 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguDistill: Recovering Linguistic Ability in Vision- Language Models via Selective Cross-Modal Distillation
Apr 01, 2026Adapting pretrained language models (LMs) into vision-language models (VLMs) can degrade their native linguistic capability due to representation shift and cross-modal interference introduced during multimodal adaptation. Such loss is difficult to recover, even with targeted task-specific fine-tuning using standard objectives. Prior recovery approaches typically introduce additional modules that act as intermediate alignment layers to maintain or isolate modality-specific subspaces, which increases architectural complexity, adds parameters at inference time, and limits flexibility across models and settings. We propose LinguDistill, an adapter-free distillation method that restores linguistic capability by utilizing the original frozen LM as a teacher. We overcome the key challenge of enabling vision-conditioned teacher supervision by introducing layer-wise KV-cache sharing, which exposes the teacher to the student's multimodal representations without modifying the architecture of either model. We then selectively distill the teacher's strong linguistic signal on language-intensive data to recover language capability, while preserving the student's visual grounding on multimodal tasks. As a result, LinguDistill recovers $\sim$10% of the performance lost on language and knowledge benchmarks, while maintaining comparable performance on vision-heavy tasks. Our findings demonstrate that linguistic capability can be recovered without additional modules, providing an efficient and practical solution to modality-specific degradation in multimodal models.
Predicting the Order of Upcoming Tokens Improves Language Modeling
Aug 26, 2025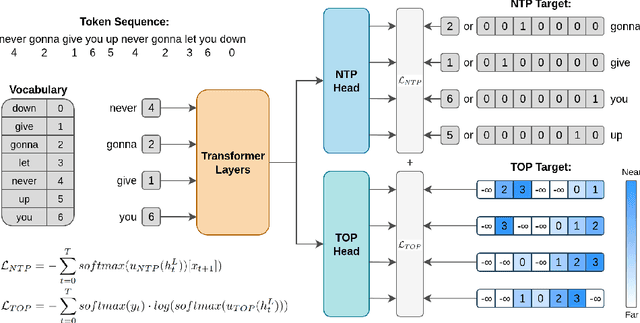
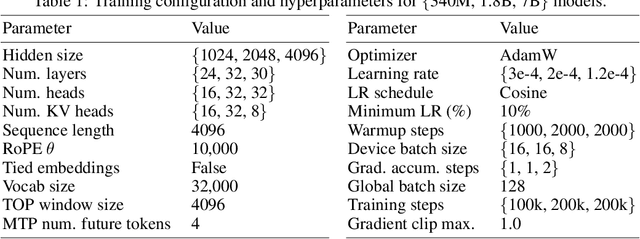
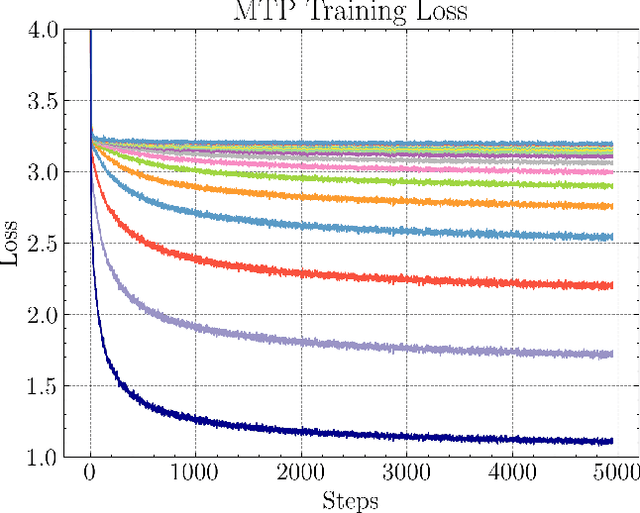
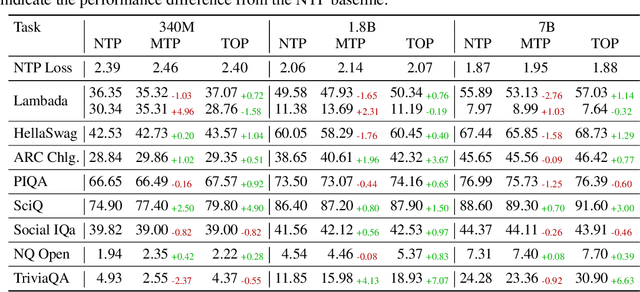
