 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Student is Best? A Comprehensive Knowledge Distillation Exam for Task-Specific BERT Models
Paper and Code

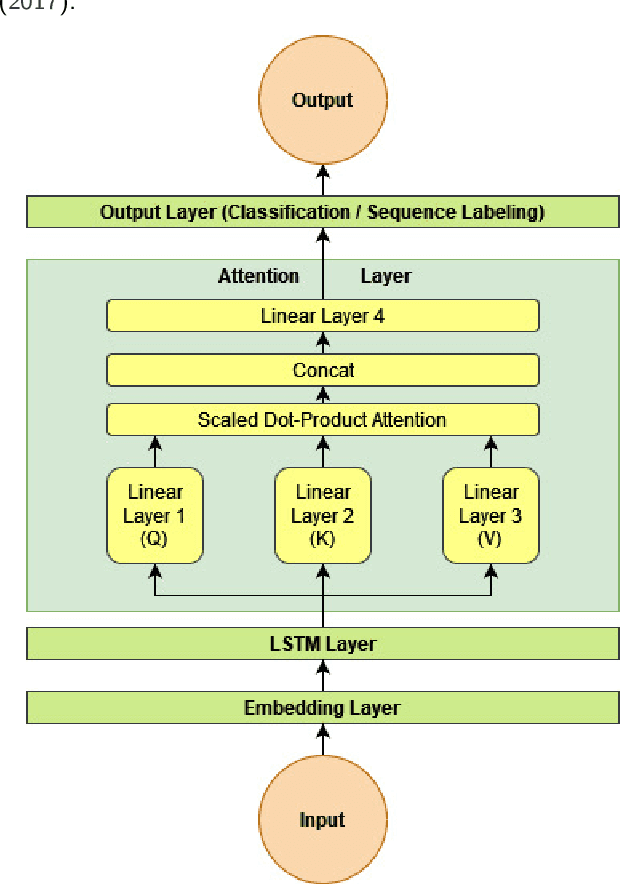
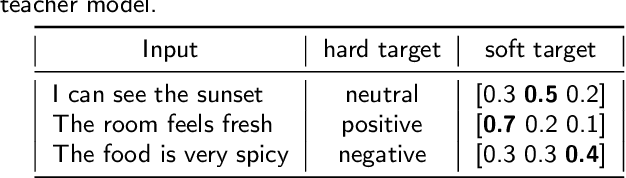
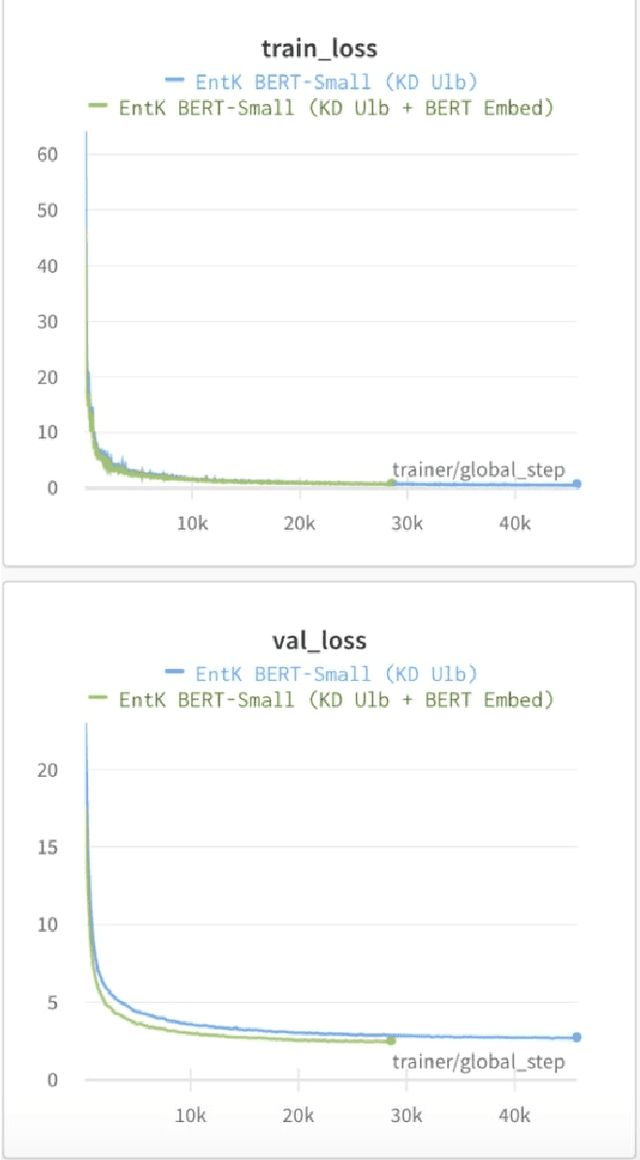
We perform knowledge distillation (KD) benchmark from task-specific BERT-base teacher models to various student models: BiLSTM, CNN, BERT-Tiny, BERT-Mini, and BERT-Small. Our experiment involves 12 datasets grouped in two tasks: text classification and sequence labeling in the Indonesian language. We also compare various aspects of distillations including the usage of word embeddings and unlabeled data augmentation. Our experiments show that, despite the rising popularity of Transformer-based models, using BiLSTM and CNN student models provide the best trade-off between performance and computational resource (CPU, RAM, and storage) compared to pruned BERT models. We further propose some quick wins on performing KD to produce small NLP models via efficient KD training mechanisms involving simple choices of loss functions, word embeddings, and unlabeled data preparation.