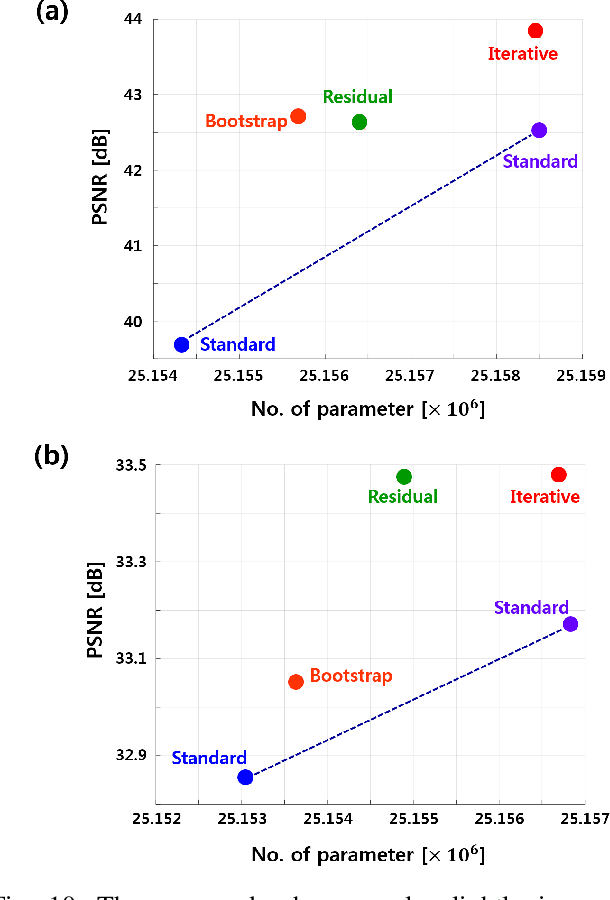
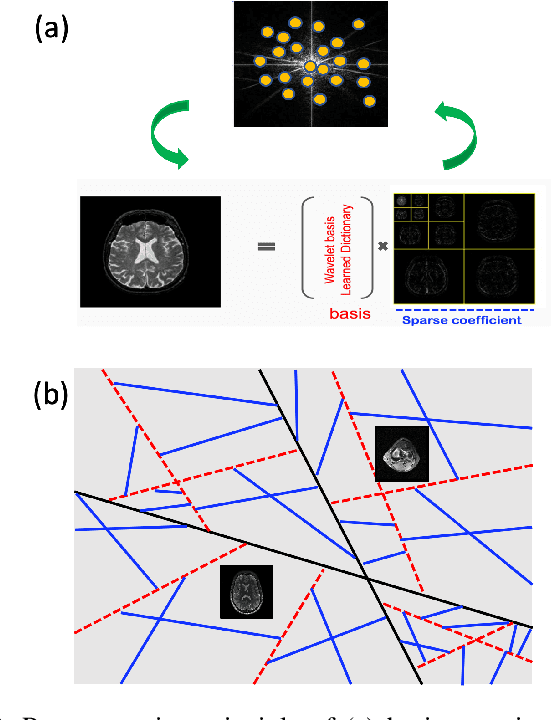
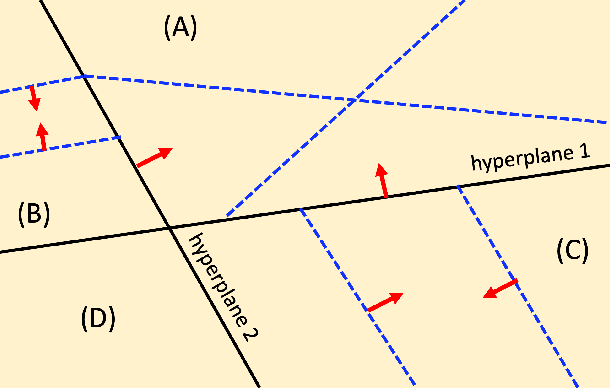
Recently, deep learning approaches have been extensively investigated to reconstruct images from accelerated magnetic resonance image (MRI) acquisition. Although these approaches provide significant performance gain compared to compressed sensing MRI (CS-MRI), it is not clear how to choose a suitable network architecture to balance the trade-off between network complexity and performance. Recently, it was shown that an encoder-decoder convolutional neural network (CNN) can be interpreted as a piecewise linear basis-like representation, whose specific representation is determined by the ReLU activation patterns for a given input image. Thus, the expressivity or the representation power is determined by the number of piecewise linear regions. As an extension of this geometric understanding, this paper proposes a systematic geometric approach using bootstrapping and subnetwork aggregation using an attention module to increase the expressivity of the underlying neural network. Our method can be implemented in both k-space domain and image domain that can be trained in an end-to-end manner. Experimental results show that the proposed schemes significantly improve reconstruction performance with negligible complexity increases.