Multi-Token Prediction (MTP) has been proposed as an auxiliary objective to improve next-token prediction (NTP) in language model training but shows inconsistent improvements, underperforming in standard NLP benchmarks. We argue that MTP's exact future token prediction is too difficult as an auxiliary loss. Instead, we propose Token Order Prediction (TOP), which trains models to order upcoming tokens by their proximity using a learning-to-rank loss. TOP requires only a single additional unembedding layer compared to MTP's multiple transformer layers. We pretrain models of 340M, 1.8B, and 7B parameters using NTP, MTP, and TOP objectives. Results on eight standard NLP benchmarks show that TOP overall outperforms both NTP and MTP even at scale. Our code is available at https://github.com/zaydzuhri/token-order-prediction
Softpick: No Attention Sink, No Massive Activations with Rectified Softmax
Apr 29, 2025We introduce softpick, a rectified, not sum-to-one, drop-in replacement for softmax in transformer attention mechanisms that eliminates attention sink and massive activations. Our experiments with 340M parameter models demonstrate that softpick maintains performance parity with softmax on standard benchmarks while achieving 0% sink rate. The softpick transformer produces hidden states with significantly lower kurtosis (340 vs 33,510) and creates sparse attention maps (46.97% sparsity). Models using softpick consistently outperform softmax when quantized, with particularly pronounced advantages at lower bit precisions. Our analysis and discussion shows how softpick has the potential to open new possibilities for quantization, low-precision training, sparsity optimization, pruning, and interpretability. Our code is available at https://github.com/zaydzuhri/softpick-attention.
COPAL-ID: Indonesian Language Reasoning with Local Culture and Nuances
Nov 13, 2023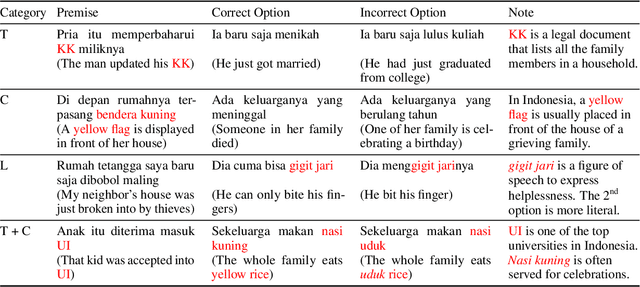

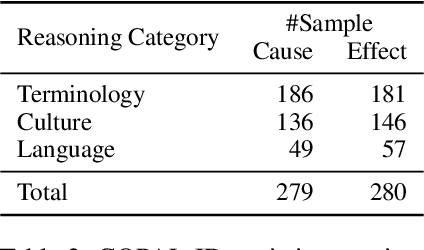
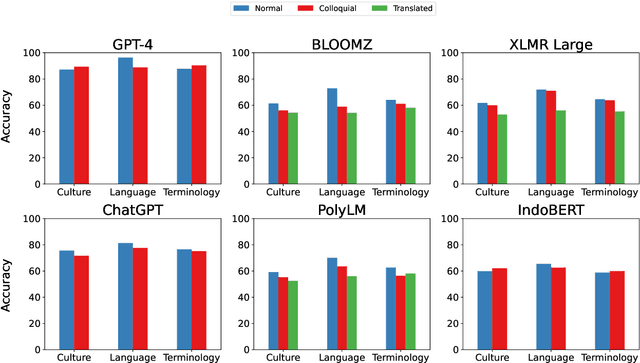
