 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Individual Traits and Language Styles Shape Preferences In Open-ended User-LLM Interaction: A Preliminary Study
Apr 23, 2025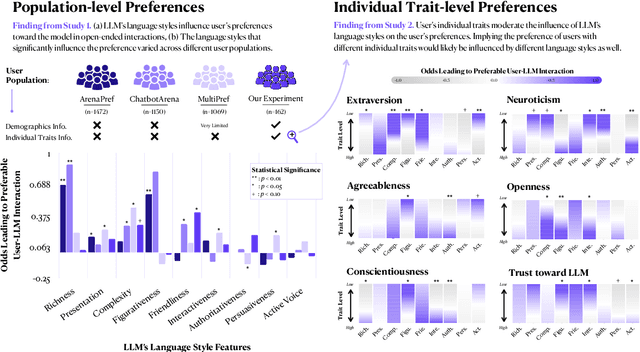
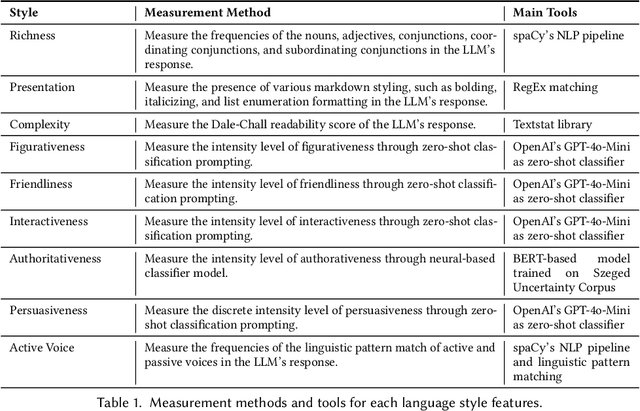
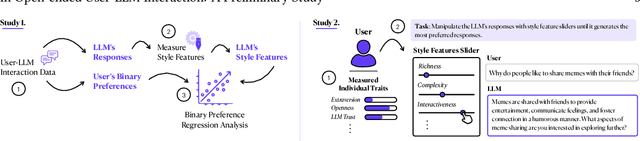

What makes an interaction with the LLM more preferable for the user? While it is intuitive to assume that information accuracy in the LLM's responses would be one of the influential variables, recent studies have found that inaccurate LLM's responses could still be preferable when they are perceived to be more authoritative, certain, well-articulated, or simply verbose. These variables interestingly fall under the broader category of language style, implying that the style in the LLM's responses might meaningfully influence users' preferences. This hypothesized dynamic could have double-edged consequences: enhancing the overall user experience while simultaneously increasing their susceptibility to risks such as LLM's misinformation or hallucinations. In this short paper, we present our preliminary studies in exploring this subject. Through a series of exploratory and experimental user studies, we found that LLM's language style does indeed influence user's preferences, but how and which language styles influence the preference varied across different user populations, and more interestingly, moderated by the user's very own individual traits. As a preliminary work, the findings in our studies should be interpreted with caution, particularly given the limitations in our samples, which still need wider demographic diversity and larger sample sizes. Our future directions will first aim to address these limitations, which would enable a more comprehensive joint effect analysis between the language style, individual traits, and preferences, and further investigate the potential causal relationship between and beyond these variables.
BRIGHTER: BRIdging the Gap in Human-Annotated Textual Emotion Recognition Datasets for 28 Languages
Feb 17, 2025



People worldwide use language in subtle and complex ways to express emotions. While emotion recognition -- an umbrella term for several NLP tasks -- significantly impacts different applications in NLP and other fields, most work in the area is focused on high-resource languages. Therefore, this has led to major disparities in research and proposed solutions, especially for low-resource languages that suffer from the lack of high-quality datasets. In this paper, we present BRIGHTER-- a collection of multilabeled emotion-annotated datasets in 28 different languages. BRIGHTER covers predominantly low-resource languages from Africa, Asia, Eastern Europe, and Latin America, with instances from various domains annotated by fluent speakers. We describe the data collection and annotation processes and the challenges of building these datasets. Then, we report different experimental results for monolingual and crosslingual multi-label emotion identification, as well as intensity-level emotion recognition. We investigate results with and without using LLMs and analyse the large variability in performance across languages and text domains. We show that BRIGHTER datasets are a step towards bridging the gap in text-based emotion recognition and discuss their impact and utility.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Daisy-TTS: Simulating Wider Spectrum of Emotions via Prosody Embedding Decomposition
Feb 22, 2024We often verbally express emotions in a multifaceted manner, they may vary in their intensities and may be expressed not just as a single but as a mixture of emotions. This wide spectrum of emotions is well-studied in the structural model of emotions, which represents variety of emotions as derivative products of primary emotions with varying degrees of intensity. In this paper, we propose an emotional text-to-speech design to simulate a wider spectrum of emotions grounded on the structural model. Our proposed design, Daisy-TTS, incorporates a prosody encoder to learn emotionally-separable prosody embedding as a proxy for emotion. This emotion representation allows the model to simulate: (1) Primary emotions, as learned from the training samples, (2) Secondary emotions, as a mixture of primary emotions, (3) Intensity-level, by scaling the emotion embedding, and (4) Emotions polarity, by negating the emotion embedding. Through a series of perceptual evaluations, Daisy-TTS demonstrated overall higher emotional speech naturalness and emotion perceiveability compared to the baseline.