Boosting CNN beyond Label in Inverse Problems
Jun 18, 2019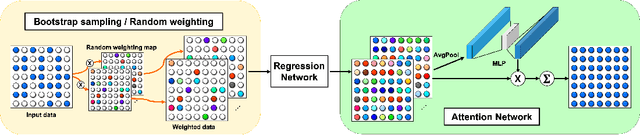

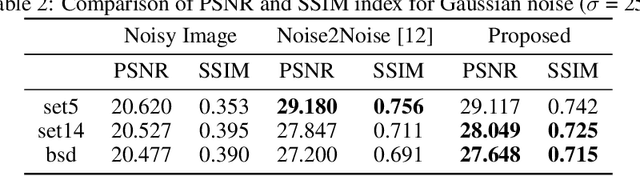
Convolutional neural networks (CNN) have been extensively used for inverse problems. However, their prediction error for unseen test data is difficult to estimate a priori since the neural networks are trained using only selected data and their architecture are largely considered a blackbox. This poses a fundamental challenge to neural networks for unsupervised learning or improvement beyond the label. In this paper, we show that the recent unsupervised learning methods such as Noise2Noise, Stein's unbiased risk estimator (SURE)-based denoiser, and Noise2Void are closely related to each other in their formulation of an unbiased estimator of the prediction error, but each of them are associated with its own limitations. Based on these observations, we provide a novel boosting estimator for the prediction error. In particular, by employing combinatorial convolutional frame representation of encoder-decoder CNN and synergistically combining it with the batch normalization, we provide a close form formulation for the unbiased estimator of the prediction error that can be minimized for neural network training beyond the label. Experimental results show that the resulting algorithm, what we call Noise2Boosting, provides consistent improvement in various inverse problems under both supervised and unsupervised learning setting.
k-Space Deep Learning for Parallel MRI: Application to Time-Resolved MR Angiography
Jun 10, 2018
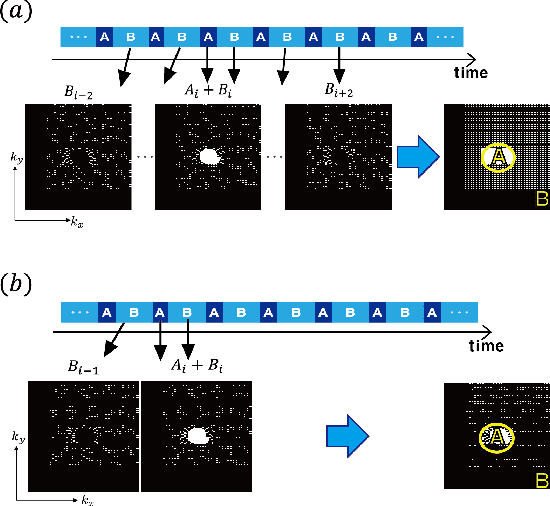
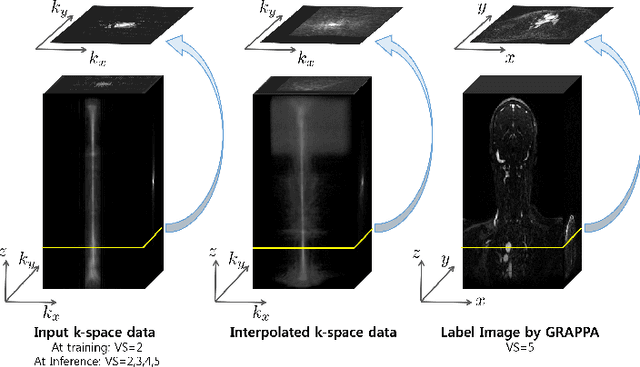
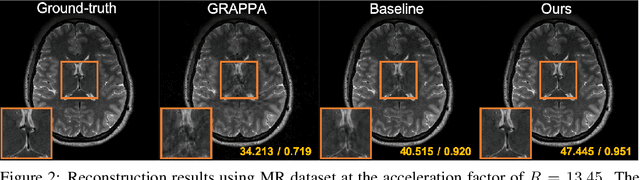
Time-resolved angiography with interleaved stochastic trajectories (TWIST) has been widely used for dynamic contrast enhanced MRI (DCE-MRI). To achieve highly accelerated acquisitions, TWIST combines the periphery of the k-space data from several adjacent frames to reconstruct one temporal frame. However, this view-sharing scheme limits the true temporal resolution of TWIST. Moreover, the k-space sampling patterns have been specially designed for a specific generalized autocalibrating partial parallel acquisition (GRAPPA) factor so that it is not possible to reduce the number of view-sharing once the k-data is acquired. To address these issues, this paper proposes a novel k-space deep learning approach for parallel MRI. In particular, we have designed our neural network so that accurate k-space interpolations are performed simultaneously for multiple coils by exploiting the redundancies along the coils and images. Reconstruction results using in vivo TWIST data set confirm that the proposed method can immediately generate high-quality reconstruction results with various choices of view- sharing, allowing us to exploit the trade-off between spatial and temporal resolution in time-resolved MR angiography.
