 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Budget? Don't Flex! Cost Consideration when Planning to Adopt NLP for Your Business
Paper and Code
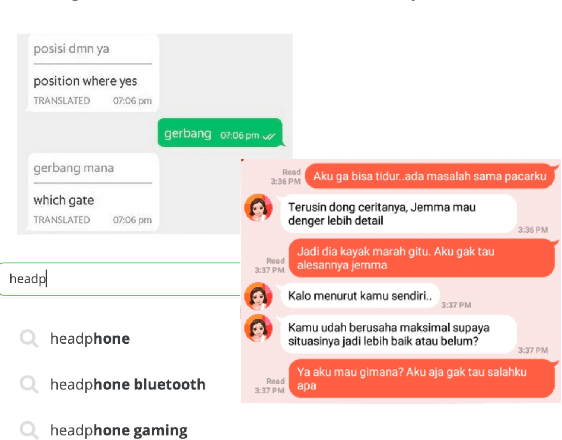
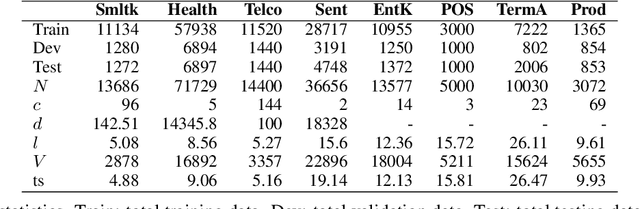
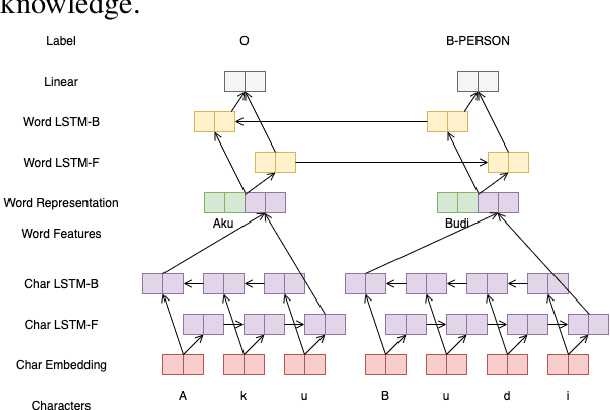
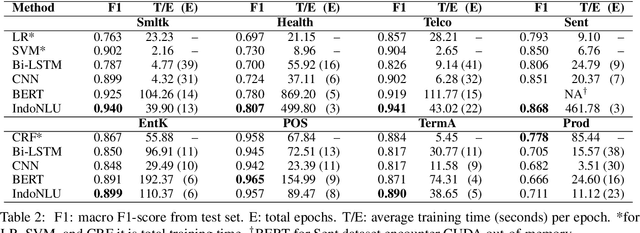
Recent advances in Natural Language Processing (NLP) have largely pushed deep transformer-based models as the go-to state-of-the-art technique without much regard to the production and utilization cost. Companies planning to adopt these methods into their business face difficulties because of the lack of machine and human resources to build them. In this work, we compare both the performance and the cost of classical learning algorithms to the latest ones in common sequence and text labeling tasks. We find that classical models often perform on par with deep neural ones despite the lower cost. We argue that under many circumstances the smaller and lighter models fit better for AI-pivoting businesses and that we call for more research into low-cost models, especially for under-resourced languages.