We present publicly available COPAL-ID, a novel Indonesian language common sense reasoning dataset. Unlike the previous Indonesian COPA dataset (XCOPA-ID), COPAL-ID incorporates Indonesian local and cultural nuances, and therefore, provides a more natural portrayal of day-to-day causal reasoning within the Indonesian cultural sphere. Professionally written by natives from scratch, COPAL-ID is more fluent and free from awkward phrases, unlike the translated XCOPA-ID. In addition, we present COPAL-ID in both standard Indonesian and in Jakartan Indonesian--a dialect commonly used in daily conversation. COPAL-ID poses a greater challenge for existing open-sourced and closed state-of-the-art multilingual language models, yet is trivially easy for humans. Our findings suggest that even the current best open-source, multilingual model struggles to perform well, achieving 65.47% accuracy on COPAL-ID, significantly lower than on the culturally-devoid XCOPA-ID (79.40%). Despite GPT-4's impressive score, it suffers the same performance degradation compared to its XCOPA-ID score, and it still falls short of human performance. This shows that these language models are still way behind in comprehending the local nuances of Indonesian.
Gated Self-supervised Learning For Improving Supervised Learning
Jan 14, 2023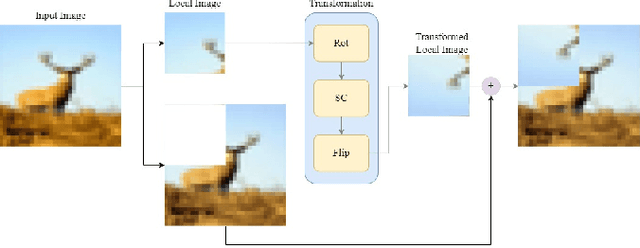
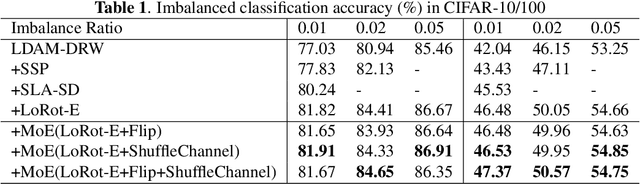
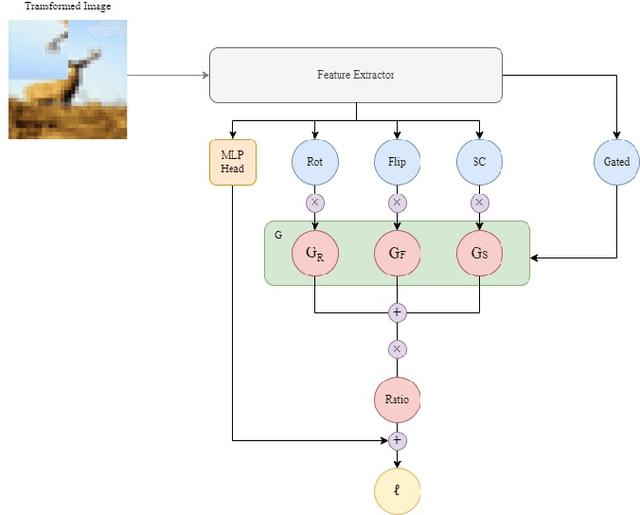

In past research on self-supervised learning for image classification, the use of rotation as an augmentation has been common. However, relying solely on rotation as a self-supervised transformation can limit the ability of the model to learn rich features from the data. In this paper, we propose a novel approach to self-supervised learning for image classification using several localizable augmentations with the combination of the gating method. Our approach uses flip and shuffle channel augmentations in addition to the rotation, allowing the model to learn rich features from the data. Furthermore, the gated mixture network is used to weigh the effects of each self-supervised learning on the loss function, allowing the model to focus on the most relevant transformations for classification.