 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Automated Detection of Microbleeds with Anatomical Scale Localization: A Complete Clinical Diagnosis Support Using Deep Learning
Jun 22, 2023
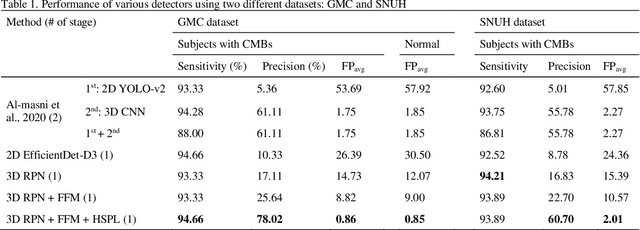
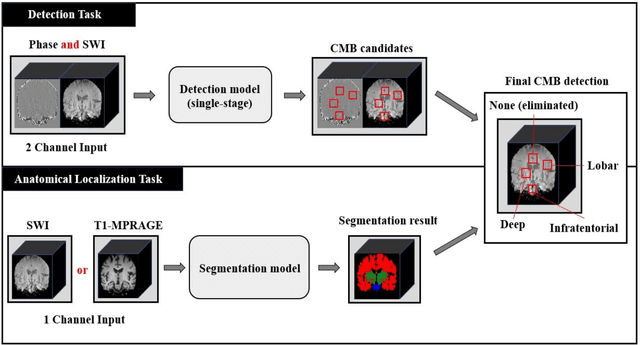
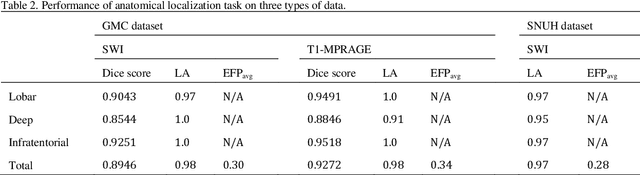
Cerebral Microbleeds (CMBs) are chronic deposits of small blood products in the brain tissues, which have explicit relation to various cerebrovascular diseases depending on their anatomical location, including cognitive decline, intracerebral hemorrhage, and cerebral infarction. However, manual detection of CMBs is a time-consuming and error-prone process because of their sparse and tiny structural properties. The detection of CMBs is commonly affected by the presence of many CMB mimics that cause a high false-positive rate (FPR), such as calcification and pial vessels. This paper proposes a novel 3D deep learning framework that does not only detect CMBs but also inform their anatomical location in the brain (i.e., lobar, deep, and infratentorial regions). For the CMB detection task, we propose a single end-to-end model by leveraging the U-Net as a backbone with Region Proposal Network (RPN). To significantly reduce the FPs within the same single model, we develop a new scheme, containing Feature Fusion Module (FFM) that detects small candidates utilizing contextual information and Hard Sample Prototype Learning (HSPL) that mines CMB mimics and generates additional loss term called concentration loss using Convolutional Prototype Learning (CPL). The anatomical localization task does not only tell to which region the CMBs belong but also eliminate some FPs from the detection task by utilizing anatomical information. The results show that the proposed RPN that utilizes the FFM and HSPL outperforms the vanilla RPN and achieves a sensitivity of 94.66% vs. 93.33% and an average number of false positives per subject (FPavg) of 0.86 vs. 14.73. Also, the anatomical localization task further improves the detection performance by reducing the FPavg to 0.56 while maintaining the sensitivity of 94.66%.
Continuous Conversion of CT Kernel using Switchable CycleGAN with AdaIN
Nov 26, 2020



In X-ray computed tomography (CT) reconstruction, different filter kernels are used for different structures being emphasized. Since the raw sinogram data is usually removed after reconstruction, in case there are additional requirements for reconstructed images with other types of kernels that were not previously generated, the patient may need to be scanned again. Accordingly, there exists increasing demand for post-hoc image domain conversion from one kernel to another without sacrificing the image content. In this paper, we propose a novel unsupervised kernel conversion method using cycle-consistent generative adversarial network (cycleGAN) with adaptive instance normalization (AdaIN). In contrast to the existing deep learning approaches for kernel conversion, our method does not require paired dataset for training. In addition, our network can not only translate the images between two different kernels but also generate images on every interpolating path along an optimal transport between the two kernel image domains, enabling synergestic combination of the two filter kernels. Experimental results confirm the advantages of the proposed algorithm.
