 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Privileged Students: On the Value of Initialization in Multilingual Knowledge Distillation
Paper and Code
Jun 24, 2024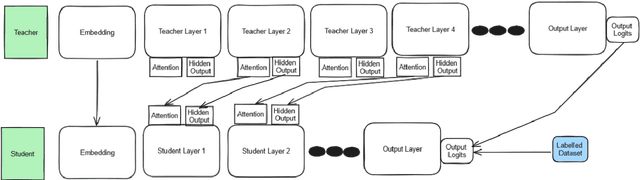
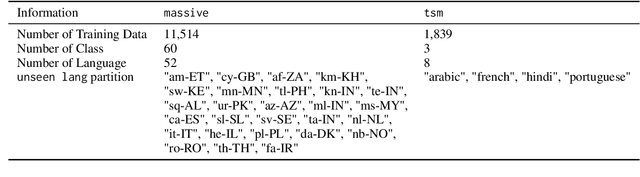
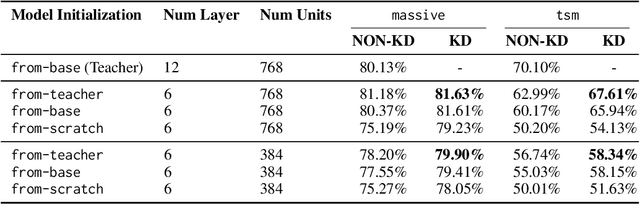
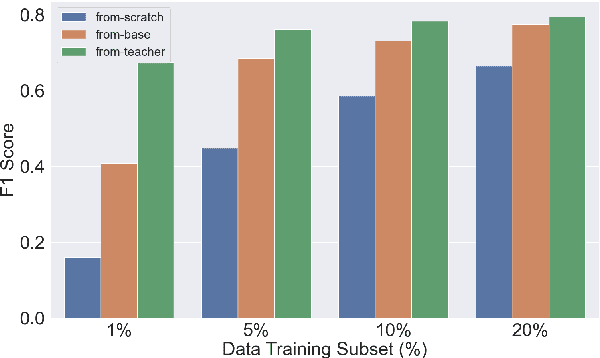
Knowledge distillation (KD) has proven to be a successful strategy to improve the performance of a smaller model in many NLP tasks. However, most of the work in KD only explores monolingual scenarios. In this paper, we investigate the value of KD in multilingual settings. We find the significance of KD and model initialization by analyzing how well the student model acquires multilingual knowledge from the teacher model. Our proposed method emphasizes copying the teacher model's weights directly to the student model to enhance initialization. Our finding shows that model initialization using copy-weight from the fine-tuned teacher contributes the most compared to the distillation process itself across various multilingual settings. Furthermore, we demonstrate that efficient weight initialization preserves multilingual capabilities even in low-resource scenarios.