Nix-TTS: An Incredibly Lightweight End-to-End Text-to-Speech Model via Non End-to-End Distillation
Mar 29, 2022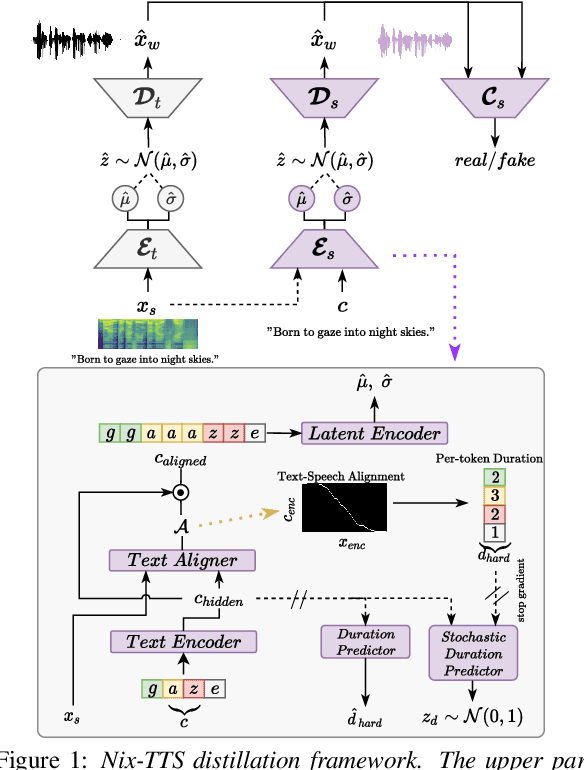
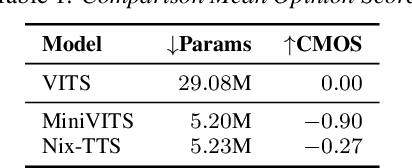
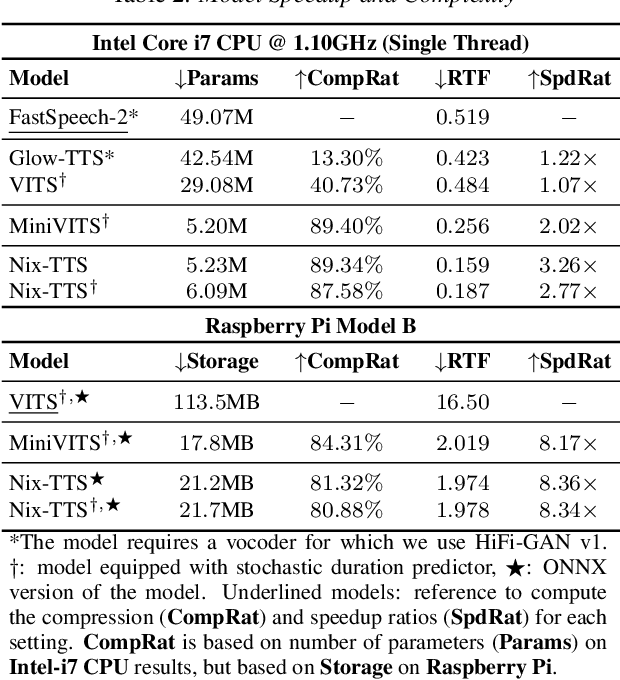
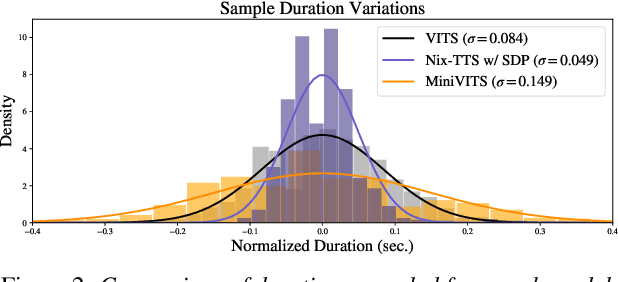
We propose Nix-TTS, a lightweight neural TTS (Text-to-Speech) model achieved by applying knowledge distillation to a powerful yet large-sized generative TTS teacher model. Distilling a TTS model might sound unintuitive due to the generative and disjointed nature of TTS architectures, but pre-trained TTS models can be simplified into encoder and decoder structures, where the former encodes text into some latent representation and the latter decodes the latent into speech data. We devise a framework to distill each component in a non end-to-end fashion. Nix-TTS is end-to-end (vocoder-free) with only 5.23M parameters or up to 82\% reduction of the teacher model, it achieves over 3.26$\times$ and 8.36$\times$ inference speedup on Intel-i7 CPU and Raspberry Pi respectively, and still retains a fair voice naturalness and intelligibility compared to the teacher model. We publicly release Nix-TTS pretrained models and audio samples in English (https://github.com/rendchevi/nix-tts).
