 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartAttack: Testing the Vulnerability of LLMs to Malicious Prompting in Chart Generation
Jan 19, 2026Multimodal large language models (MLLMs) are increasingly used to automate chart generation from data tables, enabling efficient data analysis and reporting but also introducing new misuse risks. In this work, we introduce ChartAttack, a novel framework for evaluating how MLLMs can be misused to generate misleading charts at scale. ChartAttack injects misleaders into chart designs, aiming to induce incorrect interpretations of the underlying data. Furthermore, we create AttackViz, a chart question-answering (QA) dataset where each (chart specification, QA) pair is labeled with effective misleaders and their induced incorrect answers. Experiments in in-domain and cross-domain settings show that ChartAttack significantly degrades the QA performance of MLLM readers, reducing accuracy by an average of 19.6 points and 14.9 points, respectively. A human study further shows an average 20.2 point drop in accuracy for participants exposed to misleading charts generated by ChartAttack. Our findings highlight an urgent need for robustness and security considerations in the design, evaluation, and deployment of MLLM-based chart generation systems. We make our code and data publicly available.
HyperLoader: Integrating Hypernetwork-Based LoRA and Adapter Layers into Multi-Task Transformers for Sequence Labelling
Jul 02, 2024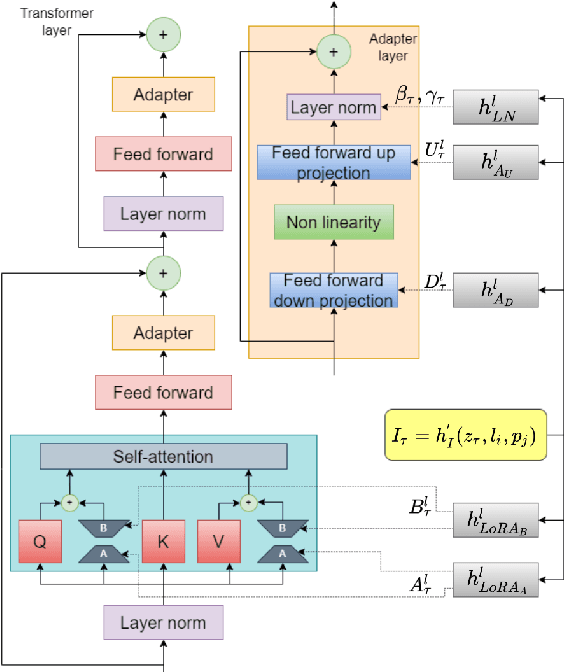

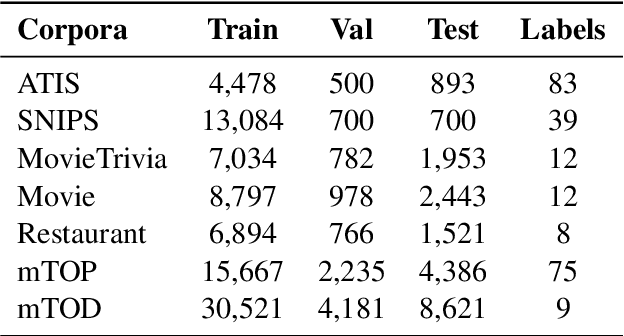
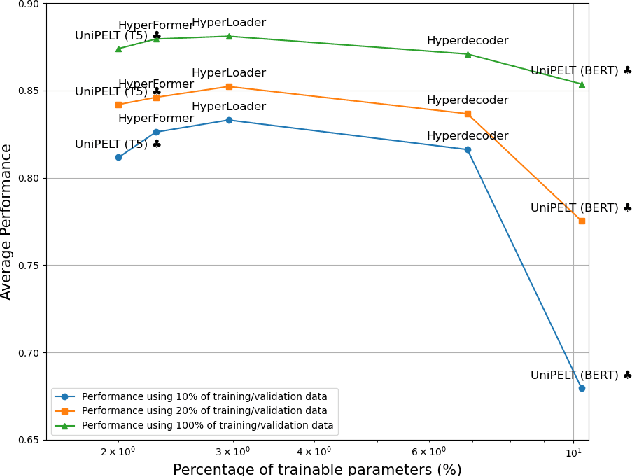
We present HyperLoader, a simple approach that combines different parameter-efficient fine-tuning methods in a multi-task setting. To achieve this goal, our model uses a hypernetwork to generate the weights of these modules based on the task, the transformer layer, and its position within this layer. Our method combines the benefits of multi-task learning by capturing the structure of all tasks while reducing the task interference problem by encapsulating the task-specific knowledge in the generated weights and the benefits of combining different parameter-efficient methods to outperform full-fine tuning. We provide empirical evidence that HyperLoader outperforms previous approaches in most datasets and obtains the best average performance across tasks in high-resource and low-resource scenarios.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.