Unsupervised Deep Learning for MR Angiography with Flexible Temporal Resolution
Mar 29, 2020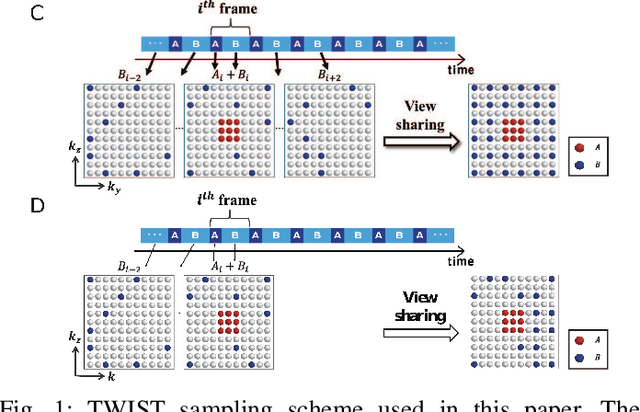
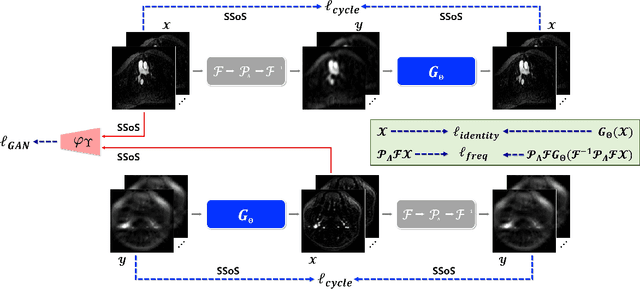
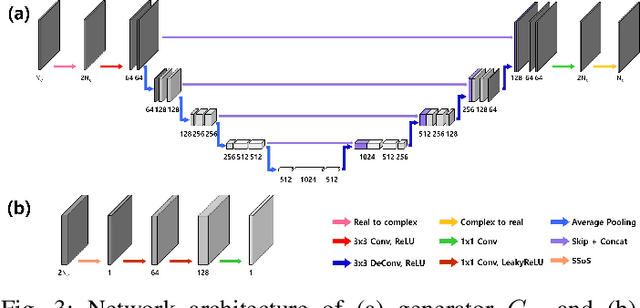
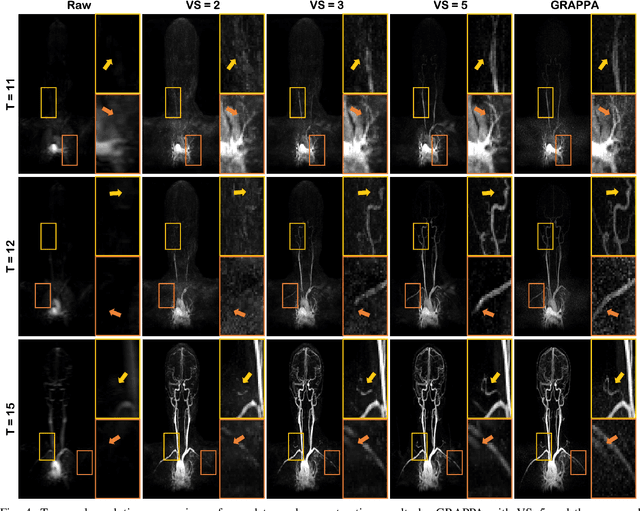
Time-resolved MR angiography (tMRA) has been widely used for dynamic contrast enhanced MRI (DCE-MRI) due to its highly accelerated acquisition. In tMRA, the periphery of the k-space data are sparsely sampled so that neighbouring frames can be merged to construct one temporal frame. However, this view-sharing scheme fundamentally limits the temporal resolution, and it is not possible to change the view-sharing number to achieve different spatio-temporal resolution trade-off. Although many deep learning approaches have been recently proposed for MR reconstruction from sparse samples, the existing approaches usually require matched fully sampled k-space reference data for supervised training, which is not suitable for tMRA. This is because high spatio-temporal resolution ground-truth images are not available for tMRA. To address this problem, here we propose a novel unsupervised deep learning using optimal transport driven cycle-consistent generative adversarial network (cycleGAN). In contrast to the conventional cycleGAN with two pairs of generator and discriminator, the new architecture requires just a single pair of generator and discriminator, which makes the training much simpler and improves the performance. Reconstruction results using in vivo tMRA data set confirm that the proposed method can immediately generate high quality reconstruction results at various choices of view-sharing numbers, allowing us to exploit better trade-off between spatial and temporal resolution in time-resolved MR angiography.