Which Student is Best? A Comprehensive Knowledge Distillation Exam for Task-Specific BERT Models
Jan 03, 2022
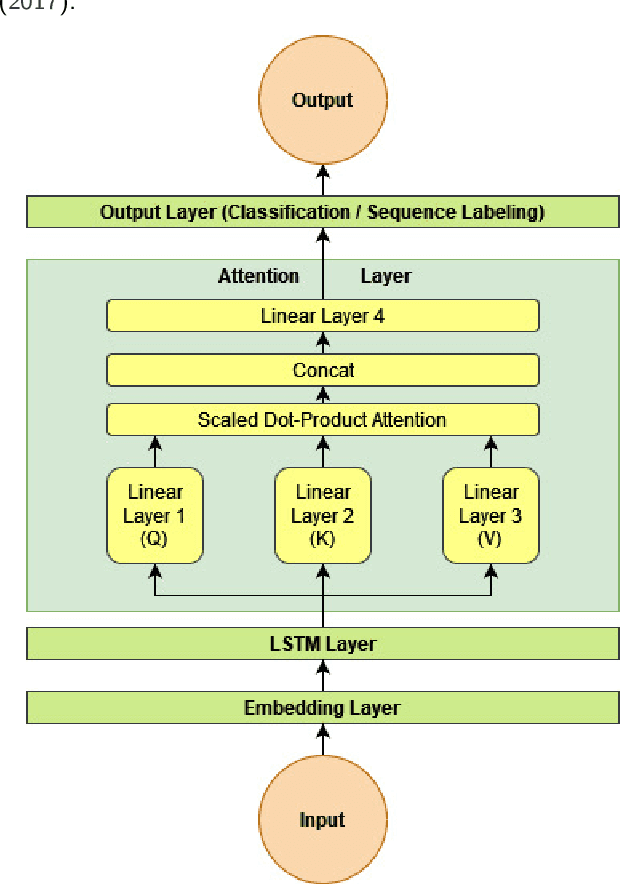
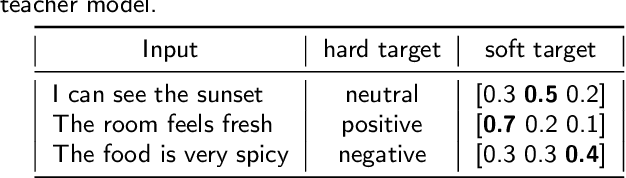
We perform knowledge distillation (KD) benchmark from task-specific BERT-base teacher models to various student models: BiLSTM, CNN, BERT-Tiny, BERT-Mini, and BERT-Small. Our experiment involves 12 datasets grouped in two tasks: text classification and sequence labeling in the Indonesian language. We also compare various aspects of distillations including the usage of word embeddings and unlabeled data augmentation. Our experiments show that, despite the rising popularity of Transformer-based models, using BiLSTM and CNN student models provide the best trade-off between performance and computational resource (CPU, RAM, and storage) compared to pruned BERT models. We further propose some quick wins on performing KD to produce small NLP models via efficient KD training mechanisms involving simple choices of loss functions, word embeddings, and unlabeled data preparation.