 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Self-Supervised Learning
Jul 27, 2023
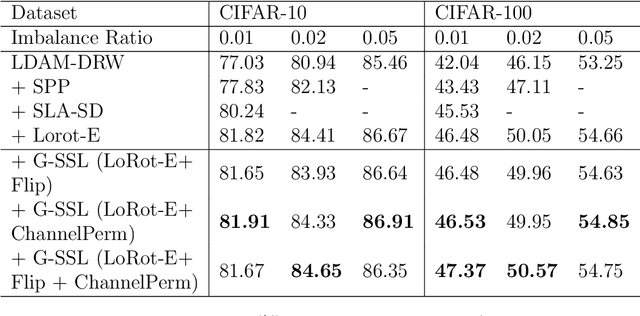
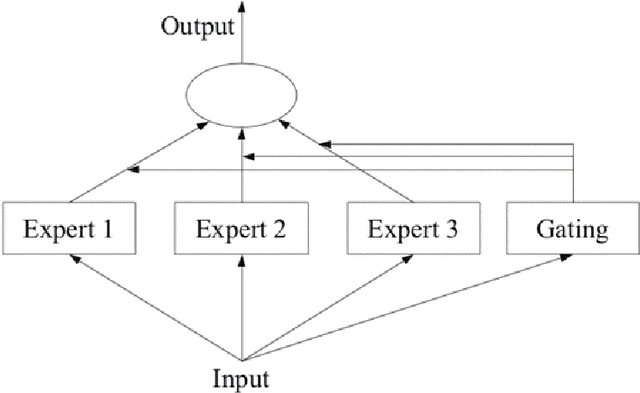
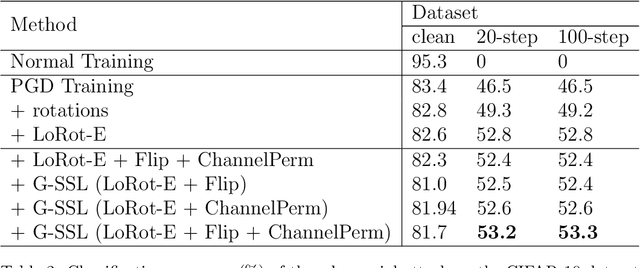
Self-supervised learning is popular method because of its ability to learn features in images without using its labels and is able to overcome limited labeled datasets used in supervised learning. Self-supervised learning works by using a pretext task which will be trained on the model before being applied to a specific task. There are some examples of pretext tasks used in self-supervised learning in the field of image recognition, namely rotation prediction, solving jigsaw puzzles, and predicting relative positions on image. Previous studies have only used one type of transformation as a pretext task. This raises the question of how it affects if more than one pretext task is used and to use a gating network to combine all pretext tasks. Therefore, we propose the Gated Self-Supervised Learning method to improve image classification which use more than one transformation as pretext task and uses the Mixture of Expert architecture as a gating network in combining each pretext task so that the model automatically can study and focus more on the most useful augmentations for classification. We test performance of the proposed method in several scenarios, namely CIFAR imbalance dataset classification, adversarial perturbations, Tiny-Imagenet dataset classification, and semi-supervised learning. Moreover, there are Grad-CAM and T-SNE analysis that are used to see the proposed method for identifying important features that influence image classification and representing data for each class and separating different classes properly. Our code is in https://github.com/aristorenaldo/G-SSL
Gated Self-supervised Learning For Improving Supervised Learning
Jan 14, 2023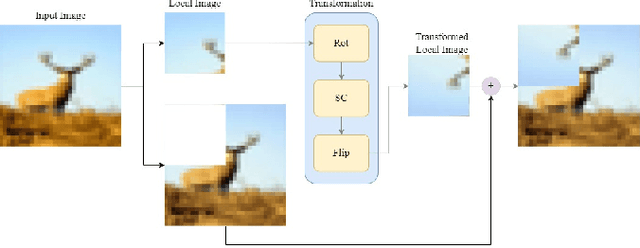
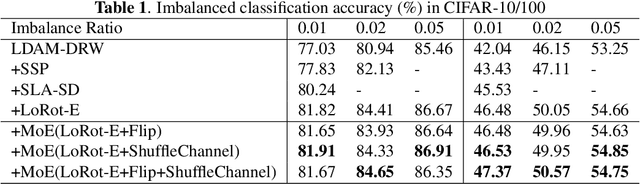
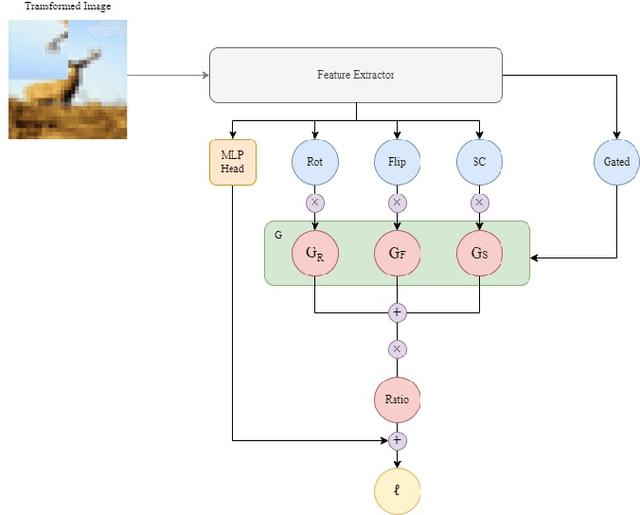

In past research on self-supervised learning for image classification, the use of rotation as an augmentation has been common. However, relying solely on rotation as a self-supervised transformation can limit the ability of the model to learn rich features from the data. In this paper, we propose a novel approach to self-supervised learning for image classification using several localizable augmentations with the combination of the gating method. Our approach uses flip and shuffle channel augmentations in addition to the rotation, allowing the model to learn rich features from the data. Furthermore, the gated mixture network is used to weigh the effects of each self-supervised learning on the loss function, allowing the model to focus on the most relevant transformations for classification.