 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Machine Translation Datasets for Low-Web Data Languages: A Gendered Lens
Nov 05, 2025As low-resourced languages are increasingly incorporated into NLP research, there is an emphasis on collecting large-scale datasets. But in prioritizing quantity over quality, we risk 1) building language technologies that perform poorly for these languages and 2) producing harmful content that perpetuates societal biases. In this paper, we investigate the quality of Machine Translation (MT) datasets for three low-resourced languages--Afan Oromo, Amharic, and Tigrinya, with a focus on the gender representation in the datasets. Our findings demonstrate that while training data has a large representation of political and religious domain text, benchmark datasets are focused on news, health, and sports. We also found a large skew towards the male gender--in names of persons, the grammatical gender of verbs, and in stereotypical depictions in the datasets. Further, we found harmful and toxic depictions against women, which were more prominent for the language with the largest amount of data, underscoring that quantity does not guarantee quality. We hope that our work inspires further inquiry into the datasets collected for low-resourced languages and prompts early mitigation of harmful content. WARNING: This paper contains discussion of NSFW content that some may find disturbing.
A Capabilities Approach to Studying Bias and Harm in Language Technologies
Nov 06, 2024Mainstream Natural Language Processing (NLP) research has ignored the majority of the world's languages. In moving from excluding the majority of the world's languages to blindly adopting what we make for English, we first risk importing the same harms we have at best mitigated and at least measured for English. However, in evaluating and mitigating harms arising from adopting new technologies into such contexts, we often disregard (1) the actual community needs of Language Technologies, and (2) biases and fairness issues within the context of the communities. In this extended abstract, we consider fairness, bias, and inclusion in Language Technologies through the lens of the Capabilities Approach. The Capabilities Approach centers on what people are capable of achieving, given their intersectional social, political, and economic contexts instead of what resources are (theoretically) available to them. We detail the Capabilities Approach, its relationship to multilingual and multicultural evaluation, and how the framework affords meaningful collaboration with community members in defining and measuring the harms of Language Technologies.
The Zeno's Paradox of `Low-Resource' Languages
Oct 28, 2024



The disparity in the languages commonly studied in Natural Language Processing (NLP) is typically reflected by referring to languages as low vs high-resourced. However, there is limited consensus on what exactly qualifies as a `low-resource language.' To understand how NLP papers define and study `low resource' languages, we qualitatively analyzed 150 papers from the ACL Anthology and popular speech-processing conferences that mention the keyword `low-resource.' Based on our analysis, we show how several interacting axes contribute to `low-resourcedness' of a language and why that makes it difficult to track progress for each individual language. We hope our work (1) elicits explicit definitions of the terminology when it is used in papers and (2) provides grounding for the different axes to consider when connoting a language as low-resource.
Low-resourced Languages and Online Knowledge Repositories: A Need-Finding Study
May 26, 2024
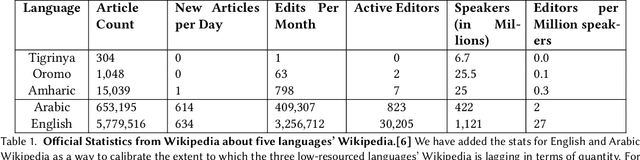


Online Knowledge Repositories (OKRs) like Wikipedia offer communities a way to share and preserve information about themselves and their ways of living. However, for communities with low-resourced languages -- including most African communities -- the quality and volume of content available are often inadequate. One reason for this lack of adequate content could be that many OKRs embody Western ways of knowledge preservation and sharing, requiring many low-resourced language communities to adapt to new interactions. To understand the challenges faced by low-resourced language contributors on the popular OKR Wikipedia, we conducted (1) a thematic analysis of Wikipedia forum discussions and (2) a contextual inquiry study with 14 novice contributors. We focused on three Ethiopian languages: Afan Oromo, Amharic, and Tigrinya. Our analysis revealed several recurring themes; for example, contributors struggle to find resources to corroborate their articles in low-resourced languages, and language technology support, like translation systems and spellcheck, result in several errors that waste contributors' time. We hope our study will support designers in making online knowledge repositories accessible to low-resourced language speakers.
The Less the Merrier? Investigating Language Representation in Multilingual Models
Oct 20, 2023Multilingual Language Models offer a way to incorporate multiple languages in one model and utilize cross-language transfer learning to improve performance for different Natural Language Processing (NLP) tasks. Despite progress in multilingual models, not all languages are supported as well, particularly in low-resource settings. In this work, we investigate the linguistic representation of different languages in multilingual models. We start by asking the question which languages are supported in popular multilingual models and which languages are left behind. Then, for included languages, we look at models' learned representations based on language family and dialect and try to understand how models' learned representations for~(1) seen and~(2) unseen languages vary across different language groups. In addition, we test and analyze performance on downstream tasks such as text generation and Named Entity Recognition. We observe from our experiments that community-centered models -- models that focus on languages of a given family or geographical location and are built by communities who speak them -- perform better at distinguishing between languages in the same family for low-resource languages. Our paper contributes to the literature in understanding multilingual models and their shortcomings and offers insights on potential ways to improve them.
Enhancing Translation for Indigenous Languages: Experiments with Multilingual Models
May 27, 2023


This paper describes CIC NLP's submission to the AmericasNLP 2023 Shared Task on machine translation systems for indigenous languages of the Americas. We present the system descriptions for three methods. We used two multilingual models, namely M2M-100 and mBART50, and one bilingual (one-to-one) -- Helsinki NLP Spanish-English translation model, and experimented with different transfer learning setups. We experimented with 11 languages from America and report the setups we used as well as the results we achieved. Overall, the mBART setup was able to improve upon the baseline for three out of the eleven languages.