k-Space Deep Learning for Parallel MRI: Application to Time-Resolved MR Angiography
Jun 10, 2018
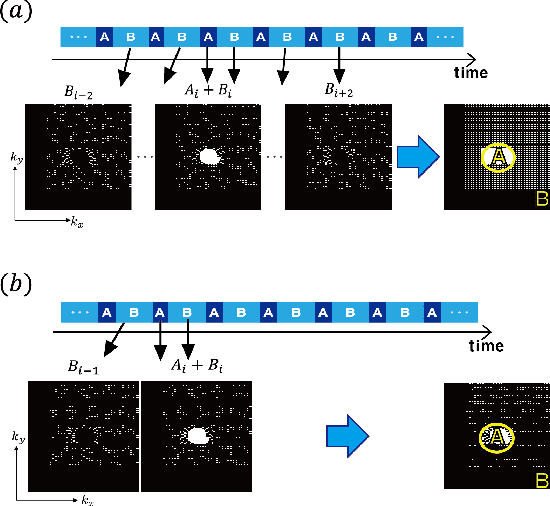
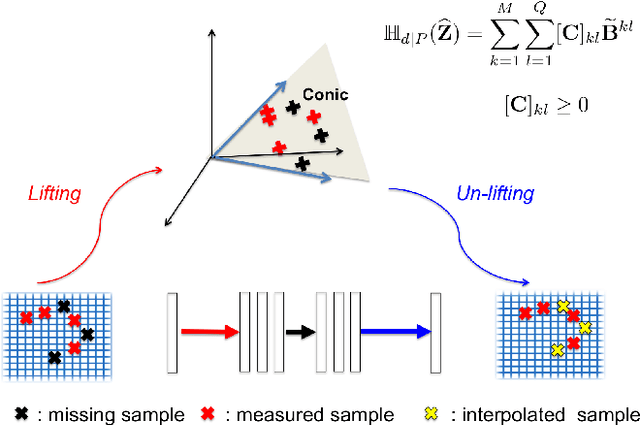
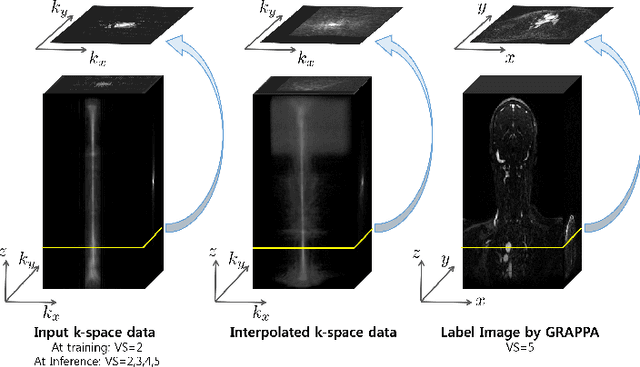
Time-resolved angiography with interleaved stochastic trajectories (TWIST) has been widely used for dynamic contrast enhanced MRI (DCE-MRI). To achieve highly accelerated acquisitions, TWIST combines the periphery of the k-space data from several adjacent frames to reconstruct one temporal frame. However, this view-sharing scheme limits the true temporal resolution of TWIST. Moreover, the k-space sampling patterns have been specially designed for a specific generalized autocalibrating partial parallel acquisition (GRAPPA) factor so that it is not possible to reduce the number of view-sharing once the k-data is acquired. To address these issues, this paper proposes a novel k-space deep learning approach for parallel MRI. In particular, we have designed our neural network so that accurate k-space interpolations are performed simultaneously for multiple coils by exploiting the redundancies along the coils and images. Reconstruction results using in vivo TWIST data set confirm that the proposed method can immediately generate high-quality reconstruction results with various choices of view- sharing, allowing us to exploit the trade-off between spatial and temporal resolution in time-resolved MR angiography.