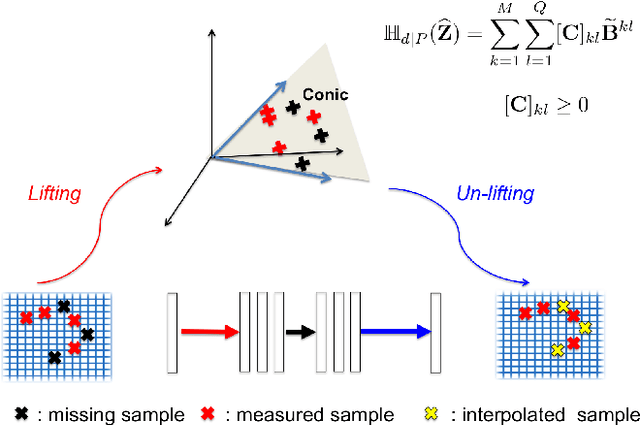
Deep Convolutional Framelets: A General Deep Learning Framework for Inverse Problems
Jan 25, 2018
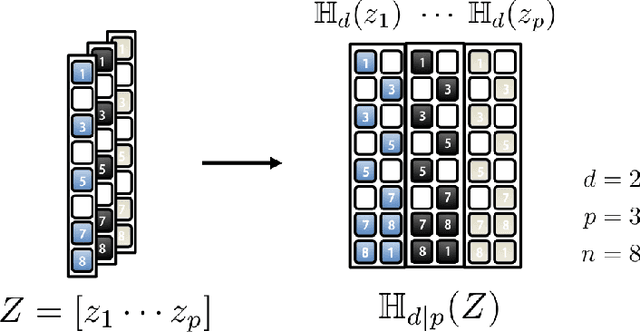
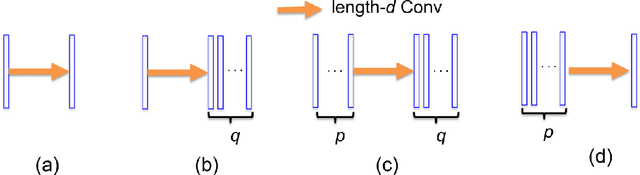
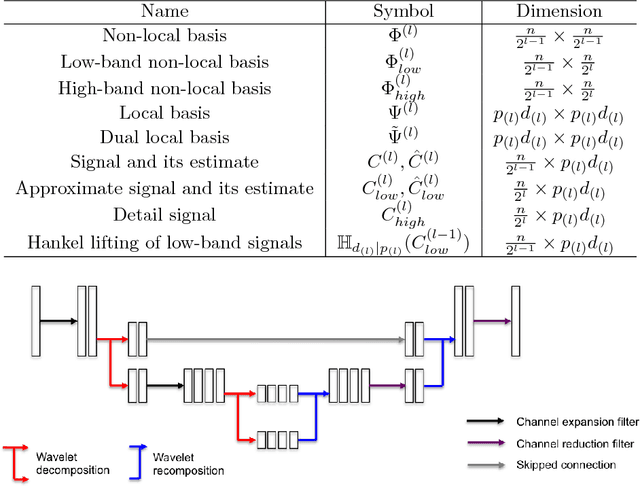
Recently, deep learning approaches with various network architectures have achieved significant performance improvement over existing iterative reconstruction methods in various imaging problems. However, it is still unclear why these deep learning architectures work for specific inverse problems. To address these issues, here we show that the long-searched-for missing link is the convolution framelets for representing a signal by convolving local and non-local bases. The convolution framelets was originally developed to generalize the theory of low-rank Hankel matrix approaches for inverse problems, and this paper further extends the idea so that we can obtain a deep neural network using multilayer convolution framelets with perfect reconstruction (PR) under rectilinear linear unit nonlinearity (ReLU). Our analysis also shows that the popular deep network components such as residual block, redundant filter channels, and concatenated ReLU (CReLU) do indeed help to achieve the PR, while the pooling and unpooling layers should be augmented with high-pass branches to meet the PR condition. Moreover, by changing the number of filter channels and bias, we can control the shrinkage behaviors of the neural network. This discovery leads us to propose a novel theory for deep convolutional framelets neural network. Using numerical experiments with various inverse problems, we demonstrated that our deep convolution framelets network shows consistent improvement over existing deep architectures.This discovery suggests that the success of deep learning is not from a magical power of a black-box, but rather comes from the power of a novel signal representation using non-local basis combined with data-driven local basis, which is indeed a natural extension of classical signal processing theory.